25/02/21更新 Qwen添加高级模式,支持自定义Prompt, 默认Prompt只会识别文字对复杂图片不会进行总结。
基于佬友的实现,已经有了一些OCR的实现方式。
- 【OpenWebUI增强】改进,为不支持图像识别的模型添加图像识别
- 【Qwen OCR 接力】基于佬友的QwenLM OCR开源项目实现的openwebui函数,轻松实现一键OCR的效果(支持最新的api 2025.2.10更新)
但在我实际的使用中存在一些问题。
- 调用google接口存在网络问题;自部署的worker调用也存在网络问题。
- Qwen的ocr函数是一个pipe函数,无法结合其他模型进行处理。
一些简单的改进:
- 添加HTTP_PROXY的参数配置。
- 将qwen的ocr实现整合到1.提供的fitler函数中。
- Qwen识别支持自定义Prompt.

Qwen识别对比
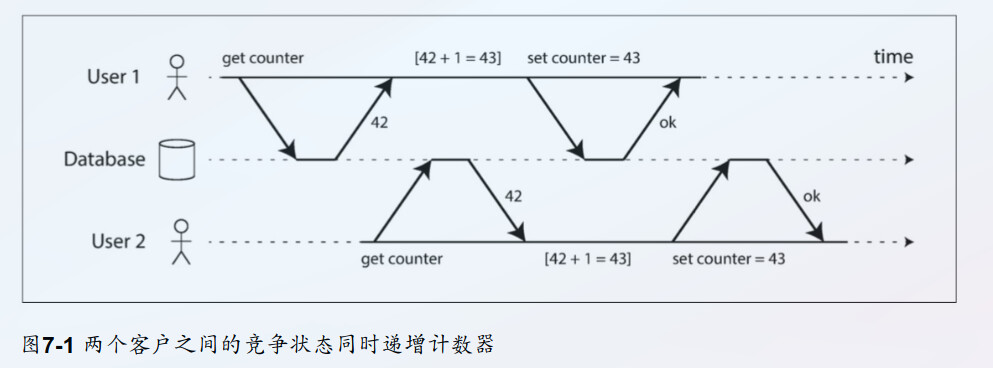
-
默认Prompt(worker中自带)
-
自定义Prompt(函数中自带,可自定义)
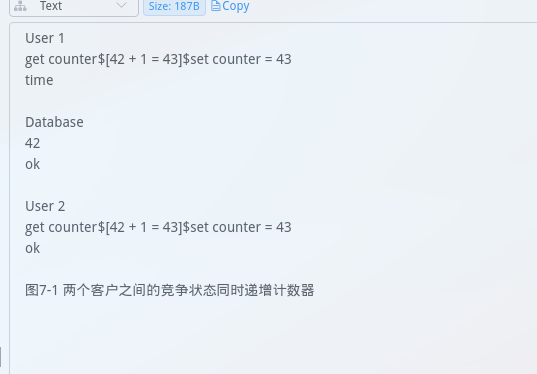
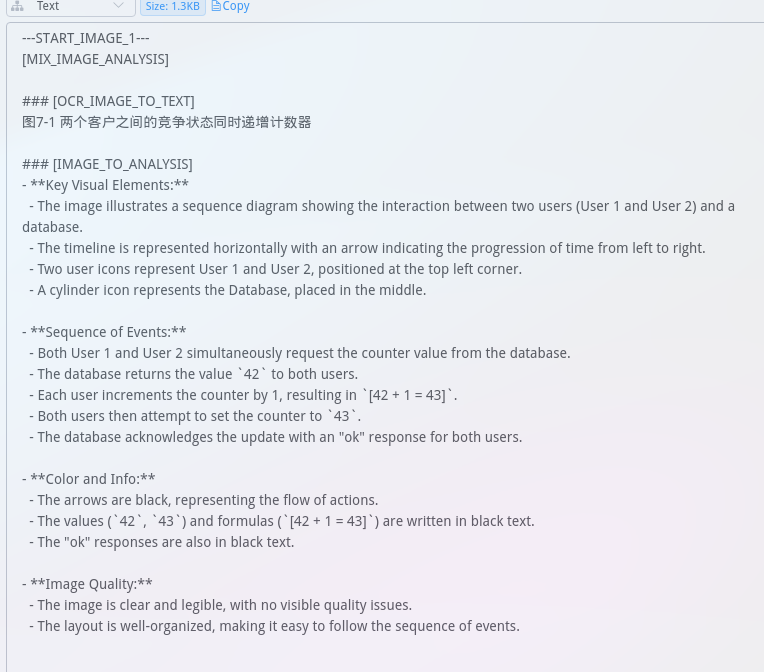
但复杂的Prompt似乎会增加识别时间,可自行斟酌使用
"""
title: Image Recognition Filter for OpenWebUI
author: D3bu9r (based on @xiniah's work)
version: 1.1
license: MIT
requirements:
- pydantic>=2.0.0
- aiohttp>=3.0.0
environment_variables:
- OCR_API_KEY (required)
"""
from typing import (
Callable,
Awaitable,
Any,
Optional,
Dict,
Tuple,
List,
)
import aiohttp
from pydantic import BaseModel, Field
import base64
import os
import re
from enum import Enum
from datetime import datetime
import redis
import hashlib
import json
from urllib.parse import quote
class APIType(Enum):
OPENAI = "openai"
GOOGLE = "google"
QWEN = "qwen"
class Filter:
API_VERSION = "2024-03"
REQUEST_TIMEOUT = (3.05, 60)
SUPPORTED_IMAGE_TYPES = ["image/jpeg", "image/png", "image/gif", "image/webp"]
MAX_IMAGE_SIZE = 5 * 1024 * 1024
MAX_RETRIES = 3
RETRY_DELAY = 1.0
class Valves(BaseModel):
API_TYPE: str = Field(
default="openai",
description="API type for image recognition (openai/google/qwen).",
)
