基于佬友的 ![]() 开源项目:基于 Qwen-VL 模型的智能图片识别工具,支持数学公式 OCR! - 开发调优 - LINUX DO 的帖子,简单的搓了个openwebui的pipe函数,可以实现直接图片上传识别文本的效果
开源项目:基于 Qwen-VL 模型的智能图片识别工具,支持数学公式 OCR! - 开发调优 - LINUX DO 的帖子,简单的搓了个openwebui的pipe函数,可以实现直接图片上传识别文本的效果
1.1.0 版本更新,支持最新的api转发(2025.2.10 更新)
woker代码仓库
ocr-based-qwen/worker.js at main · Cunninger/ocr-based-qwen
强烈建议自己在cloudflare上跑一个worker,用这个worker的原始网址(也就是.workers.dev结尾的网址)来作为这个pipe函数的请求网站,因为这个测试网站经常连不上
"""
title: QwenLM OCR
author: konbakuyomu
description: 本项目是对 QwenLM 的 OCR 功能进行逆向工程的实现。通过调用 QwenLM 的 API,你可以从图片中提取文字内容
version: 1.1.0
licence: MIT
"""
from pydantic import BaseModel, Field
import aiohttp
import asyncio
from typing import Callable, Awaitable, Any, Optional
import base64
import re
import os
class Pipe:
class Valves(BaseModel):
# 在这里定义可自定义的 API Base URL
base_api_url: str = Field(
default="https://test-qwen-cor.aughumes8.workers.dev",
description="后端 API 的基础 URL,可根据需要自定义。",
)
# 其他可选的鉴权参数,示例中是 token 或 cookie
ocr_api_token: str = Field(
default="", description="OCR API 的 Token(或 Cookie 值)"
)
def __init__(self):
self.valves = self.Valves()
async def pipe(
self,
body: dict,
__event_emitter__: Callable[[Any], Awaitable[None]],
user: Optional[dict] = None,
) -> str:
"""
针对 3 种识别方式的处理逻辑:
1) 本地文件上传 -> 返回imageId -> 再请求 /recognize
2) 直接通过 URL
3) 直接通过 Base64
"""
# 1. 如果检查到本地文件,就先上传 -> 再识别
image_file_path = self._extract_file_path(body)
if image_file_path and os.path.exists(image_file_path):
method = "上传文件"
await __event_emitter__(
{
"type": "status",
"data": {
"description": f"检测到本地文件,正在以 {method} 方式进行识别,请稍候...",
"done": False,
},
}
)
try:
# 构建完整的上传 URL
upload_url = f"{self.valves.base_api_url}/proxy/upload"
upload_headers = {"x-custom-cookie": self.valves.ocr_api_token or "api"}
form_data = aiohttp.FormData()
form_data.add_field(
name="file",
value=open(image_file_path, "rb"),
filename=os.path.basename(image_file_path),
content_type="application/octet-stream",
)
async with aiohttp.ClientSession() as session:
async with session.post(
upload_url, headers=upload_headers, data=form_data
) as resp:
resp.raise_for_status()
upload_result = await resp.json()
# 2) 从返回中获取 imageId,然后调用 /recognize
image_id = upload_result.get("id")
if not image_id:
