Qiner
(林黛玉倒拔垂杨柳)
1
(\ _ /)
( ・-・)
/っ  就是,前两天刨了个新玩意 Document AI
就是,前两天刨了个新玩意 Document AI 
 【实践向】(๑•̀ㅂ•́)و✧ 用 Document AI 成功转录 403 页纯图扫描 PDF!
【实践向】(๑•̀ㅂ•́)و✧ 用 Document AI 成功转录 403 页纯图扫描 PDF!
 【GCP刨土系列】Document AI 带坐标的 OCR 识别
【GCP刨土系列】Document AI 带坐标的 OCR 识别
然后发现好像还有别的用途。
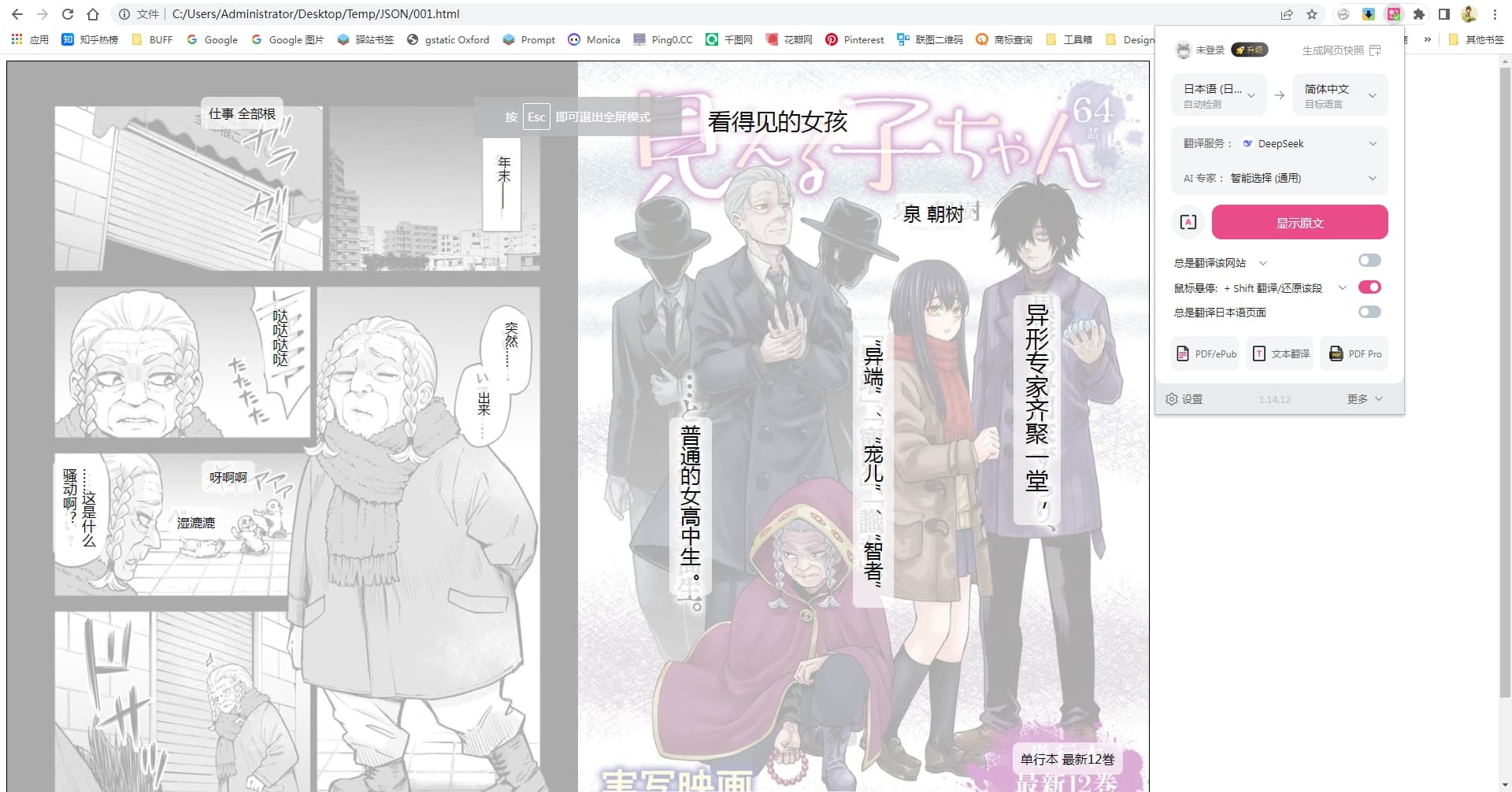
于是就拿今天(东京时间 2025/02/28 12:00)更新的 《見える子ちゃん》 试试。
① 首先去 JP 网站把生肉顺下来:
② 然后用上面帖子提到的脚本批量转录一下:
pā 的一下就好了,很快 á!
