最近没啥事,来水一贴,先开个帖子,快下班了,明天把教程补上。
还请管理员把帖子移动到人工智能板块
前言
什么是NAS
此处提到的NAS是指Neural architecture search,翻译为中文是神经网络结构搜索,是AutoML(Automated machine learning)的一部分。(需要注意的是,这和Network Attached Storage即网络附加存储的缩写是一致的,如果你是奔着这个来的可以ctrl + W了)
NAS和HO(hyperparameter optimization) 以及 Meta-learning 并称为AutoML三剑客(谁称的,我撑的),其主要作用是为了优化神经网络的结构。
为什么要有NAS
大部分的机器学习或者人工智能从业者都会称自己为调参侠或者赛博炼丹师,因为大部分的工作就是给神经网络换个参数,换个中间的计算层,然后训练一下网络看看结果(别人我不知道,我是这样)。这个工作太心累,也很耗时,此时就需要有一个东西来自动优化参数,即用AI来训练AI。此时AutoML的作用就显现出来了,NAS是其中的一部分,可以用来自动优化网络结构,免去人工手动调参的繁琐工作。NAS出来了,就不用手写网络结构了,好棒!(也不是,你不用调整NAS的参数吗?)
下面就是NAS的主要内容了
NAS简介
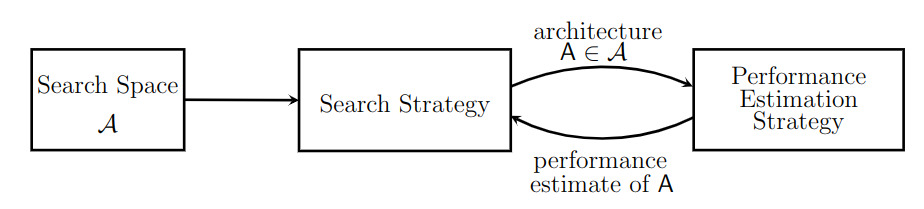
NAS的示意图如下,(图是在论文里扒拉的,论文在参考文献里面),它工作的主要流程是:
- 定义一个搜索空间,即我要的目标网络中有多少个卷积层 多少个全连接,使用什么激活函数,要不要dropout;
- 找一个搜索策略,即怎么搜索这些结构;
- 定义一个性能评价的标准,即你搜索出来的网络行不行,我得跑一下试试;
- 搜索出一个网络,跑一下测试,然后将测试结果反馈给搜索策略,重复2-4,直到找到一个满意的网络。
举一个例子就是,假设你要找个又甜又大的西瓜吃吃。
- 第一步,找一个瓜田,张三的瓜一向种的很好,去张三的瓜田找,这就定义了一个搜索空间
- 第二步,我也不知道什么瓜比较甜,所以就随机搜索,这就是定义了一个搜索策略为随机搜索
- 第三步,找到一个瓜,开个窗尝一尝不甜,下一个,这就是评价和反馈
看完了你大概明白了,这不就是瞎猜吗。是的,也不完全是,搜索策略有很多随机所搜只是其中一个。
搜索空间
搜索空间,就是你具体要一个什么样子的网络,需要你来指定多少到多少个卷积层,多少到多少个全连接层,每层的卷积核数以及步长等细节。这一部分是内容上是最简单的,但是在实际使用中是最复杂的,因为你搜索空间的定义决定了网络的上限和下限。如果将搜索空间指定为为无限大,那么你永远得不到最好的网络,如果搜索空间较小,你可能只能拿到一个局部最优的网络。
下面是几种典型的搜索空间定义方式:
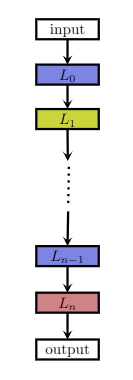
- 这是一个简单的线性搜索空间,所有的计算层都顺序连接在一起
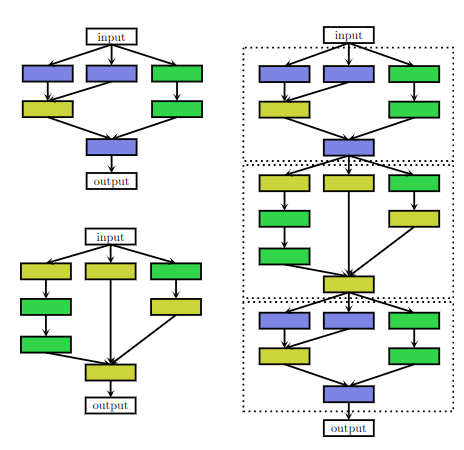
- 这是一个复杂的搜索空间模型,每个node都可以有前面任意node的连接

- 这是一个以Block为主的搜索空间,即Block是线性的,但是每个Block里面的内容是复杂的。
搜索算法
目前已有的搜索算法有这些:
- random search 随机搜索
- Bayesian optimization 贝叶斯
- evolutionary methods 进化算法
- reinforcement learning (RL) 强化学习
- gradient-based methods 梯度算法
这些算法如果有兴趣可以去参考文献中看一下,公式太多,我也有点看不懂,不过这都无所谓会用就行。
评价算法
评价算法在实际的使用过程中会有多种不同的标准,一般使用loss函数或者准确度作为实际的目标,这一部分略过。
实战
光说不练假把式,你已经学会了如何使用NAS来优化神经网络,下面就从头开始训练一个chatGPT吧,下面就使用NAS训练一个神经网络吧。
不要怕,我不会教你从0开始的,太难了,我也不会,下面使用kera库和keras tuner库来训练一个神经网络来识别手写字符。
类似的库还有optuna和autokeras等等,不过使用的原理都大差不差。
准备数据集
keras库中将常用的数据集进行了打包和封装,直接使用就好,在这里例子里面使用MNIST数据集进行训练。
mnist数据集是一个手写字符识别的数据集包含 60,000 张训练图像和 10,000 张测试图像,其中的数据样式如下,只有0-9十个类别,图像大小为28x28属于入门必用的数据集。
!https://upload.wikimedia.org/wikipedia/commons/f/f7/MnistExamplesModified.png
{kind=link}
使用方式如下:
import keras
import numpy as np
# 载入数据集
(x, y), (x_test, y_test) = keras.datasets.mnist.load_data()
# 将训练集分为两部分
x_train = x[:-10000]
x_val = x[-10000:]
y_train = y[:-10000]
y_val = y[-10000:]
# 归一化,基本操作,为了训练效果更好
x_train = np.expand_dims(x_train, -1).astype("float32") / 255.0
x_val = np.expand_dims(x_val, -1).astype("float32") / 255.0
x_test = np.expand_dims(x_test, -1).astype("float32") / 255.0
# 修改label格式
# 图像4 原始label格式为 [4]
# 修改后为[0 0 0 0 1 0 0 0 0 0]
# 即one-hot模式
num_classes = 10
y_train = keras.utils.to_categorical(y_train, num_classes)
y_val = keras.utils.to_categorical(y_val, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
定义搜索空间
import keras
import keras_tuner
def build_model(hp):
# 定义一个顺序的搜索空间
model = keras.Sequential()
model.add(layers.Flatten())