BASE_URL: str = Field(
default="https://api.openai.com/v1",
description="Base URL for the API endpoint.",
)
PROXY_URL: str = Field(
default="http://<ip>:<port>",
description="HTTP proxy URL for API requests.",
)
OCR_API_KEY: str = Field(default="", description="API key/token for the API.")
CACHE_EXPIRE_HOURS: int = Field(
default=24,
description="Cache expiration time in hours.",
)
QWEN_API_URL: str = Field(
default="https://<worker>",
description="Qwen OCR API base URL.",
)
QWEN_ADVANCED_MODE: bool = Field(
default=False,
description="Qwen advanced mode, use custom prompt.",
)
ocr_prompt: str = Field(
default="""1. If text or code is present in the image:
- Start with "[OCR_IMAGE_TO_TEXT]"
- Extract all text maintaining exact formatting and hierarchy
- Use markdown syntax for formatting (e.g., headers, lists, tables, code blocks, link, Quotes, Sections, etc...)
- Mathematical formulas use LaTeX:
- Use `$` symbols to wrap formulas
- Inline formulas: $formula$
- Display formulas: $$formula$$
- Leave spaces before and after the `$` wrapped formulas
- Ensure LaTeX syntax is correct, formulas match the content in original images, and can be rendered properly
- Use **bold**, *italics* etc. to emphasize content
- Preserve line breaks and text layout where meaningful
- Include text location indicators if relevant (e.g., "header:", "footer:", "Sidebar", etc...)
- For plain text images, there is no need to interpret or comment on the text content, unless there are specific circumstances that require explanation.