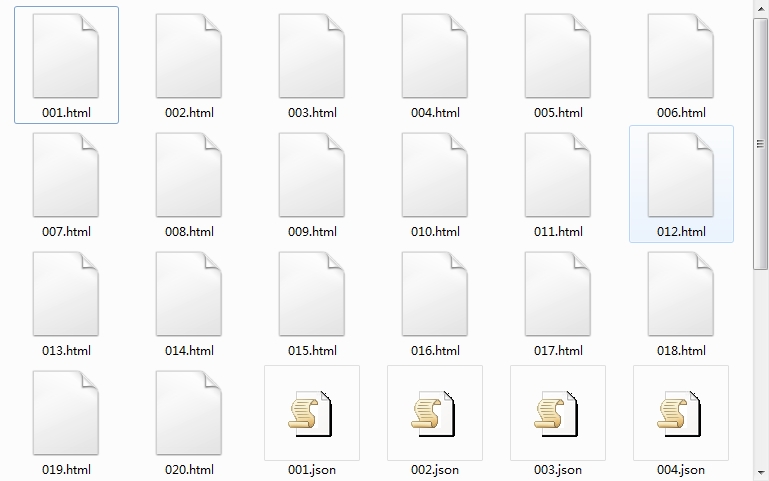
然后得到一堆 html 文件
③ 双击打开是这样的,自带坐标
我在原贴脚本基础上加了:
- DIV 可编辑
- 拖拽 DIV 重叠合并
- 拖拽缩放文本
- 横竖版切换
少量识别断开的拖动一下合并就好
④ 然后上膛 —— 沉浸式翻译走起。。
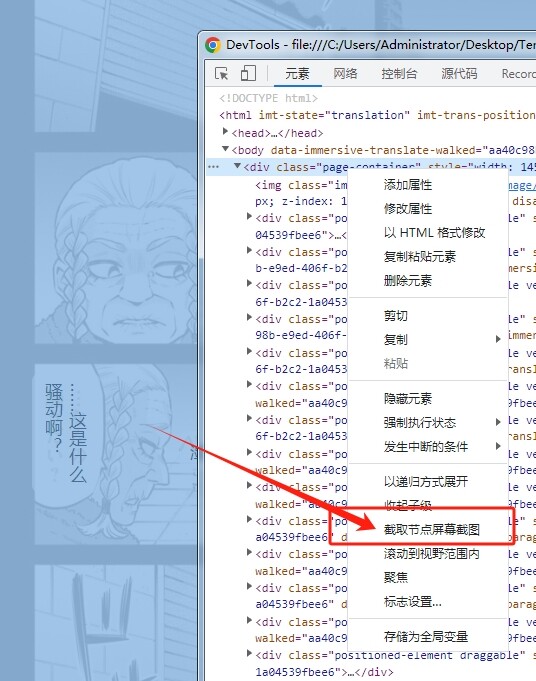
⑤ 然后逐一右键导出画布就好
↺ 重复上述步骤。
成品:見える子ちゃん 64 机翻.zip (3.6 MB)
为了提高文本可读性把底图透明度调低了,高清版就留给真汉化组吧。
24 个赞
好东西啊,不过要一页一页来翻译还是效率低了点,要是能批量自动处理就舒服了
Qiner
(林黛玉倒拔垂杨柳)
5
 要求不高的话一已经是批处理了,到一键导出 html 那步就可以一键沉浸式翻译了自己追番的话。后面的修正导出是导给群友的
要求不高的话一已经是批处理了,到一键导出 html 那步就可以一键沉浸式翻译了自己追番的话。后面的修正导出是导给群友的
Qiner
(林黛玉倒拔垂杨柳)
6
不知道价格的说,反正那 403 页的 PDF 处理完大概 $1 左右。
90_cpx
(90 cpx)
8
我在想 能不能用glm 4v免费额度来识别定位文字 这玩意额度贼大
Qiner
(林黛玉倒拔垂杨柳)
9
@Lush @xdh211985 上班呢 bro。尽量别发私信我把论坛私聊功能都关了,我不是热佬我是水逼,有空看到就回现在闭关工作。
2 个赞
Qiner
(林黛玉倒拔垂杨柳)
11
Google 在多模态普及之前就已经有物体标注了,常规多模态应该没训练过这方面。
elfmaid
(Elf)
13
我勒个豆 你也追看得见的女孩啊
你可以看看昨天更新生肉后,我做的熟肉的
【图片】64话 嵌字汉化熟肉【看得见的女孩吧】_百度贴吧
3 个赞
elfmaid
(Elf)
15
啊 没有啊, 我从不加群
我汉化纯粹是因为喜欢这部作品,为啥加群 。
我之前已经汉化了62,63话了,我都是发在贴吧,热度还可以。。
我上个月做的63话熟肉,我看别人上传到拷贝漫画去了(我甚至还在禁漫看到我做的熟肉)
1 个赞
Qiner
(林黛玉倒拔垂杨柳)
16
哦哦,我是单行本还没发售之前看到贴吧有发【猎奇向】贴开始入局的,但没怎么追,就随缘看群友什么时候搬运过来了就看看
1 个赞
elfmaid
(Elf)
19
你追的话 我后面每次更新都踢你一下
看得见的女孩,这几个月这几话,我都是最快出熟肉的(现在都没人汉化了不知道为什么)
2 个赞
Qiner
(林黛玉倒拔垂杨柳)
20
从猎奇回归日常就没热度了,最开始是吧主汉化后来被举报到封 Q 好久就怂了后来就不发汉化了。
妥
2 个赞