新特性
尝试模型优选:发起请求时,会将模型本次的请求结果及首token rt存入redis,下次发起请求时,会基于历史72小时的请求结果,优先选择rt更低,成功率更高的服务商
断路器:当某个服务商的某个模型连续调用失败时,会进入冷却期,冷却期内,此模型不会进入候选列表,以提高上游调用稳定性。
尝试优化流式展示效果:
参考了 時価ネット田中佬的帖子。感觉优化一下看着是挺好看。
做了一个流的异步消费,下游流式消息直接push到队列中,另一个consumer负责从队列读取,并根据消费的时间和吐出的字符数,动态调整输出速度。如果下游输出完成,不做任何延迟,直接全输出。
原帖:
注意
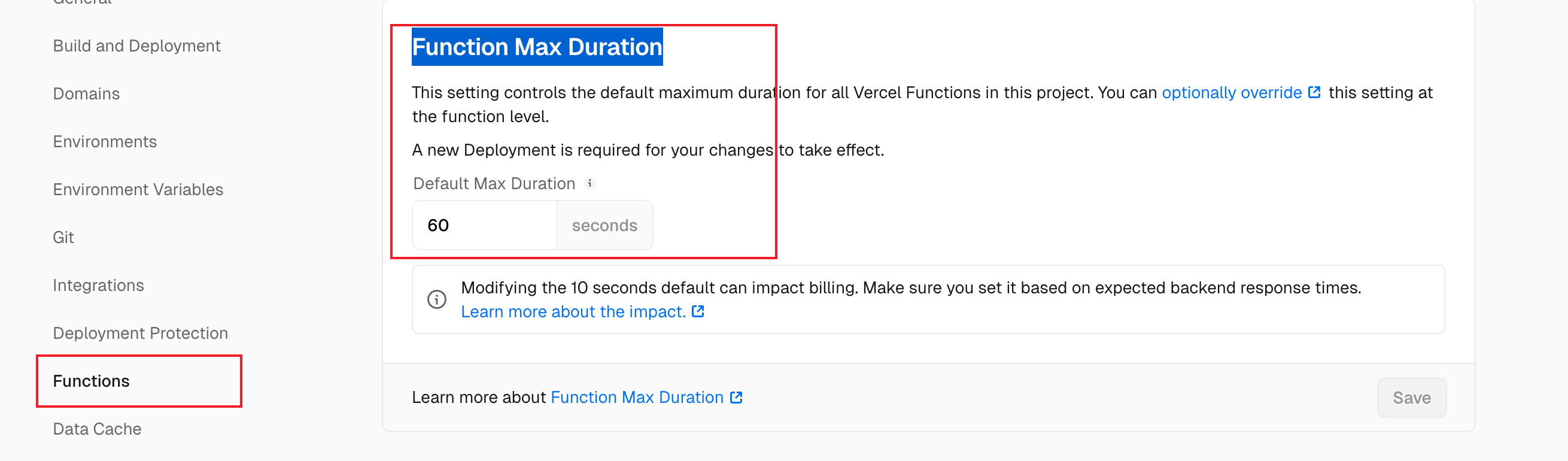
vercel的免费版最多执行60s 
如果有用付费版的,可以自己把这里的超时时间改成300或者更长
原内容
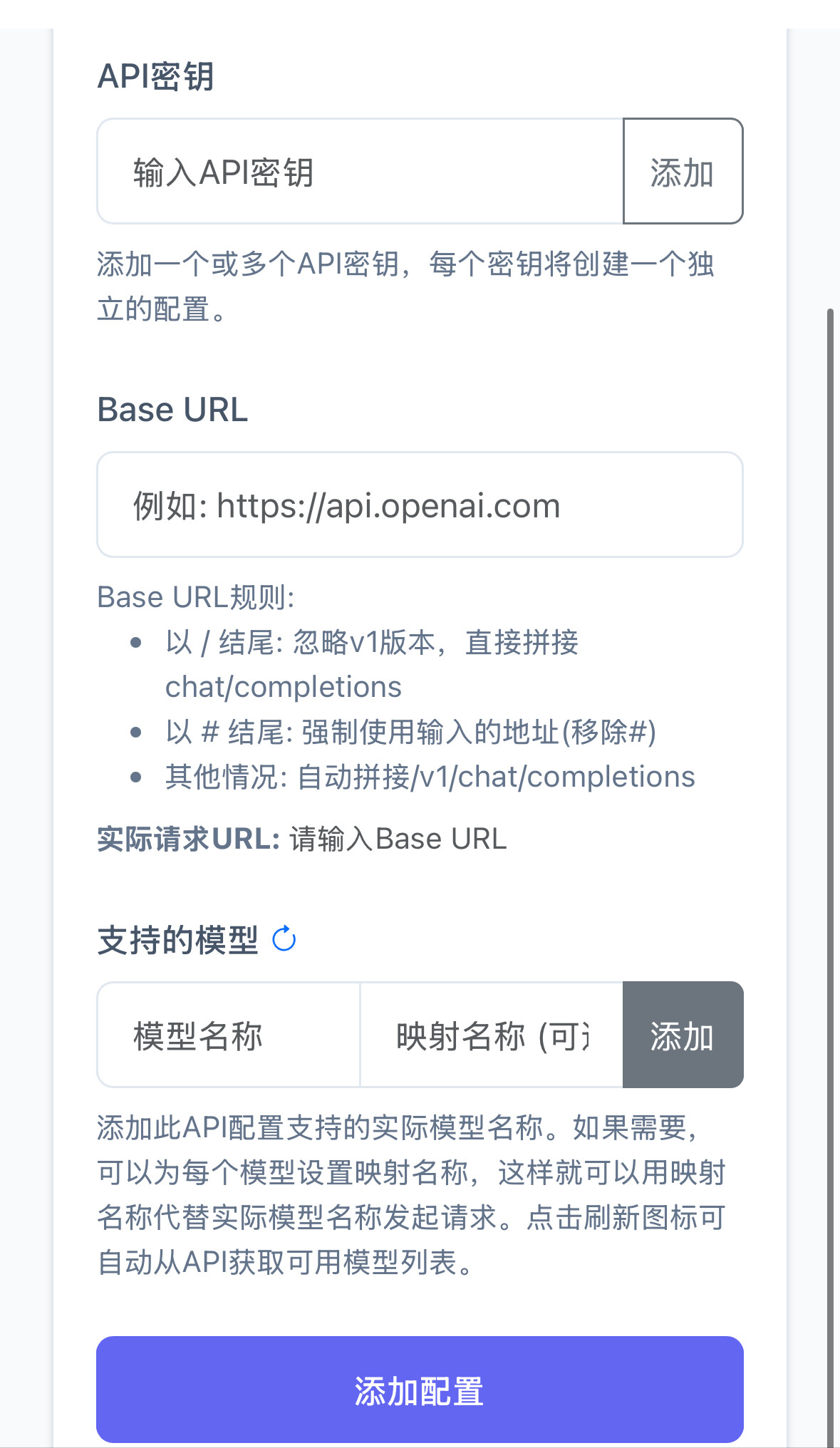
搞着玩用cursor搓了一个,支持openai格式调用,支持v1/models获取模型列表
支持模型名映射(薅的站点模型名不一样太烦了,通通给我映射掉)
支持一键获取上游模型列表