4. If no text, code, or other additional context:
- Start with "[IMAGE_TO_ANALYSIS]"
- Provide a concise description of key visual elements
- Note any relevant structural or layout information
- Mention any important visual hierarchy or emphasis
- Use bullet points to note color and info for distinct elements
- Report image quality issues
5. For mixed content (both text and significant visual elements):
- Start with "[MIX_IMAGE_ANALYSIS]"
- Include both sections with their respective headers
- Maintain clear separation between text content and visual description
Please ensure the output is well-structured, easy to read, and maintains professional formatting.""",
description="进行图像识别的提示词",
)
model_name: str = Field(
default="gpt-4o-mini",
description="Model name used for OCR on images.",
)
def __init__(self):
self.valves = self.Valves()
self.request_id = None
self.emitter = None
# 初始化Redis连接
self.redis_client = redis.Redis(
host="<redis-host>", port=6379, db=0, password="<password>"
)
# 将缓存时间从小时转换为秒
self.CACHE_EXPIRE_TIME = self.valves.CACHE_EXPIRE_HOURS * 60 * 60
async def emit_status(
self, message: str = "", done: bool = False, error: bool = False
):
if self.emitter:
await self.emitter(
{
"type": "status",
"data": {
"description": message,
"done": done,
"error": error,
},
}
)
def _get_image_hash(self, image_url: str) -> str:
"""生成图片内容的hash值"""
return hashlib.md5(image_url.encode()).hexdigest()
def _del_image_cache(self, message):
"""删除对应消息图片中的缓存"""
if isinstance(message["content"], list):
for content in message["content"]:
if content["type"] == "image_url":
image_url = content["image_url"]["url"]
image_hash = self._get_image_hash(image_url)
cached_result = self.redis_client.get(image_hash)
if cached_result:
self.redis_client.delete(image_hash)
def _find_process_image_messages(
self, messages: List[Dict]
) -> Tuple[bool, List[Dict]]:
"""
查找所有包含图片的消息
返回: (是否处理过缓存图片, 需要OCR处理的消息列表)
"""
i = 0
ocr_messages = []
is_process = False
# 检查每张图片是否有缓存,如果有缓存则进行内容替换,没有则将图片放入一个新的message交给模型处理
for message in messages:
if message["role"] == "user" and isinstance(message.get("content"), list):
has_uncached_image = False
# 先检查这条消息是否需要OCR处理
for content in message["content"]:
if content["type"] == "image_url":
url = content["image_url"]["url"]
image_hash = self._get_image_hash(url)
cached_result = self.redis_client.get(image_hash)
if cached_result:
content["type"] = "text"
content["text"] = f"[{++i}]{cached_result.decode()}"
is_process = True
else:
has_uncached_image = True
# 只有当消息中有未缓存的图片时,才添加到ocr_messages
if has_uncached_image:
ocr_messages.append(message)
return is_process, ocr_messages
def _prepare_request(self, message) -> tuple[dict, dict, dict]:
# 修改提示词,要求返回结构化内容
structured_prompt = (
"""
Please analyze each image and provide responses in this exact format:
---START_IMAGE_{n}---
{content}
---END_IMAGE_{n}---
Where:
- {n} is the sequential number of the image (1, 2, etc.)