# 指定Dense层的数目
for i in range(hp.Int("num_layers", 1, 3)):
model.add(
layers.Dense(
# 每个Dense层的units数目都不一样
units=hp.Int(f"units_{i}", min_value=32, max_value=512, step=32),
# 但是他们的激活函数会一样,因为超参的名字是一样的
activation=hp.Choice("activation", ["relu", "tanh"]),
)
)
# 是不是要使用dropout层,也要搜索确定
if hp.Boolean("dropout"):
model.add(layers.Dropout(rate=0.25))
model.add(layers.Dense(10, activation="softmax"))
# 训练时的学习率如何设置
learning_rate = hp.Float("lr", min_value=1e-4, max_value=1e-2, sampling="log")
model.compile(
optimizer=keras.optimizers.Adam(learning_rate=learning_rate),
loss="categorical_crossentropy",
metrics=["accuracy"],
)
return model
# 测试一下网络是不是可以正确建立
build_model(keras_tuner.HyperParameters())
挑选一个搜索算法,开干
在搜索空间定义结束之后需要使用一个算法来进行搜索,keras有RandomSearch 、 BayesianOptimization 和 Hyperband 三种算法来选择。以下的例子以RandomSearch为例。
tuner = keras_tuner.RandomSearch(
# 如何建立模型,就是上面的build_model函数
hypermodel=build_model,
# 搜索的目标,此处为测试集的准确度
objective="val_accuracy",
# 试验总次数
max_trials=3,
# 每次试验建立的模型数量
executions_per_trial=2,
# 是否覆盖之前的结果
overwrite=True,
# 结果存储路径
directory="my_dir",
# 搜索的名字
project_name="helloworld",
)
# 打印一下搜索空间的摘要
tuner.search_space_summary()
#输出如下
"""
Search space summary
Default search space size: 5
num_layers (Int)
{'default': None, 'conditions': [], 'min_value': 1, 'max_value': 3, 'step': 1, 'sampling': 'linear'}
units_0 (Int)
{'default': None, 'conditions': [], 'min_value': 32, 'max_value': 512, 'step': 32, 'sampling': 'linear'}
activation (Choice)
{'default': 'relu', 'conditions': [], 'values': ['relu', 'tanh'], 'ordered': False}
dropout (Boolean)
{'default': False, 'conditions': []}
lr (Float)
{'default': 0.0001, 'conditions': [], 'min_value': 0.0001, 'max_value': 0.01, 'step': None, 'sampling': 'log'}
"""
# 使用mnist数据进行搜索
tuner.search(x_train, y_train, epochs=2, validation_data=(x_val, y_val))
在执行这一步之后,keras tuner就会帮你搜索需要的网络,并根据网络模型在测试集上面的准确度调整参数,接下来静待结果就可以了。
展示搜索结果
# 获取搜索到的最好的两个网络
models = tuner.get_best_models(num_models=2)
best_model = models[0]
# 下面两行在keras2.* 版本中需要执行,如果是keras3.*则不需要
input_shape = (None, 28, 28, 1)
best_model.build(input_shape)
# 打印网络摘要
best_model.summary()
"""
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
dense (Dense) (None, 288) 226080
dense_1 (Dense) (None, 192) 55488
dense_2 (Dense) (None, 448) 86464
dense_3 (Dense) (None, 10) 4490
=================================================================
Total params: 372522 (1.42 MB)
Trainable params: 372522 (1.42 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
"""
调整网络
在NAS搜索时,为了加快搜索的速度,并没有将所有的数据都放入到训练集中,这样搜索出来的网络可能效果并没有太好,需要使用额外的大量数据再次进行训练,然后网络才能投入使用
# 获取最好的5组参数
best_hps = tuner.get_best_hyperparameters(5)
# 使用最好的参数来创建网络
model = build_model(best_hps[0])
# 将所有数据放入进行训练
x_all = np.concatenate((x_train, x_val))
y_all = np.concatenate((y_train, y_val))
model.fit(x=x_all, y=y_all, epochs=1)
在此之后得到的就是最好的网络了,可以用来实际的测试中了。
参考文献
https://arxiv.org/pdf/1905.01392.pdf
https://arxiv.org/pdf/1808.05377.pdf