(\ _ /)
( ・-・)
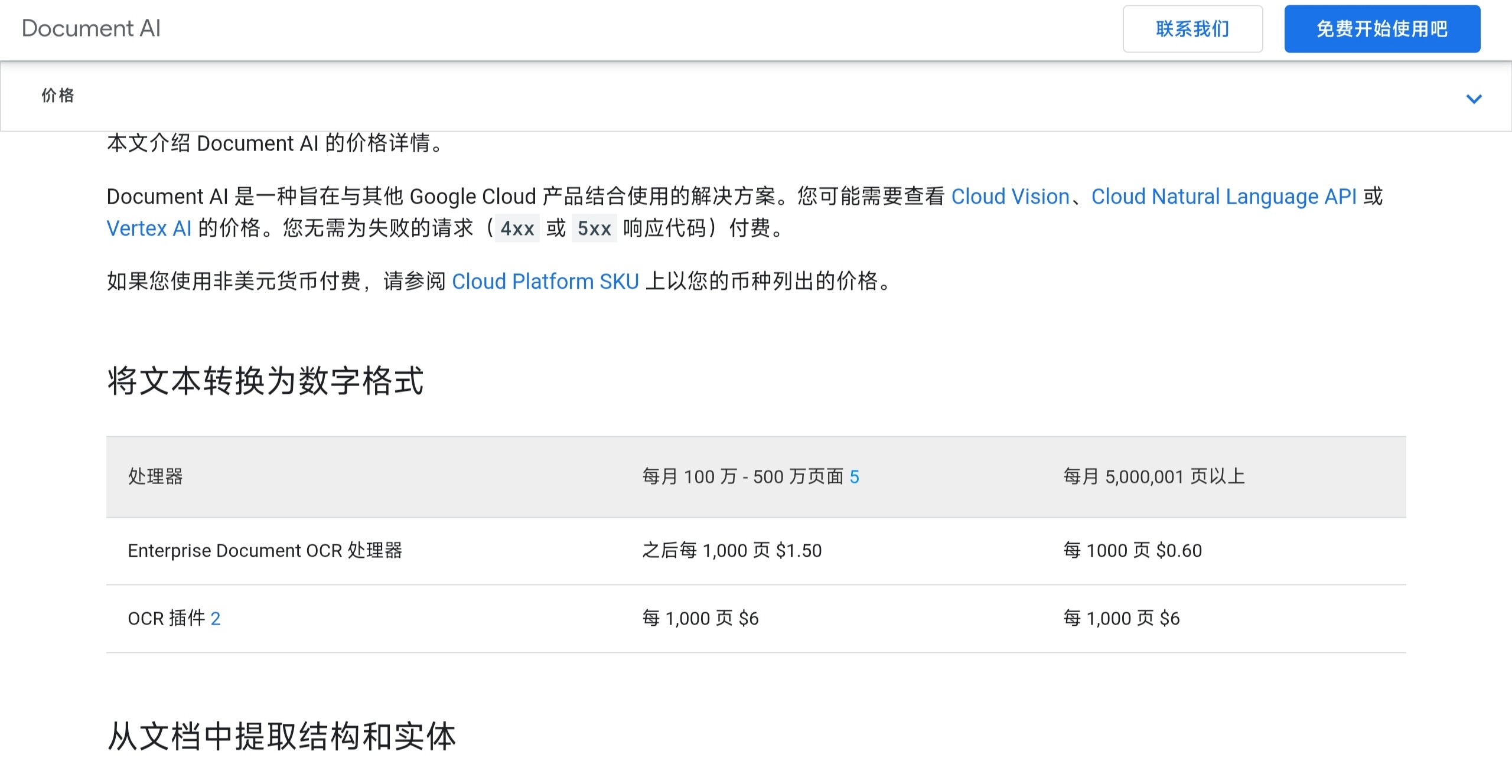
/っ ![]() 就是,GCP 有个专门解析文档的 Document AI
就是,GCP 有个专门解析文档的 Document AI ![]()
概览 – Document AI – Google Cloud Console
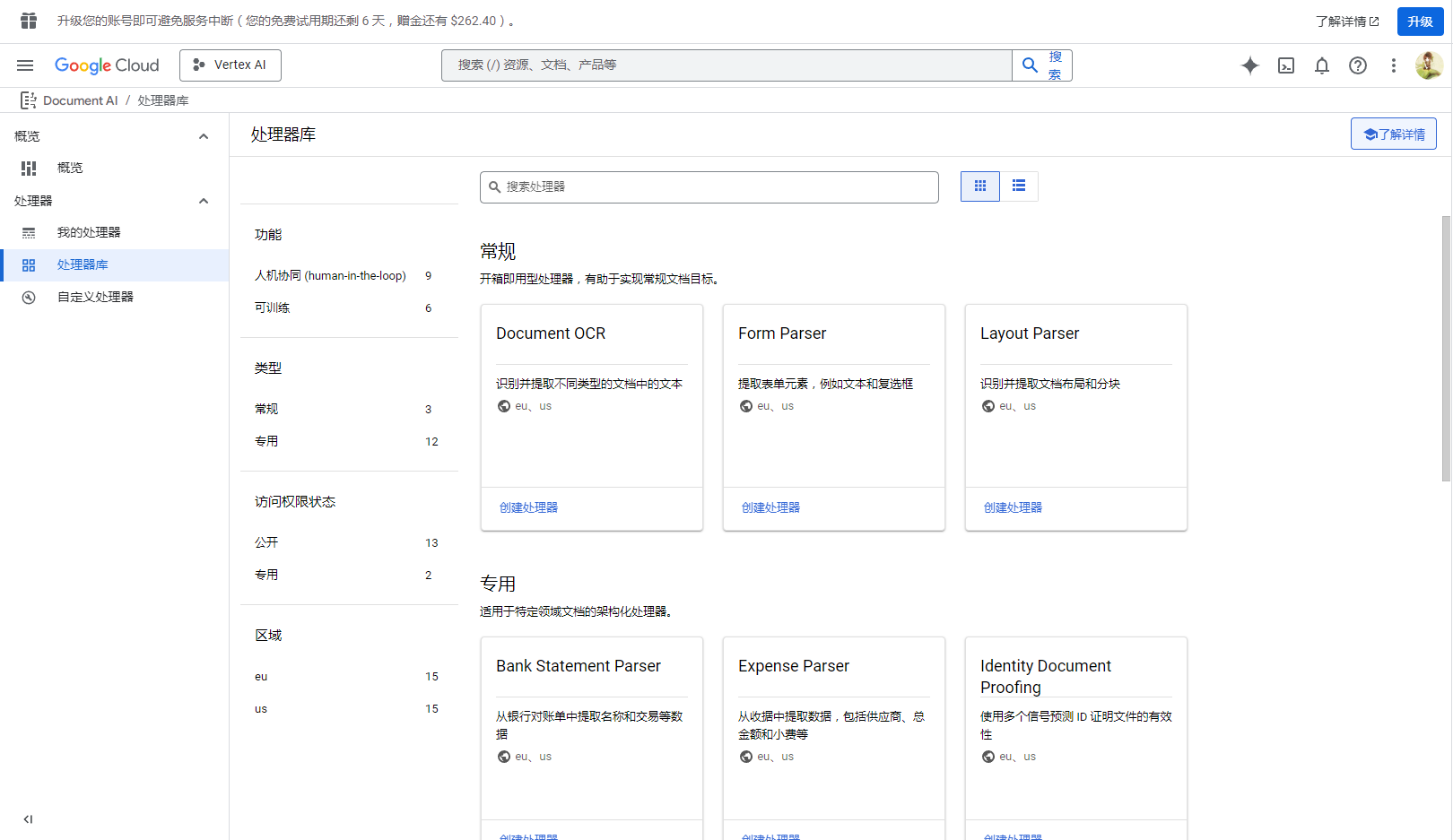
不止是 PDF,还有专门解析表格能记住空间位置的那些 (还没用过)