- {content} follows the original analysis guidelines
Original guidelines:
"""
+ self.valves.ocr_prompt
)
if self.valves.API_TYPE == APIType.QWEN.value:
return self._prepare_qwen_request(message, structured_prompt)
api_key = self.valves.OCR_API_KEY.strip()
params = None
if self.valves.API_TYPE == APIType.OPENAI.value:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
}
elif self.valves.API_TYPE == APIType.GOOGLE.value:
headers = {
"Content-Type": "application/json",
"Accept": "*/*",
"Host": "generativelanguage.googleapis.com",
}
params = {"key": api_key}
# 修复消息处理
if isinstance(message, dict) and "content" in message:
message_content = message["content"]
else:
message_content = message
# 只保留图片类型的内容
newmessage = [
item
for item in message_content
if isinstance(item, dict) and item.get("type") == "image_url"
]
# OpenAI请求格式
if self.valves.API_TYPE == APIType.OPENAI.value:
body = {
"model": self.valves.model_name,
"messages": [
{
"role": "system",
"content": [{"type": "text", "text": structured_prompt}],
},
{"role": "user", "content": newmessage},
],
"temperature": 0.0,
}
return headers, body, None
elif self.valves.API_TYPE == APIType.GOOGLE.value:
body = {
"generationConfig": {
"temperature": 0.0,
"topP": 0.9,
"topK": 50,
"maxOutputTokens": 8192,
"stopSequences": [],
},
"system_instruction": {
"parts": [{"text": structured_prompt}],
},
"safetySettings": [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "OFF"},
{"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "OFF"},
{"category": "HARM_CATEGORY_HARASSMENT", "threshold": "OFF"},
{"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "OFF"},
],
"contents": [
{
"role": "user",
"parts": [
{"text": ""},
*[
{
"inlineData": {
"data": item["image_url"]["url"].split(",")[
1
], # 提取base64数据部分
"mimeType": item["image_url"]["url"]
.split(";")[0]
.split(":")[1], # 提取mime类型
}
}
for item in newmessage
],
],
}
],
}
return headers, body, params
def _uri_encode(self, content) -> str:
# 步骤 1: URL 编码
url_encoded_prompt = quote(content)
# 步骤 2: Base64 编码
# 先将字符串转为字节(b64encode 需要字节输入),然后编码
return base64.b64encode(url_encoded_prompt.encode("utf-8")).decode("utf-8")
def _prepare_qwen_request(self, message, prompt) -> tuple[dict, dict, dict]:
advanced_mode = "true" if self.valves.QWEN_ADVANCED_MODE else "false"
custom_prompt = self._uri_encode(prompt) if advanced_mode else None
headers = {
"x-custom-cookie": self.valves.OCR_API_KEY or "api",
"x-advanced-mode": advanced_mode,
"x-custom-prompt": custom_prompt,
"Content-Type": "application/json",
}
body = {"messages": []}
for content in message.get("content", []):
if content["type"] == "image_url":
image_url = content["image_url"]["url"]
if image_url.startswith("file://"):
body["file_path"] = image_url[7:]
elif image_url.startswith("http"):
body["image_url"] = image_url
elif "base64" in image_url:
body["base64_image"] = image_url.split(",")[-1]
return headers, body, None
async def _perform_ocr(self, message) -> str:
"""Internal method for performing OCR recognition."""
if self.valves.API_TYPE == APIType.QWEN.value:
return await self._perform_qwen_ocr(message)
headers, body, params = self._prepare_request(message)
if self.valves.API_TYPE == APIType.OPENAI.value:
url = f"{self.valves.BASE_URL}/chat/completions"
elif self.valves.API_TYPE == APIType.GOOGLE.value:
url = f"{self.valves.BASE_URL}/models/{self.valves.model_name}:generateContent"
# 获取代理配置
proxy = (
self.valves.PROXY_URL.strip()
if self.valves.API_TYPE == APIType.GOOGLE.value
else None
)
# 构建请求参数
request_args = {
"url": url,
"json": body,
"headers": headers,
"params": params,
"timeout": 60,
}
# 仅Google请求添加代理
if self.valves.API_TYPE == APIType.GOOGLE.value and proxy:
