JidaDiao
(Xiaojian Ji)
1
组了一套个人的炼丹服务器玩,但是有很多地方不是很明白,配置如下:
服务器配置
- 主机:超微 7048 准系统
- CPU:Intel Xeon E5-2682 V4 * 2(32 核 64 线程,基础频率 2.5GHz)
- 内存:128GB DDR4 2400MHz 四通道
- 存储:1TB 闪迪固态硬盘
- 电源:2000W 单电源
- 显卡:双 Nvidia RTX 3090,支持 NVLink
- 操作系统:Ubuntu 22.04.5 LTS
运行情况
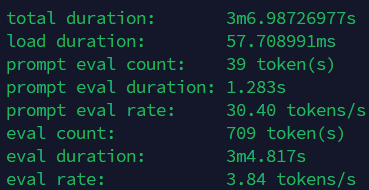
下面是我用ollama跑qwen2.5:74b的结果:
eval rate只有可怜的3.84 tokens/s
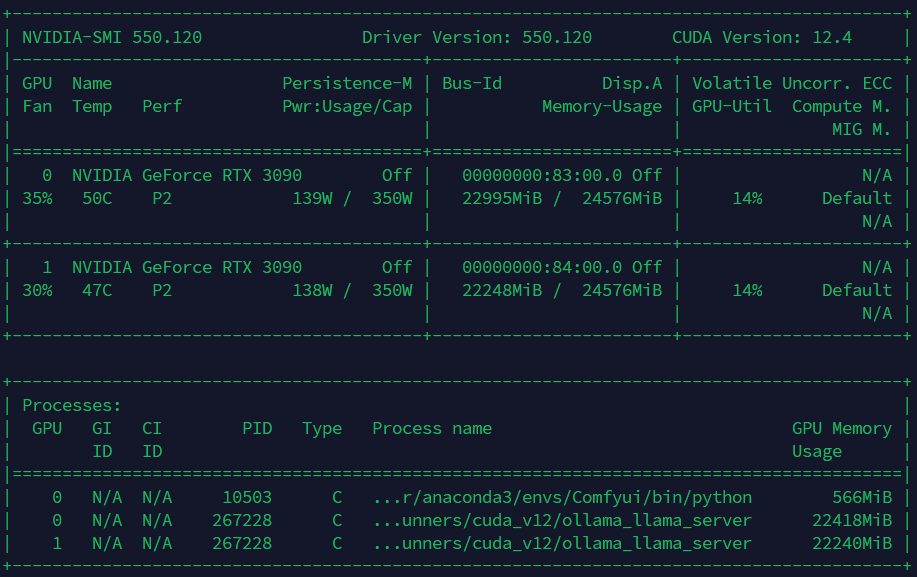
下面是显卡的使用情况:
两张显卡的
显存几乎都已经吃满,但是显卡使用率仅为
14%,这是不是有点过低了?不知道这里是不是哪里瓶颈了,还是说这套方案确实就是这个水平。
11 个赞
qwen2.5:74b?
显卡使用率在不推理的时候0%都正常,建议使用watch指令监控一下峰值占用率能不能到100%。
看一下是不是显存不够模型有部分加载在内存里了,低的不正常
JidaDiao
(Xiaojian Ji)
7
72你这显存必然不够,不量化需要约160GB显存呢。
JidaDiao
(Xiaojian Ji)
10
好像ollama直接拉下来的模型默认就是使用Q4_K_M量化的
ZoroAster
(llliiilll)
11
问了一下deepseek,他说是FP16的30%-40%,应该还是不太够。
72b的话,这个成绩应该不是可怜
瓶颈你自己都知道呀,再怎么量化差距也太大了,玩32b试试咯
想折腾的话,改个散热玩玩
1 个赞
JidaDiao
(Xiaojian Ji)
15
话说我32b的模型又全部只放到一张卡上,另一张只有一点点。难道没有介于30+到70+之间的模型吗?
Forever
(Lightyear Forever)
16
我知道Linux 有个选项可以调多大程度依赖swap,是不是对于显卡依赖和显存依赖也有对应参数啊
JidaDiao
(Xiaojian Ji)
18
那大伙们我这套还有没有升级空间呀?咋升级?整个准系统只花了3000+,显卡却花了1.3w,会不会有点小牛拉大车了…
nameliu
(nameliu)
19
那就不量化,或者量化的少点
我记得32B的模型(deepseek-ai/DeepSeek-R1-Distill-Qwen-32B)如果不量化,48GB的L40s也无法完全加载到模型里的,好像要有100GB的模型在外面(有点不确定了,我记得我没有跑过deepseek-ai/DeepSeek-R1-Distill-Llama-70B,只跑过32B的,但是32B可以占用这么大的吗)。
量化直接就会把模型大小除以2的整数倍,模型大小成倍缩小,14B的,量化后的回答质量变化,可以感知出来。跑14B的可以完全不量化,精度不下降。
yhp666
(yhp666)
20
首先E5的cpu只支持pcie3你这3090可是pcie4,这就是典型的小马拉大车,当然这只影响内存到显存之间的速度。
然后建议你执行一个命令vnidia-smi -pm 1这样可以让你的显卡起步更快些。
最后建议你跑一个<24GB的模型,只用一张3090试试看能不能把显卡算力拉满。可以直接ollama run ***
还有就是nvtop不如pip install nvitop后者看负载更方便