return "上传成功,但未获取到有效 id,请检查后端返回。"
# 构建完整的识别 URL
recognize_url = f"{self.valves.base_api_url}/recognize"
recognize_headers = {
"x-custom-cookie": self.valves.ocr_api_token or "api",
"Content-Type": "application/json",
}
payload = {"imageId": image_id}
async with aiohttp.ClientSession() as session:
async with session.post(
recognize_url, headers=recognize_headers, json=payload
) as resp:
resp.raise_for_status()
ocr_result = await resp.json()
# 通知完成
await __event_emitter__(
{
"type": "status",
"data": {
"description": "✅ 图片识别完成!",
"done": True,
},
}
)
return self._format_ocr_result(ocr_result)
except Exception as e:
await __event_emitter__(
{
"type": "status",
"data": {
"description": f"❌ 文件上传或识别失败:{e}",
"done": True,
},
}
)
return f"文件上传或识别失败:{e}"
else:
# 2. 如果没有本地文件,则尝试 URL / Base64 两种方式
user_provided_image_url = self._extract_user_input_image_url(body)
if user_provided_image_url:
method = "URL (用户输入)"
ocr_api_url = f"{self.valves.base_api_url}/api/recognize/url"
payload = {"imageUrl": user_provided_image_url}
else:
image_url = self._extract_image_url(body)
base64_image = self._extract_base64_image(body)
if image_url:
method = "URL"
ocr_api_url = f"{self.valves.base_api_url}/api/recognize/url"
payload = {"imageUrl": image_url}
elif base64_image:
method = "Base64"
ocr_api_url = f"{self.valves.base_api_url}/api/recognize/base64"
payload = {"base64Image": base64_image}
else:
return "未提供有效的图片(本地文件 / URL / Base64)。"
# 通知开始识别
await __event_emitter__(
{
"type": "status",
"data": {
"description": f"正在以 {method} 方式识别图片中的文字,请稍候...",
"done": False,
},
}
)
# 发起请求
try:
headers = {
"Content-Type": "application/json",
"x-custom-cookie": self.valves.ocr_api_token or "api",
}
async with aiohttp.ClientSession() as session:
async with session.post(
ocr_api_url, headers=headers, json=payload
) as response:
response.raise_for_status()
ocr_result = await response.json()
# 处理完成
await __event_emitter__(
{
"type": "status",
"data": {
"description": "✅ 图片识别完成!",
"done": True,
},
}
)
return self._format_ocr_result(ocr_result)
except Exception as e:
# 发生错误
await __event_emitter__(
{
"type": "status",
"data": {
"description": f"❌ OCR API 请求失败:{e}",
"done": True,
},
}
)
return f"OCR API 请求失败:{e}"