request_args["proxy"] = proxy
print(f"Using proxy: {proxy}") # 调试日志
async with aiohttp.ClientSession() as session:
try:
async with session.post(**request_args) as response:
response_data = await response.json()
response.raise_for_status()
# 获取原始结果
if self.valves.API_TYPE == APIType.OPENAI.value:
result = response_data["choices"][0]["message"]["content"]
elif self.valves.API_TYPE == APIType.GOOGLE.value:
result = response_data["candidates"][0]["content"]["parts"][0][
"text"
]
else:
raise ValueError(f"No result found for {self.valves.API_TYPE}")
return result
except (aiohttp.ClientResponseError, aiohttp.ClientError) as e:
if isinstance(e, aiohttp.ClientResponseError):
error_message = f"图片识别请求上游失败,状态码: {e.status}, 错误消息: {e.message}"
else:
error_message = f"图片识别请求失败,错误消息: {e}"
await self.emit_status(message=error_message, done=True, error=True)
return ""
except json.JSONDecodeError:
await self.emit_status(
message="API返回了无效的JSON响应", done=True, error=True
)
return ""
except Exception as e:
await self.emit_status(message=f"未知错误: {e}", done=True, error=True)
return ""
async def _perform_qwen_ocr(self, message) -> str:
try:
headers, body, _ = self._prepare_request(message)
ocr_result = ""
# 处理本地文件上传
if "file_path" in body and os.path.exists(body["file_path"]):
upload_url = f"{self.valves.QWEN_API_URL}/proxy/upload"
form_data = aiohttp.FormData()
form_data.add_field(
"file",
open(body["file_path"], "rb"),
filename=os.path.basename(body["file_path"]),
)
async with aiohttp.ClientSession() as session:
# 文件上传
async with session.post(
upload_url,
headers={"x-custom-cookie": headers["x-custom-cookie"]},
data=form_data,
) as resp:
upload_data = await resp.json()
image_id = upload_data.get("id")
# 执行OCR识别
if image_id:
recognize_url = f"{self.valves.QWEN_API_URL}/recognize"
async with session.post(
recognize_url, headers=headers, json={"imageId": image_id}
) as resp:
ocr_data = await resp.json()
ocr_result = self._format_qwen_result(ocr_data)
# 处理URL或Base64
else:
api_url = f"{self.valves.QWEN_API_URL}/api/recognize/"
if "image_url" in body:
api_url += "url"
payload = {"imageUrl": body["image_url"]}
else:
api_url += "base64"
payload = {"base64Image": body["base64_image"]}
async with aiohttp.ClientSession() as session:
async with session.post(
api_url,
headers=headers,
json=payload,
proxy=self.valves.PROXY_URL if self.valves.PROXY_URL else None,
) as resp:
ocr_data = await resp.json()
ocr_result = self._format_qwen_result(ocr_data)
return f"---START_IMAGE_1---\n{ocr_result}\n---END_IMAGE_1---"
except Exception as e:
await self.emit_status(
message=f"Qwen OCR失败: {str(e)}", done=True, error=True
)
return ""
def _format_qwen_result(self, data: dict) -> str:
if data.get("success"):
return data.get("result", "未识别到文本")
return f"识别错误: {data.get('error', '未知错误')}"
def _convert_message_format(self, messages: list) -> list:
"""Convert complex message format to simple format."""
converted_messages = []
for message in messages:
if isinstance(message.get("content"), list):
# Combine all text content
combined_text = []
for content in message["content"]:
if content["type"] == "text":
combined_text.append(content["text"])
# If we have already converted image to text
elif "text" in content:
combined_text.append(content["text"])
# Join all text with spaces
converted_messages.append(
{
"role": message["role"],
"content": " ".join(combined_text).strip(),
}
)
else:
# If it's already in simple format, keep it as is
converted_messages.append(message)
return converted_messages
def _parse_ocr_result(self, result: str) -> List[Tuple[int, str]]:
"""解析OCR结果为(图片索引, 内容)的列表"""
parsed_results = []
import re