然后刷到佬友有个 30 年前的纯 PDF 扫描件,原件 ![]()
https://linux.do/t/topic/453425/11
于是试试。
不是教程贴,因为我也是第一次弄这玩意,我也不知道都特么修改了什么配置。Windows 7 很多不兼容了卡 BUG 装了一堆限 Windows 10 才能装的 Python 结果卸载不了差点把系统搞死。
最后发现坑是 grpcio Windows 7 只能兼容到 1.50.0 版本 tnnd。
水这贴的意义不是喂鱼,而是想说这条路、走得通。
原书 ↓
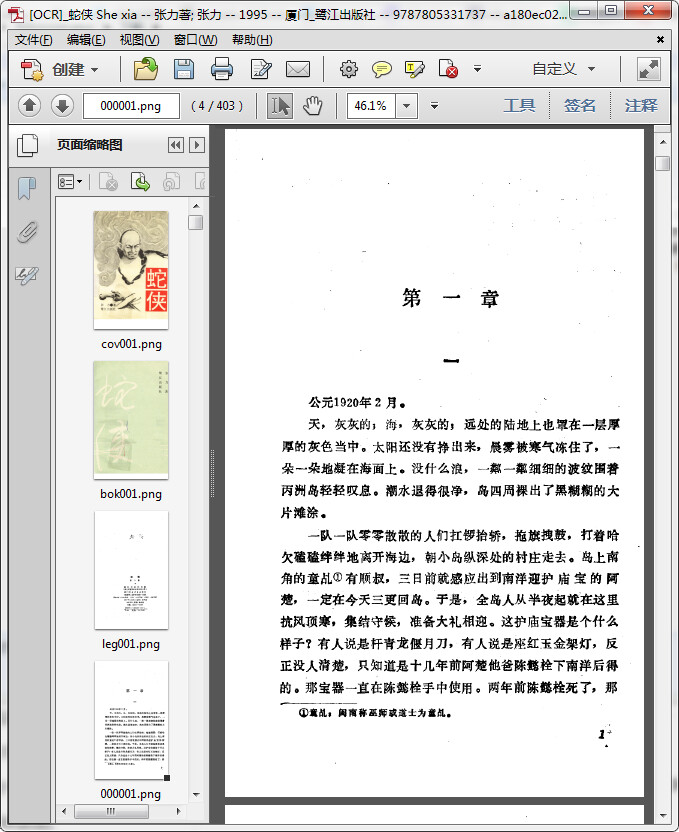
第 ① 步 OCR → TXT
因为 Document AI 的上限一次只能处理 15 页的纯图 PDF,所以需要先拆分下文档(Adobe 家的 Acrobat 自带拆分工具):
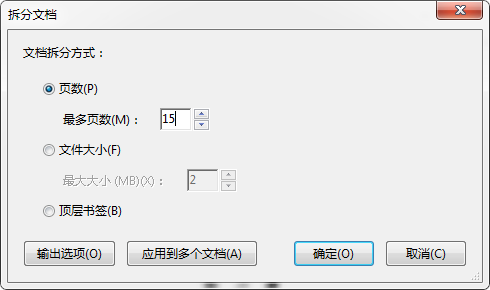
然后,15 页只是接口的上限,不是开发者的上限!