#
# 以下为辅助方法,不涉及请求主体的改变
#
def _extract_user_input_image_url(self, body: dict) -> Optional[str]:
"""从用户消息文本中提取可能的图片URL。"""
messages = body.get("messages", [])
if not messages:
return None
last_message = messages[-1]
content = last_message.get("content", "")
if isinstance(content, str):
urls = self._find_image_urls_in_text(content)
if urls:
return urls[0]
return None
def _find_image_urls_in_text(self, text: str) -> list:
"""用正则在文本中查找常见扩展名的图片URL。"""
image_url_pattern = re.compile(
r"(https?://[^\s]+?\.(?:png|jpg|jpeg|gif|bmp|tiff|webp))", re.IGNORECASE
)
return image_url_pattern.findall(text)
def _extract_image_url(self, body: dict) -> Optional[str]:
"""从 body 里解析图片 URL(若消息结构是 list)。"""
messages = body.get("messages", [])
if messages:
last_message = messages[-1]
if isinstance(last_message.get("content"), list):
for content_item in last_message["content"]:
if content_item.get("type") == "image_url":
return content_item["image_url"].get("url")
return None
def _extract_base64_image(self, body: dict) -> Optional[str]:
"""从 body 中提取 base64 编码的图片。"""
messages = body.get("messages", [])
if messages:
last_message = messages[-1]
content = last_message.get("content")
if isinstance(content, str):
if content.startswith("data:image") and "base64," in content:
base64_data = content.split("base64,")[-1]
if self._is_base64(base64_data):
return base64_data
elif self._is_base64(content):
return content
return None
def _is_base64(self, s: str) -> bool:
"""判断字符串是否为有效的 Base64 编码。"""
try:
if not re.fullmatch(r"[A-Za-z0-9+/]+={0,2}", s):
return False
base64.b64decode(s, validate=True)
return True
except Exception:
return False
def _extract_file_path(self, body: dict) -> Optional[str]:
"""从 body 中提取本地文件路径的示例方法。"""
messages = body.get("messages", [])
if messages:
last_message = messages[-1]
file_path = last_message.get("file_path")
if file_path and os.path.isfile(file_path):
return file_path
return None
def _format_ocr_result(self, ocr_result: dict) -> str:
"""根据 API 返回内容,格式化识别结果。"""
if ocr_result.get("success"):
return f"识别结果:\n{ocr_result.get('result', '未识别到文本。')}"
else:
return f"OCR API 返回错误:{ocr_result.get('error', '未知错误')}"
效果如下图所示

这里要写个1是因为不填东西发不出去…
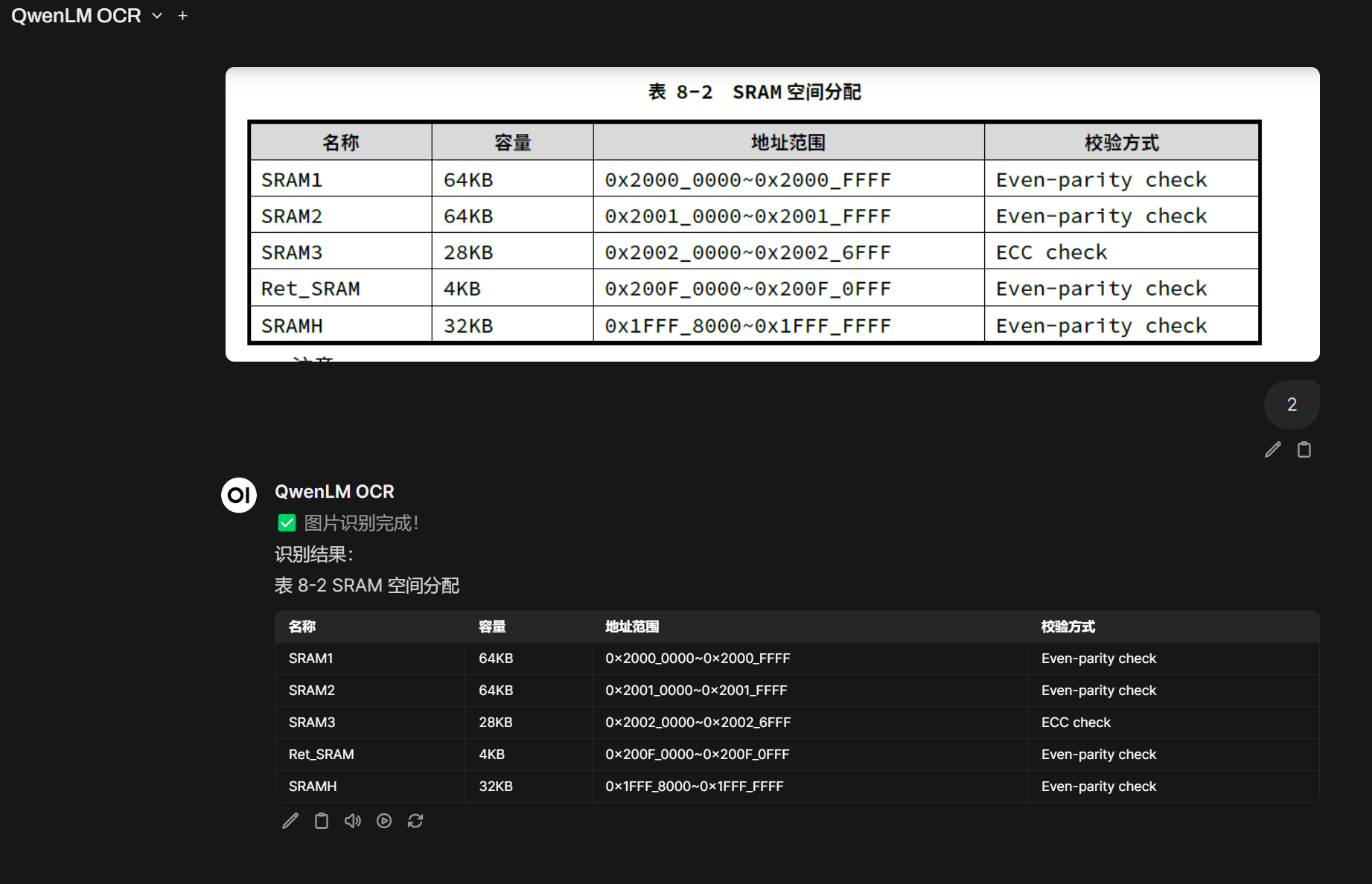
表格的识别效果也很nice!
