 不做任何修改,默认4K截断
不做任何修改,默认4K截断
 调整
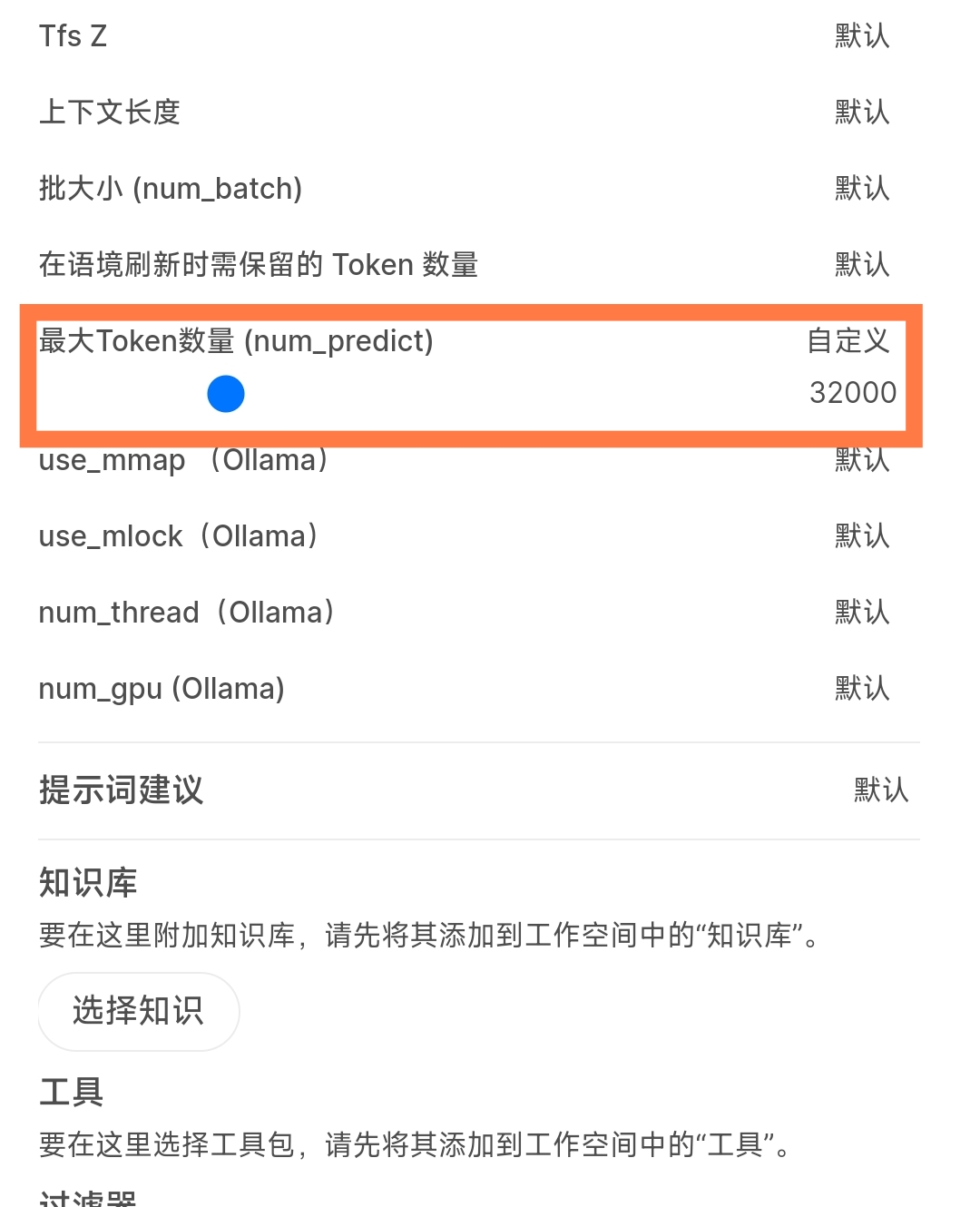
调整max token为32768会报错,发现实际能设置的max token=32768-提示-问题
 设置
设置max token=32000,测试 @yeahhe 佬题库的这个题目
在平面四边形ABCD中,AB = AC = CD = 1,\angle ADC = 30^{\circ},\angle DAB = 120^{\circ}。将\triangle ACD沿AC翻折至\triangle ACP,其中P为动点。 求二面角A - CP - B的余弦值的最小值。
经过数十次测试下来,截断长度在6000-13600 tokens不等,平均8500tokens,虽然远不及设定的32000,但是至少能比默认的4K强得多,完成绝大多数题目没什么问题
顺便附上Open WebUI的设置
 题外话
题外话
顺便提一嘴,DeepSeek V3/R1都是8K,但默认为4K,根本就没法用,推荐设置为8000;Fireworks可以设置为164K,能把这道题做出来,与默认的2K差别很大