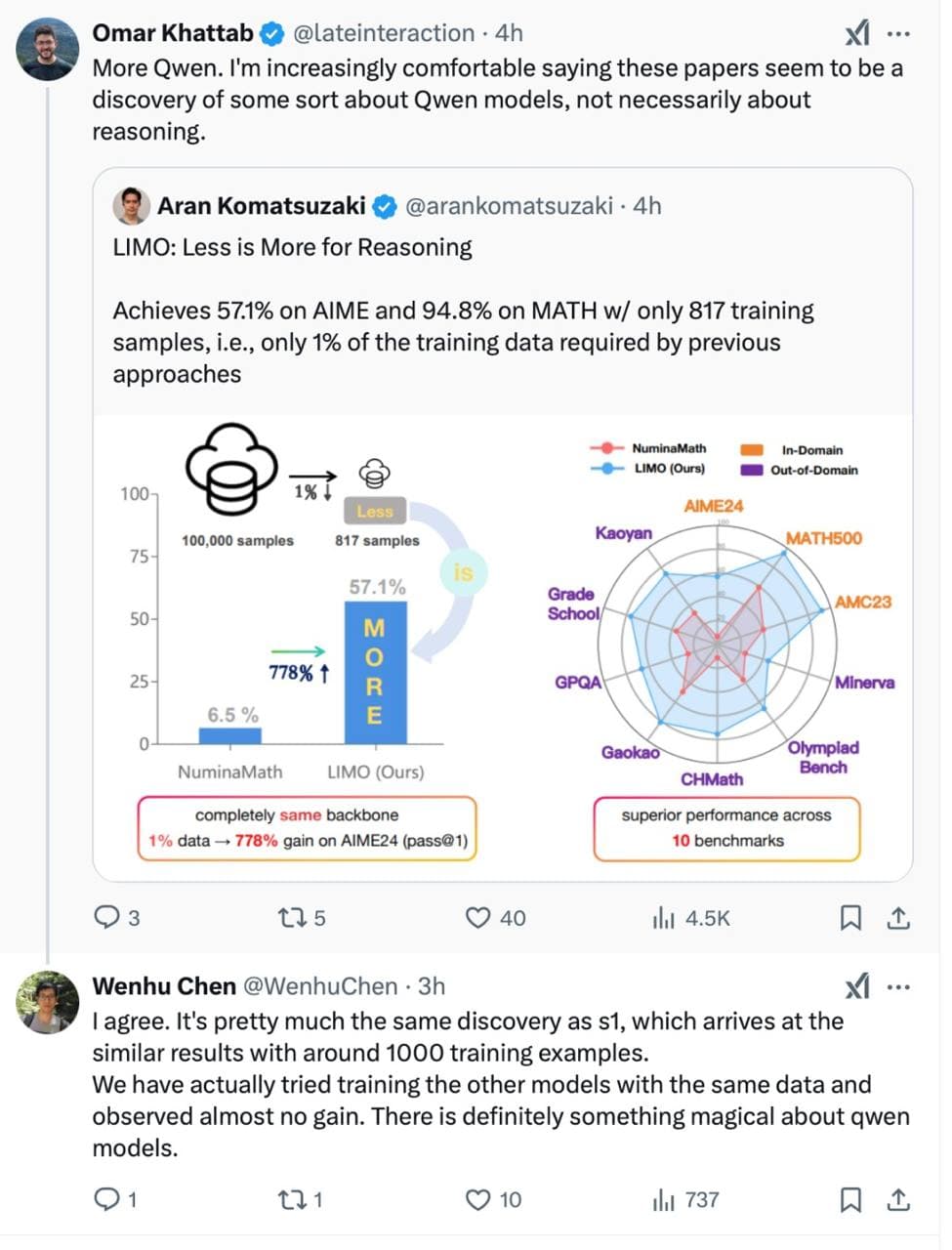
李飞飞团队近日发表论文称以50美元训练出推理模型s1,性能接近OpenAI等顶尖产品。经调查,该模型实为基于阿里云通义千问(Qwen)模型的微调成果,训练样本仅1000条。
业内专家指出,s1模型实为在通义千问基座模型上的微调成果,该研究利用了通义模型已具备的强大推理能力,新增训练数据仅起优化作用。业内专家强调,这与从零训练全新模型有本质区别。
阿里云证实,该团队以阿里通义千问Qwen2.5-32B-Instruct开源模型为底座,在16块H100GPU上监督微调26分钟,训练出新模型s1-32B,取得了与OpenAI的o1和DeepSeek的R1等尖端推理模型数学及编码能力相当的效果,甚至在竞赛数学问题上的表现比o1-preview高出27%。