所以写个 Python 批处理就好 ![]()
DocumentaiTextExtractor.py
# pip install google-cloud-documentai
# pip install grpcio==1.50.0 # Windows 7 只能兼容到这个版本。
# pip install tqdm # 用于进度条显示
# 导入必要的库
from google.api_core.client_options import ClientOptions
from google.cloud import documentai # type: ignore
import tkinter as tk
from tkinter import filedialog
import os
import threading
from concurrent.futures import ThreadPoolExecutor, as_completed
from tqdm import tqdm
import time
# 设置代理
os.environ.update({'http_proxy': 'http://127.0.0.1:1081', 'https_proxy': 'http://127.0.0.1:1081'})
# 设置服务帐户密钥文件路径
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "(鉴权 JSON,用你自己的).json"
# 配置信息
project_id = "(敏感信息屏蔽掉)" # 你的 GCP 项目 ID
location = "us" # 处理器位置,可以是 "us" 或 "eu"
processor_id = "(敏感信息屏蔽掉)" # 你的处理器ID
max_workers = 5 # 最大并行线程数,可根据需要调整
def process_single_document(file_path, client, processor_name):
"""处理单个文档的函数"""
try:
# 读取文件内容到内存
with open(file_path, "rb") as image:
image_content = image.read()
# 加载二进制数据
raw_document = documentai.RawDocument(
content=image_content,
mime_type="application/pdf",
)
# 配置处理请求
request = documentai.ProcessRequest(name=processor_name, raw_document=raw_document)
# 调用 Document AI 服务处理文档
result = client.process_document(request=request)
document = result.document
# 获取所选文件的目录和文件名(不含扩展名)
file_dir = os.path.dirname(file_path)
file_name = os.path.splitext(os.path.basename(file_path))[0]
# 构建输出文件的完整路径
output_file_path = os.path.join(file_dir, f"{file_name}.txt")
# 将识别的文本写入到输出文件
with open(output_file_path, "w", encoding="utf-8") as output_file:
output_file.write(document.text)
return True, file_path, output_file_path
except Exception as e:
return False, file_path, str(e)
def batch_process_documents():
"""批量处理文档的主函数"""
# 初始化 Document AI 客户端
opts = ClientOptions(api_endpoint=f"{location}-documentai.googleapis.com")
client = documentai.DocumentProcessorServiceClient(client_options=opts)
processor_name = f"projects/{project_id}/locations/{location}/processors/{processor_id}"
# 创建文件选择对话框
root = tk.Tk()
root.withdraw() # 隐藏主窗口
# 弹出文件选择对话框,允许多选
file_paths = filedialog.askopenfilenames(