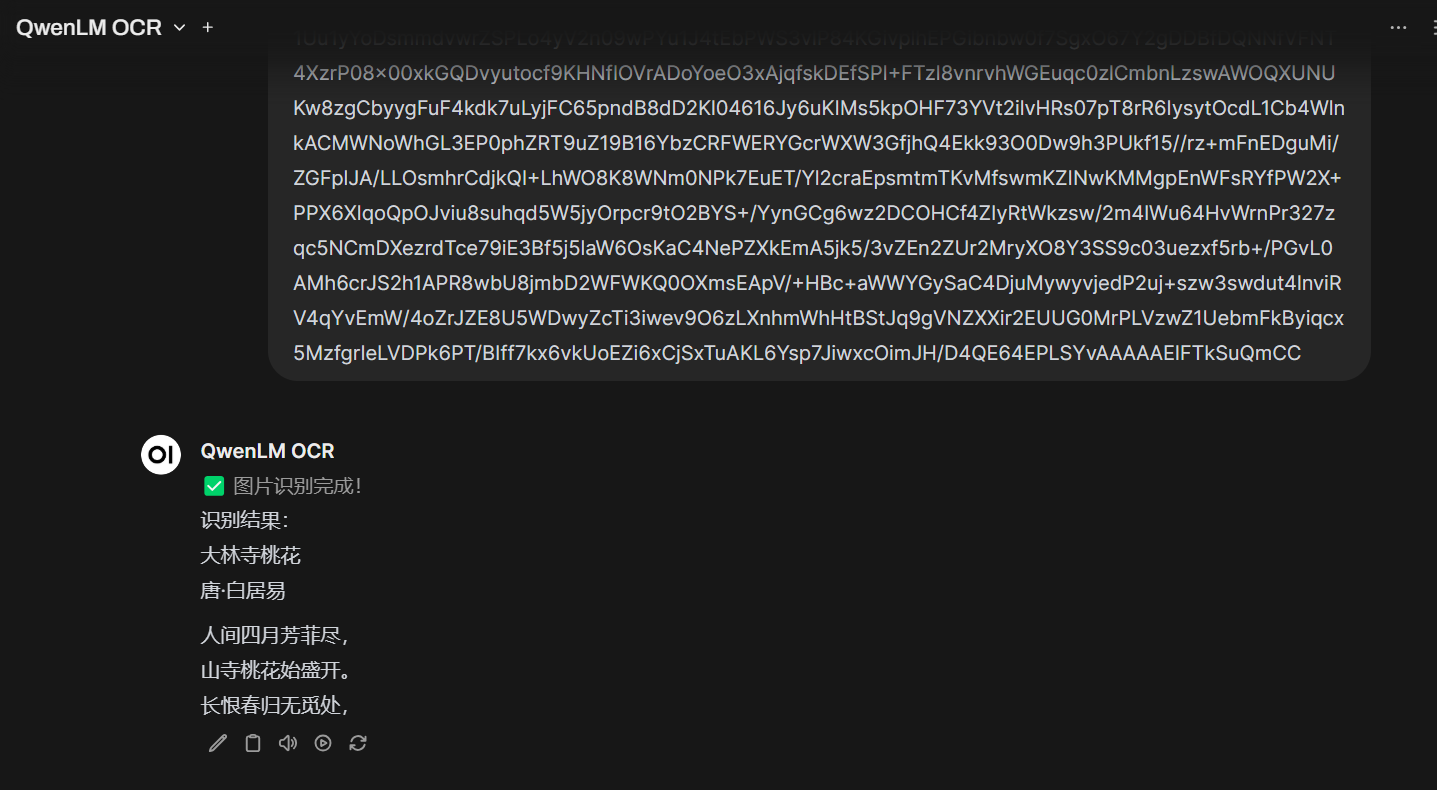
同时支持直接输入base64格式识别
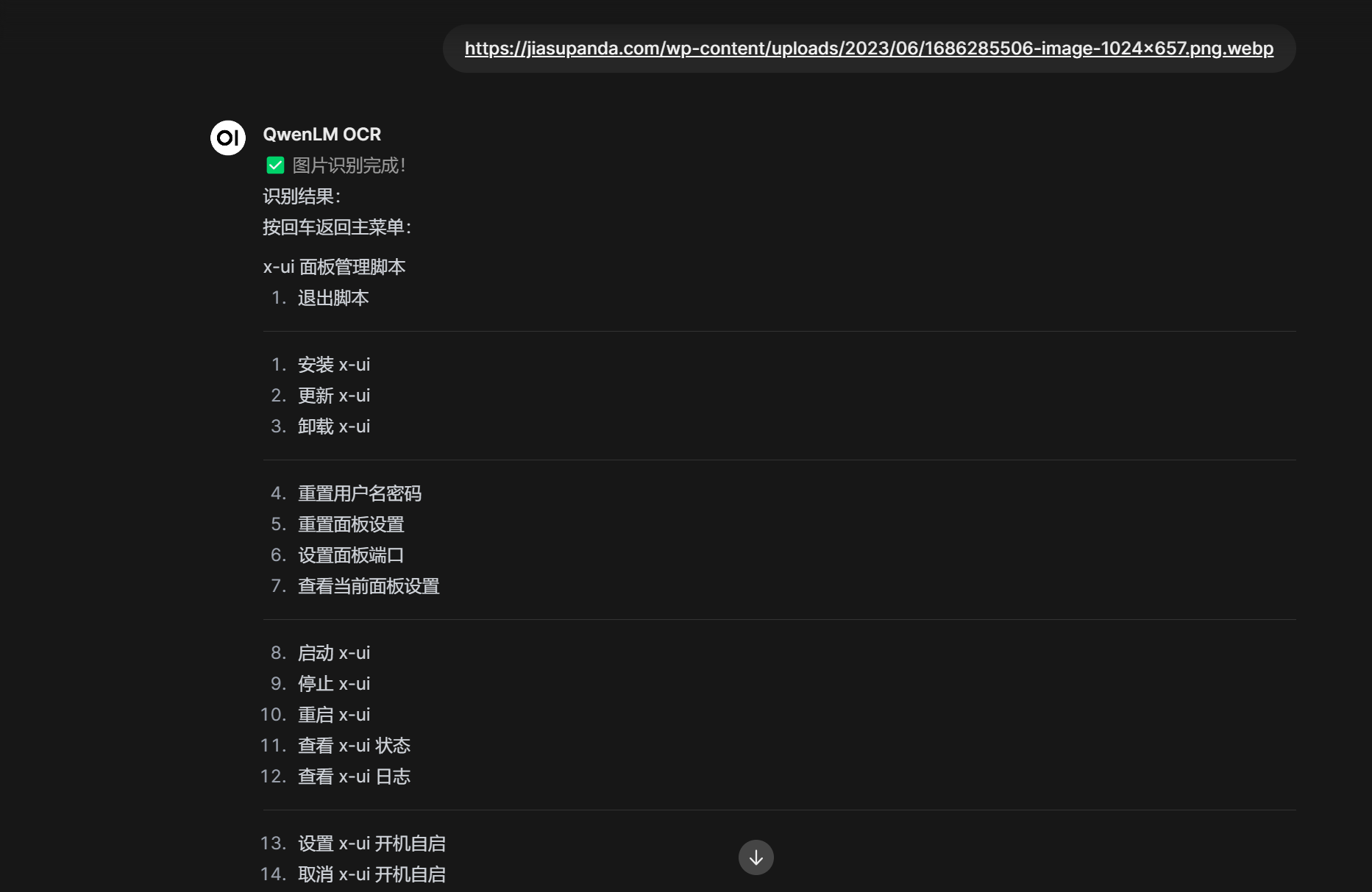
也支持直接输入图片url链接的方式识别
小tips
只需要在函数值输入token就可以使用,token可以使用 jiangly 大佬提供的体验token
cna=LI8HIAirQyACAWrg3cNOjH8F; _gcl_au=1.1.1200556497.1736728490; xlly_s=1; acw_tc=c2b96feb4d2929a1649ea96dc00590956477696933f61783d23e6c95429ecf74; x-ap=ap-southeast-1; token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpZCI6IjUzZTk0Nzg4LWMwM2QtNDY4Mi05OTNhLWE0ZDNjNGUyZDY0OSIsImV4cCI6MTc0MTE0ODM0MX0.-2hF4l1iJf8r5U6UzoXyc-TFqx0i5luWmtJk0kk8T5o; ssxmod_itna=Yq+hqIxjx=AKi7eitD8IDCWBfbxxl4BtGRDeq7tDRDFqApxDHmLWxoDUxxu2hE80DD0ADnG3BUxGN4tDxiNDAg40iDC4mL37ezTxthtQQhgDCTYCu2rpTCGGE7P3rnTE0M25BA6w3KxxGLDY=DCqhxl4eD4R3Dt4DIDAYDDxDWFeGIDGYD7hb=ymbDm44aYxGy3nbDA3TDbhb5xitYDDUAKeG2igbhDDNheFY49GG7yC0OorHDAqh==GbDjqPD/RxLP+bkXtkh/CTA=BapCeaWxBQD7we3xYE4c=IdqZawfiEwDELx0De/iGKGxdYmPlvzYKGlpVGGoWDqjqQlXnlvnnPDDc=Y9=buiDrP3KYtvS85lmHQDxPoGb0rz0THimDgri0i8B0=nxNCDtYDb30eDBeIG4/g8BvDD; ssxmod_itna2=Yq+hqIxjx=AKi7eitD8IDCWBfbxxl4BtGRDeq7tDRDFqApxDHmLWxoDUxxu2hE80DD0ADnG3BDxDfk7K7e5xDLiARWCTe9A4D/9o1+WeqlSGSWe4dTPhBUq4kzjyE41MPvWM=BtDwWHWiQ4B+GVChGZYlDDoA6gCj2VGnQeqqxeBSiqeT69Cg2Q6qrEGqv/DTQR8MRo3m3E7Gd7mf42Re2lYpNic=beSRp3tCDgWT7khOXGqf2lBpre5BtExlRw6cUwWwDxNSFUl/8Un/RGZz8/jLk2t1XZC79Eb7iRTPTMPn5MTHW2fs1DlsH0z9RxCLW1Rdb2QFhd9biugr+2aTW1oeYAbtORQNMW43+m2Gcb=TuFtQGqhiTqrNfdwSOe8WHSWTr7cRaw833Yzw31d4iN+Q9OO7izUj1uSdYrh4dIvx5CwYD45Vji4EbkiaNQQGbt1hDa8Ymmda3r3lThChY8Nm2IscznS+mS43izuLzUYN94syC3tQi03=u3Q6az931moHSOLY3OFPKoMjqMUDbtebxw=rT2rBAv08uRkWHzFtGp2lUSSb3z41pTZcx/8NB3jD+XnIpLFEw8bv4r58wRLLwubFTQ9cPDv+9k36tvoCYXlso4qGA44E3y737YNBDmUct2Iahxq76iTrlGotG1NBBN=Tx4hkA2Zp887gfc4Tp8V1wGCf49XeA=0Xu3uIKqYQADh0ABmqlQ4w=YVlDPjO9KH2xaG3C8ID5DeY41AxMxR2NIGhSD+5q0UQGx0Ue4dAi0DwbY+f7n1Gwz014LQ2DY+42xI2zG5TmhfDtXehC40aWxfDi0xIGNQ3gGkYeu2fAfADwY31mkAooDxD; SERVERID=da7472215188c88fe194f138f1242089|1738557149|1738556339; SERVERCORSID=da7472215188c88fe194f138f1242089|1738557149|1738556339; isg=BBcXHLltPM7zv7hi-FnT0HW6pothXOu-LIccEmlG4eZGmDrabS7mDq_--ziGPsM2; tfstk=gxYniE986HSQfEpYpd7Icypow5otjW_5cLUReaBrbOW6JLnCehbygKjRyBdPr4XN8gtde9BlrQ9m6x3xkBOCPgkxHqIXCrTVlurzY8QNb_blTz_06LRCPaktd3lv5B9qU3M64alG7_fz8aWFTPlGZsXPz9SzQl5VQT7yU9SaQ617YJzUzRlGNOWPzaJP7jQ8r9CV1FkgVOPK4CrD_6jh3BWH9KLadGrBiO4zzFjfxtuAIzzyS6Ot3kbuo0B2c9IACduT-aANZKfDKRkGzCYBoG8ECzvDIn7G1hMuqtxy9ntPjXueswXhmFI0Zk7H4pTlAHVSGC7eCn6fYcM1seLAqtsgQvR9s9SDqpH_z9KD_djvWRUA7I-GSgozbo5IVz1ZwFr7VM51stK4FEPS3FZLvfcg0MIF16r-sfq7VM51sthisoJlY11U2
十分感谢原作者 jiangly 大佬

{kind=link}