# 使用正则匹配每个图片块
# pattern = r"---START_IMAGE_(\d+)---\n(.*?)\n---END_IMAGE_\1---"
pattern = r"---START_IMAGE_\{?(\d+)\}?---\n(.*?)\n---END_IMAGE_\{?\1\}?---"
matches = re.finditer(pattern, result, re.DOTALL)
for match in matches:
index = int(match.group(1))
content = match.group(2).strip()
parsed_results.append((index, content))
return parsed_results
def _check_image_size(self, image_url: str) -> bool:
if image_url.startswith("data:image"):
# 解析base64
try:
header, data = image_url.split(",", 1)
binary_data = base64.b64decode(data)
return len(binary_data) <= self.MAX_IMAGE_SIZE
except:
return False
return True # URL形式的图片暂时不检查大小
async def inlet(
self,
body: dict,
__event_emitter__: Callable[[Any], Awaitable[None]],
__user__: Optional[dict] = None,
__model__: Optional[dict] = None,
) -> dict:
self.emitter = __event_emitter__
# 参数验证
if self.valves.API_TYPE == APIType.QWEN.value and not self.valves.QWEN_API_URL:
await self.emit_status(
message="❌ Qwen API URL未配置", done=True, error=True
)
return body
# 检查Key是否存在
if not self.valves.OCR_API_KEY or not self.valves.OCR_API_KEY.strip():
await self.emit_status(
message="❌ 错误:OCR_API_KEY未设置", done=True, error=True
)
return body
# 检查API类型
if self.valves.API_TYPE not in [
APIType.OPENAI.value,
APIType.GOOGLE.value,
APIType.QWEN.value,
]:
await self.emit_status(
message="❌ 错误:API_TYPE未设置或不正确(openai/google/qwen)",
done=True,
error=True,
)
return body
# 检查reidis是否连接成功
if not self.redis_client.ping():
await self.emit_status(
message="❌ 错误:Redis连接失败,请检查redis是否正常",
done=True,
error=True,
)
return body
messages = body.get("messages", [])
# 检查是否需要重新生成图像识别内容
is_roll = body.get("roll", False)
description = ""
if is_roll:
self._del_image_cache(messages[-1])
del body["roll"]
description = "🧹 清除缓存,重新进行图像分析,请耐心等待..."
else:
description = "🔍 开始进行图像分析,请耐心等待..."
# 查找所有需要进行OCR的messages
instructions = "[INSTRUCTION]\nThe user has sent images, which have been converted to text information through AI. Labels [1], [2]... indicate the sequence number of the images."
is_process, ocr_messages = self._find_process_image_messages(messages)
if not ocr_messages:
if is_process:
body["messages"] = self._convert_message_format(messages)
# 对ai加一条说明
body["messages"].insert(0, {"role": "system", "content": instructions})
return body
start_time = datetime.now()
await self.emit_status(message=description, done=False)
# 将需要进行ocr的图像交给模型进行识别并处理
for message in ocr_messages:
# for content in message["content"]:
# if content["type"] == "image_url":
# if not self._check_image_size(content["image_url"]["url"]):
# await self.emit_status(message="❌ 错误:图片过大", done=True, error=True)
# return body
result = await self._perform_ocr(message)
# 解析结果并分别缓存
if not result:
return body
parsed_results = self._parse_ocr_result(result)
# 获取message中的图片URL列表并更新内容
i = 0
for content in message["content"]:
if content["type"] == "image_url":
url = content["image_url"]["url"]
image_hash = self._get_image_hash(url)
# 缓存结果
self.redis_client.setex(
image_hash,
self.CACHE_EXPIRE_TIME,
parsed_results[i][1], # content
)
# 更新message内容
content["type"] = "text"
content["text"] = f"[{i+1}]{parsed_results[i][1]}"
i += 1
# 计算处理时间
end_time = datetime.now()
process_time = (end_time - start_time).total_seconds()
# 发送状态更新
await self.emit_status(
message=f"🎉识别成功,耗时:{process_time}秒,交由模型进行处理...", done=True
)
# 转换消息格式
body["messages"] = self._convert_message_format(messages)
# 对ai加一条说明
body["messages"].insert(0, {"role": "system", "content": instructions})
return body
async def outlet(
self,
body: dict,
__event_emitter__: Callable[[Any], Awaitable[None]],
__user__: Optional[dict] = None,
__model__: Optional[dict] = None,
) -> dict:
return body
PS:由于代码调整都是通过Deepseek进行修改,可能存在一些问题,但总体应该不影响日常使用。
感谢 D3bu9r、 konbakuyomu 大佬的实现。