用的ollama docker版部署的,大概一秒三个字左右,内存加上之前部署的其它服务,一共也就8个G。我的机器还运行着保活脚本,关掉的话应该更快点![]()
1 个赞
有没有教程 ![]()
没有 gpu 耶可以部署吗?
好像可以纯cpu
很简单的,先启动docker容器
sudo docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
这里面的ollama:/root/.ollama冒号左边的可以换成宿主机上任何一个目录,-p后面的数字是容器对外映射的端口,提供API服务的话就要设置这个。
然后直接运行sudo docker exec -it ollama ollama run deepseek-r1等下载完加载完就能在命令行对话了。
2 个赞
额,为啥我部署了,感觉吐字很慢,CPU还满负载了,后面就没有用了!
可以的,纯CPU推理,能把所有核心都跑满
毕竟是CPU,能力有限,有GPU还是GPU用着舒服
感谢分享。你这里面没看到指定7B版本。另外没有GPU是不是选择4-bit 量化模型更好。
可以说下部署环境吗,比如内存是否足够加载整个模型(没有使用swap)?
不过个人用的话,毕竟只有7B,能力并不厉害,只能用于特定的任务,并不好用。个人还是用api更方便,r1, gemini think, o3-mini等
居然可以吗,那倒是可以试试
量化的,占用的内存更少,速度更快一些
比如7B大概16GB,Q4量化后4GB 16/4
openwebui带的Ollama,可以直接拉模型,内存有24G吧,没有使用swap
刚才测了一下,如果CPU和内存足够的话,应该可以达到10 tokens/s
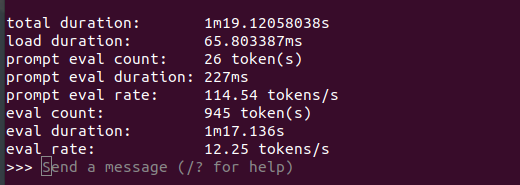
可能像上面佬说的,是CPU数目不太够?
我是直接启动的ollama,而不是openweiui里的ollama,不知道有没有影响。
注:这是TPU
噢 这样 那回头在试试 谢谢拉
1 个赞
多大内存的机子,4+24可以吗?
我就是这个配置
我部署的时候,卡在了第一步:即申请甲骨文。
1 个赞
命令行很快,ui就蛮多了,cpu占用还高
在快到期的OVH上安装了玩玩