网上找了一下,不同说法差好远诶

3070的应该装哪个版本,能跑7B/8B吗
勉强可以
![]() 跑小模型干嘛呀
跑小模型干嘛呀
我 7900xtx 跑 32B 量化,大概吃了 21G 显存。具体可以看这篇文章,挺准的。GPU System Requirements for Running DeepSeek-R1
学习下。
I7-13700K + 64G RAM + 4070Ti 12G
跑R1-7B感觉还行
跑llama3.3-70B字蹦得很慢,显存吃完,内存50G,CPU50%,GPU15%
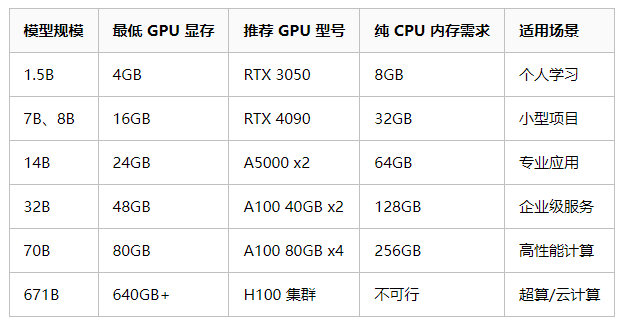
至少这个表是错的,量化模型不需要那么多显存,非量化的模型它又把所需显存说少了。
自己去huggingface看看模型文件大小就知道了
你按照参数算.
比如原来某个模型有 500b 参数, float32 精度,需要的空间就是 500×10的9次方
×4bytes=2000GB,要一个巨大的 gpu 集群才能跑起来。如果是 8b 参数,int4 精度,这样所需的空间只有 8 × 1 0的9次方 × 0.5 bytes = 4 GB,
在普通的电脑里也能跑起来。但实际上比这个计算出来的大小还要加一点常数。
满血671b 纯cpu内存也可以吧 使用intel Pmem
折腾一下给显卡找点活干 ![]()
内存足够大就行
使用llama mmap 配搭 raid ssd 不知可否对cpu内存降点 就是t/s更低
分享几个小tips:
综上,8GB显存(3070标准版)建议跑7b,极限点能跑14b(超短上下文)。
原来还能这么玩,那是要另外配置参数让模型只用cpu内存对吧
求看一下富哥部署满血版的电脑
我是缺那100w吗?我是缺高端显卡啊
——采访梁文锋
是3070桌面版本吗
对的zsbd
感谢科普! ![]()
对
本地gpu玩玩就好了
混堆就是木桶效应(硬件中数据传输速度最慢的一方)
api/网页 体现更佳