vercal一键部署,readme里写了部署教程。主要自己用着玩,直接环境变量里配置key吧。
效果图
git仓库:GitHub - zhangtyzzz/uni-api: 简易版api集合器
喜欢的拿去玩,点个星星就更好了嘿嘿
55 个赞
cyc
4
感谢分享,请问如果将多个来源的模型设置成同名会怎么样呀,会自动检测哪个模型可用吗
1 个赞
好像有 10s 的限制呀,回答到到一半就停了,而且时间好短,时间设定是 60呀
我试试  ,还真没试回答很长的推理模型,就让cursor给了个环境变量hh
,还真没试回答很长的推理模型,就让cursor给了个环境变量hh
在 Vercel 的 Serverless 函数(API Routes)中,不同的环境有不同的最大执行时间:
• Hobby(免费计划) : 最大 10 秒
• Pro 及以上(付费计划) : 最大 60 秒
• Edge Functions : 最大 30 秒
完犊子了
测了半天真是 10 秒左右,有没有其它突破。。。
啊这= =,我研究研究看看别的,我是给它丢sider插件里用的,配的都是非推理模型,倒也凑活用。推理模型的话,10s也忒短了。
1 个赞
赞!
1 分钟也行吧,但是没有 CF worker 的时长,佬后续也可以考虑多几个平台玩玩