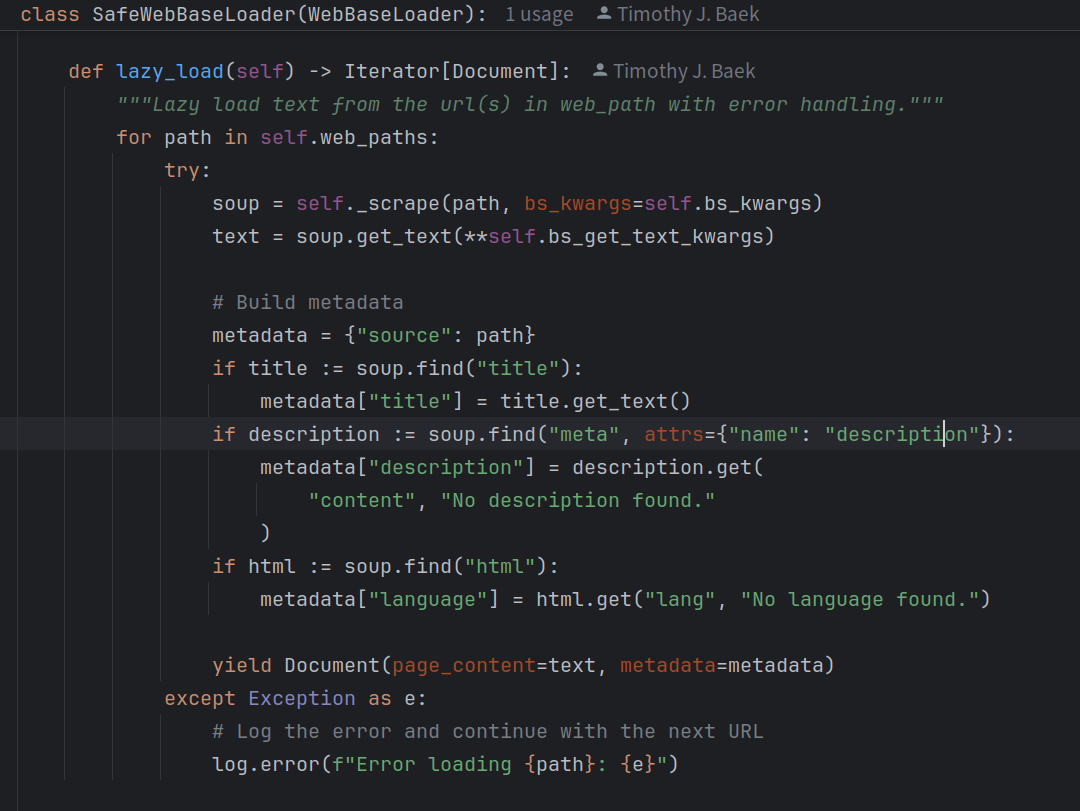
### Task:
Analyze the chat history to determine the necessity of generating search queries, in the given language. By default, **prioritize generating 1-3 broad and relevant search queries** unless it is absolutely certain that no additional information is required. The aim is to retrieve comprehensive, updated, and valuable information even with minimal uncertainty. If no search is unequivocally needed, return an empty list.
### Guidelines:
- Respond **EXCLUSIVELY** with a JSON object. Any form of extra commentary, explanation, or additional text is strictly prohibited.
- When generating search queries, respond in the format: { "queries": ["query1", "query2"] }, ensuring each query is distinct, concise, and relevant to the topic.
- If and only if it is entirely certain that no useful results can be retrieved by a search, return: { "queries": [] }.
- Err on the side of suggesting search queries if there is **any chance** they might provide useful or updated information.
- Be concise and focused on composing high-quality search queries, avoiding unnecessary elaboration, commentary, or assumptions.
- Today's date is: 2025-02-16.
- Always prioritize providing actionable and broad queries that maximize informational coverage.
### Output:
Strictly return in JSON format:
{
"queries": ["query1", "query2"]
}
### Chat History:
<chat_history>
USER: 英雄联盟 faker 的成就
</chat_history>