title="选择多个 PDF 文件",
filetypes=[("PDF 文件", "*.pdf")]
)
# 如果用户取消了文件选择,则退出程序
if not file_paths or len(file_paths) == 0:
print("未选择文件,程序退出。")
return
total_files = len(file_paths)
print(f"已选择 {total_files} 个文件,开始处理...")
# 创建进度条
progress_bar = tqdm(total=total_files, desc="处理进度", unit="文件")
# 使用线程池并行处理文件
results = []
with ThreadPoolExecutor(max_workers=max_workers) as executor:
# 提交所有任务
future_to_file = {
executor.submit(process_single_document, file_path, client, processor_name): file_path
for file_path in file_paths
}
# 处理完成的任务
for future in as_completed(future_to_file):
file_path = future_to_file[future]
try:
success, path, result = future.result()
if success:
results.append((path, result, True))
else:
results.append((path, result, False))
except Exception as e:
results.append((file_path, str(e), False))
# 更新进度条
progress_bar.update(1)
# 关闭进度条
progress_bar.close()
# 显示处理结果统计
success_count = sum(1 for _, _, success in results if success)
failed_count = total_files - success_count
print(f"\n处理完成!成功: {success_count} 个文件,失败: {failed_count} 个文件")
# 如果有失败的文件,显示详情
if failed_count > 0:
print("\n失败文件列表:")
for path, error, success in results:
if not success:
print(f"- {os.path.basename(path)}: {error}")
# 显示所有成功处理的文件路径
if success_count > 0:
print("\n成功处理的文件:")
for path, output, success in results:
if success:
print(f"- {os.path.basename(path)} -> {os.path.basename(output)}")
if __name__ == "__main__":
batch_process_documents()
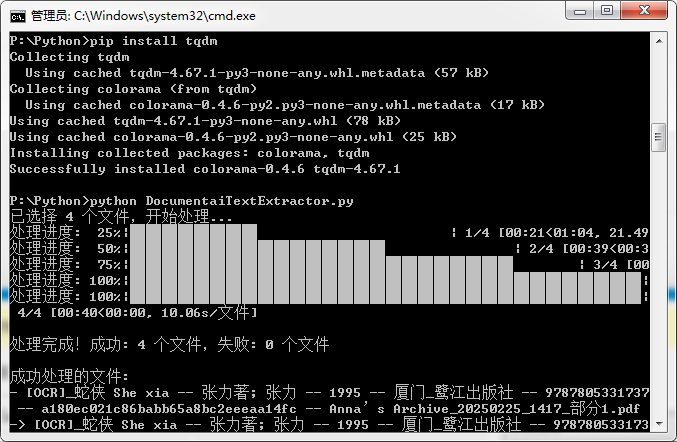
昨晚已经跑过完全体了,简单图例 ↑
Document AI OCR 会尽量保持原来的排版,所以提取的文本长这样 ![]()

先把所有文本合并起来,用 DOS 或 Python 都行 ![]()
DocumentaiTextMerge.py
import os
import re
import tkinter as tk
from tkinter import filedialog
from tkinter import messagebox
from tqdm import tqdm
def extract_number(filename):
"""从文件名中提取数字部分"""
match = re.search(r'部分(\d+)', filename)
if match:
return int(match.group(1))
return 0
def get_base_filename(file_paths):
"""从选择的文件中提取基本文件名(去掉_部分X)"""
if not file_paths:
return "merged_output.txt"
# 获取第一个文件的文件名
first_file = os.path.basename(file_paths[0])
# 移除"_部分X.txt"部分
base_name = re.sub(r'_部分\d+\.txt$', '.txt', first_file)
# 如果文件名以[OCR]开头,可以选择保留或移除
base_name = re.sub(r'^\[OCR\]', '', base_name)
return base_name.strip()
def merge_text_files():
"""合并多个文本文件为一个文件,按数字顺序排序"""
# 创建文件选择对话框
root = tk.Tk()
root.withdraw() # 隐藏主窗口
# 弹出文件选择对话框,允许多选
file_paths = filedialog.askopenfilenames(
title="选择要合并的文本文件",
filetypes=[("文本文件", "*.txt")]
)
# 如果用户取消了文件选择,则退出程序
if not file_paths or len(file_paths) == 0:
print("未选择文件,程序退出。")
return
total_files = len(file_paths)
print(f"已选择 {total_files} 个文件,开始处理...")
# 按照文件名中的数字部分排序
sorted_files = sorted(file_paths, key=lambda x: extract_number(os.path.basename(x)))
# 自动生成输出文件名
base_filename = get_base_filename(sorted_files)
default_dir = os.path.dirname(sorted_files[0])
output_file_path = os.path.join(default_dir, base_filename)
# 确认是否使用自动生成的文件名
if not messagebox.askokcancel("确认输出文件", f"将合并为以下文件:\n{output_file_path}\n\n点击确定继续,取消重新选择"):
# 如果用户不同意自动文件名,则手动选择
output_file_path = filedialog.asksaveasfilename(
title="保存合并后的文件",
initialfile=base_filename,
defaultextension=".txt",
filetypes=[("文本文件", "*.txt")]
)
if not output_file_path:
print("未指定输出文件,程序退出。")
return
# 创建进度条
progress_bar = tqdm(total=total_files, desc="合并进度", unit="文件")
# 合并文件内容
with open(output_file_path, 'w', encoding='utf-8') as outfile:
# 写入合并信息作为文件头
outfile.write(f"# 合并文件 - 共{total_files}个文件\n")
outfile.write("# " + "="*50 + "\n\n")
# 逐个读取并写入文件内容
for file_path in sorted_files:
file_name = os.path.basename(file_path)
file_number = extract_number(file_name)
# 写入分隔符和文件信息
outfile.write(f"\n\n# ===== 第{file_number}部分 ({file_name}) =====\n\n")
try:
# 读取文件内容并写入
with open(file_path, 'r', encoding='utf-8') as infile:
content = infile.read()
outfile.write(content)
except Exception as e:
outfile.write(f"\n[读取错误: {str(e)}]\n")
# 更新进度条
progress_bar.update(1)
# 关闭进度条
progress_bar.close()
print(f"\n合并完成!已将{total_files}个文件合并到: {output_file_path}")
# 询问是否打开合并后的文件
if messagebox.askyesno("完成", f"文件已合并完成!\n是否打开合并后的文件?"):
try:
os.startfile(output_file_path) # Windows系统
except:
try:
import subprocess
subprocess.call(['xdg-open', output_file_path]) # Linux系统
except:
try:
subprocess.call(['open', output_file_path]) # macOS系统
except:
print("无法自动打开文件,请手动打开。")
if __name__ == "__main__":
merge_text_files()
第 ② 步 数据清洗
本来想直接一发抛给 Gemini 然后递归 Continue. 吐到完的。。结果 Gemini 每轮都大概吐到 7、8 次就不知道串到哪去了。。
所以只能用 Python 拆成小块再发给 Gemini 了 ↓
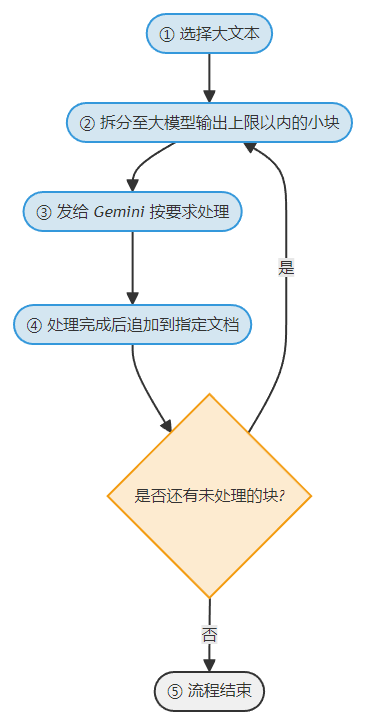
好处是,Gemini 可以直接修正标点符号、和纠正不连贯、错别字那些。缺点不言而喻,如果是重要数据的话始终还是需要转人工的。
Python 源码 ![]()
文件名还没想好.py
import os
import tkinter as tk
from tkinter import filedialog
import re
import time
import vertexai
from vertexai.generative_models import GenerationConfig, GenerativeModel, SafetySetting, HarmCategory, HarmBlockThreshold
# 设置服务账号密钥文件路径
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "(鉴权 JSON,用你自己的).json"
# 设置代理(如果需要)
os.environ.update({'http_proxy': 'http://127.0.0.1:1081', 'https_proxy': 'http://127.0.0.1:1081'})
# 初始化 Vertex AI
vertexai.init(project="(敏感信息屏蔽掉)", location="us-central1")
# 使用 Gemini 模型
model = GenerativeModel("gemini-2.0-pro-exp-02-05")
# 系统提示词
SYSTEM_PROMPT = """请将这些 OCR 的文本数据的标点符号、错别字等修正,并添加适合的换行重新排版以提高阅读舒适度(按纯文本而不是 Markdown 的视觉标准),但是不要添加任何文本数据以外的说明否则会造成自动处理结果混乱。请严格遵循词条 Prompt"""
def select_file():
"""打开文件选择器并返回选择的文件路径"""
root = tk.Tk()
root.withdraw() # 隐藏主窗口
file_path = filedialog.askopenfilename(
title="选择要处理的TXT文件",
filetypes=[("文本文件", "*.txt"), ("所有文件", "*.*")]
)
return file_path
def split_text_into_chunks(text, chunk_size=4096):
"""
将文本分割成大约chunk_size大小的块,在标点符号或空格处分割
"""
chunks = []
start_index = 0
while start_index < len(text):
# 如果剩余文本不足chunk_size,直接作为最后一块
if start_index + chunk_size >= len(text):
chunks.append(text[start_index:])
break
# 从chunk_size位置向前查找合适的分割点
end_index = start_index + chunk_size
# 向前查找标点符号或空格
while end_index > start_index:
if text[end_index] in ",.!?;:,。!?;:\n\r\t ":
end_index += 1 # 包含这个标点符号
break
end_index -= 1
# 如果没找到合适的分割点,就在chunk_size处强制分割
if end_index == start_index:
end_index = start_index + chunk_size
chunks.append(text[start_index:end_index])
start_index = end_index
return chunks
def process_text_with_gemini(text_chunk):
"""使用Gemini处理文本块"""
try:
response = model.generate_content(
f"{SYSTEM_PROMPT}\n\n{text_chunk}",
generation_config=GenerationConfig(
temperature=0.3, # 降低温度以获得更确定性的结果
top_p=0.95,
top_k=40,
max_output_tokens=8192,
),
safety_settings=[
SafetySetting(
category=HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=HarmBlockThreshold.BLOCK_NONE
),
SafetySetting(
category=HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT,
threshold=HarmBlockThreshold.BLOCK_NONE
),
SafetySetting(
category=HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT,
threshold=HarmBlockThreshold.BLOCK_NONE
),
SafetySetting(
category=HarmCategory.HARM_CATEGORY_HARASSMENT,
threshold=HarmBlockThreshold.BLOCK_NONE
)
]
)
return response.text
except Exception as e:
print(f"处理文本块时出错: {e}")
# 如果出错,等待一段时间后重试
time.sleep(5)
return process_text_with_gemini(text_chunk)
def main():
# 选择文件
file_path = select_file()
if not file_path:
print("未选择文件,程序退出")
return
# 获取文件目录和文件名,生成新的输出文件路径
file_dir = os.path.dirname(file_path)
file_name = os.path.basename(file_path)
file_name_without_ext = os.path.splitext(file_name)[0]
output_path = os.path.join(file_dir, f"{file_name_without_ext}_Repair.txt")
# 读取文件内容
try:
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
except UnicodeDecodeError:
# 如果UTF-8解码失败,尝试其他编码
try:
with open(file_path, 'r', encoding='gbk') as f:
text = f.read()
except Exception as e:
print(f"无法读取文件: {e}")
return
# 分割文本
chunks = split_text_into_chunks(text)
total_chunks = len(chunks)
# 创建或清空输出文件
with open(output_path, 'w', encoding='utf-8') as f:
f.write("") # 清空文件
# 处理每个文本块
for i, chunk in enumerate(chunks):
print(f"正在处理第 {i+1}/{total_chunks} 块文本...")
# 使用Gemini处理文本
processed_text = process_text_with_gemini(chunk)
# 将处理后的文本追加到输出文件
with open(output_path, 'a', encoding='utf-8') as f:
f.write(processed_text)
# 如果不是最后一块,且处理后的文本末尾没有换行符,添加一个换行符
if i < total_chunks - 1 and not processed_text.endswith('\n'):
f.write('\n')
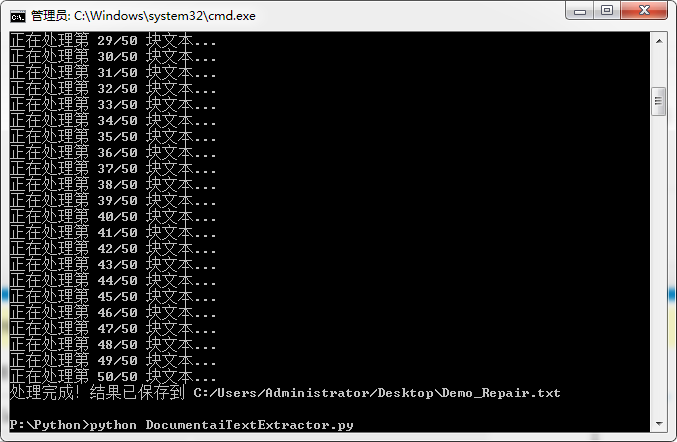
print(f"处理完成!结果已保存到 {output_path}")
if __name__ == "__main__":
main()
第 ③ 步 排版优化
(\ _ /)
( ・-・)
/っ ![]() 简而言之就是用正则统一下换行那些,就不赘述了。
简而言之就是用正则统一下换行那些,就不赘述了。
最终效果 ↓↓↓
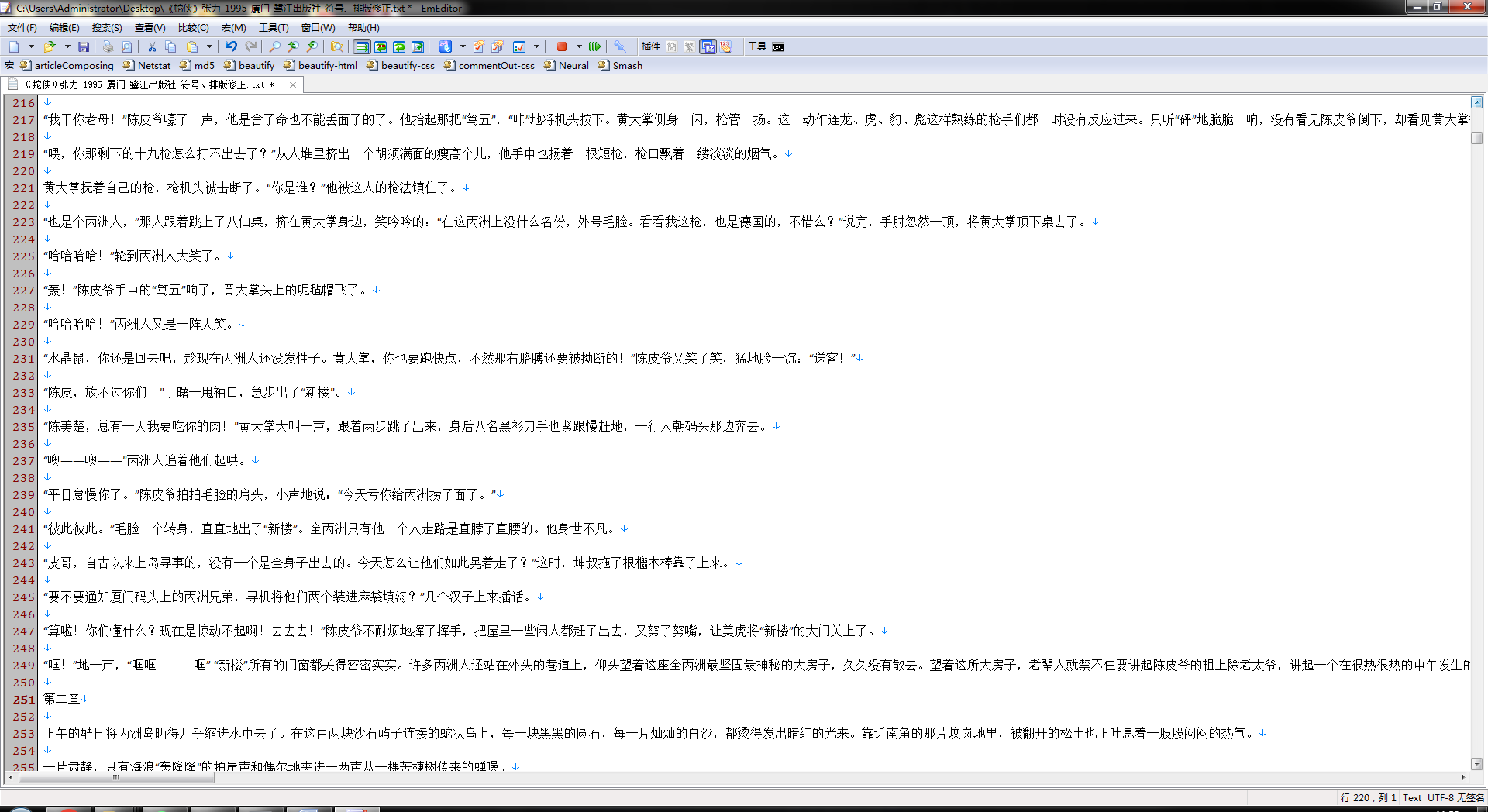
标题那些还可以用正则进一步统一美化下,But, 就这样吧。
《蛇侠》张力-1995-厦门-鹭江出版社-符号、排版修正.txt (606.7 KB)