先说结论 —— 上下文越充足,翻译越精准!
(\ _ /)
( ・-・)
/っ ![]() 举个栗子,【草】的翻译:
举个栗子,【草】的翻译:
- 草 —— Grass
- 我草 —— FUCK
- 草泥马 —— Alpaca
- 潦潦草草 —— Perfunctorily
上下文不同,含义截然不同。同时上下文充足的情况下错字亦可自带修正。
然后先说说沉浸式翻译最核心的 3 个设置项:
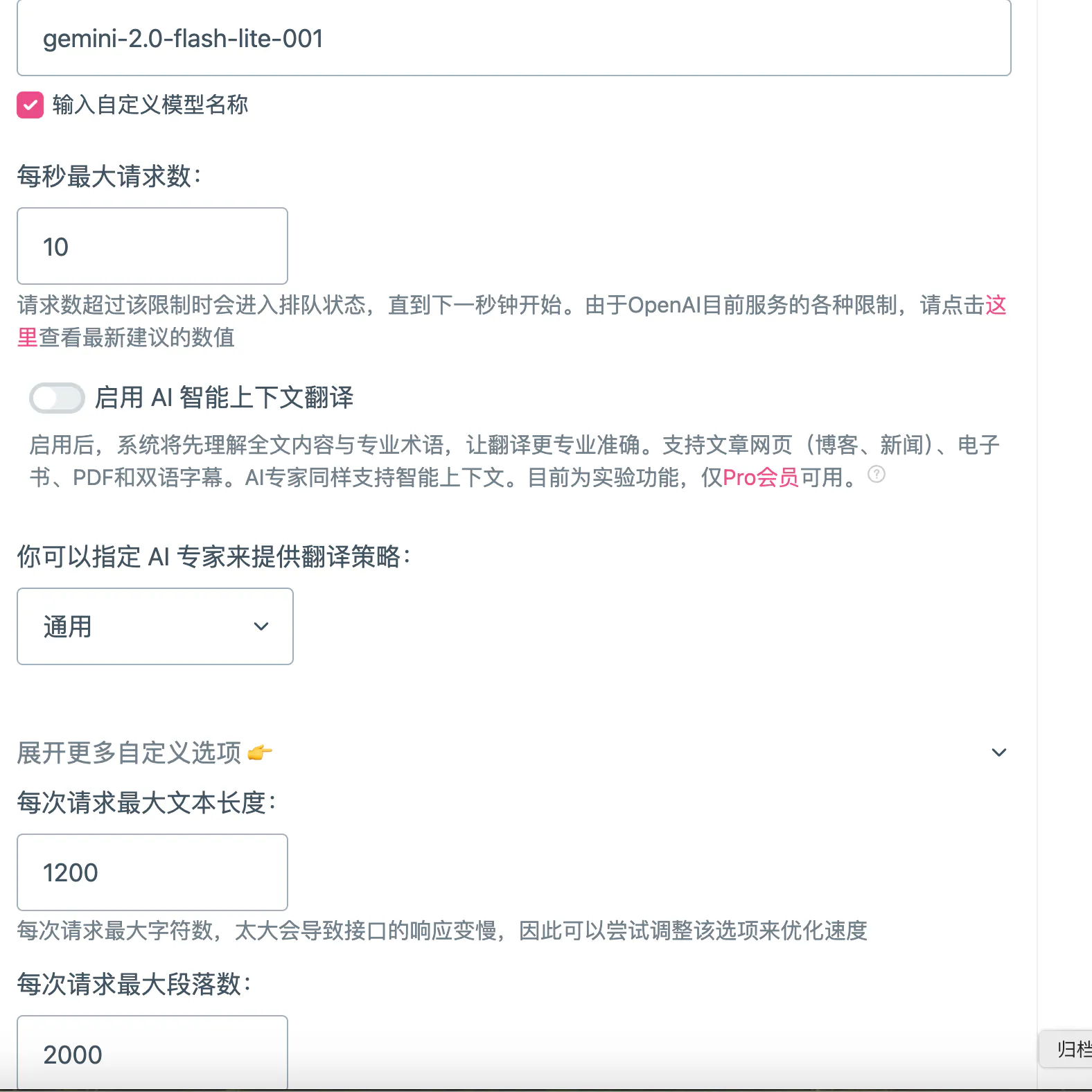
① 核心「每次请求最大文本长度」
简单的说,如果你设置为 1,那就连 apple 都给你劈成 5 个字母独立请求发送 (另外有这个下限设置,意思一样) ,那翻译个蛋。所以这项无论任何情景都建议往高设置。
②「每次请求最大段落数」
字面意思,段落越长,上下文越充足,速度也越慢。
如果设置小那效果就像 流式输出 那样网页肉眼可见地一个个在变化;如果设置太大那就是漫长的等待然后一瞬间全页变中文。
③「每秒最大请求数」
就是每秒发送的请求数量,即 — 并发。一般模型都是按 rpm 算,只能设个大概,Grok 比较特殊是按 rps 算直接输入最高配额 4 就行。
然后有个很特别的模型 —— Gemini Flash Lite ![]()
重要!! Gemini 似乎把沉浸式的 Prompt 标记了很容易触发 429,实测把 Prompt 全部换成中文适当改差异,果然又可以一泻千里了。
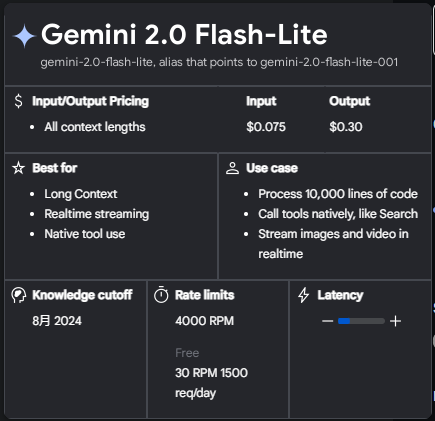
4000 rpm!!!(gcp/付费渠道 4000,free渠道 30)所以刚出那会就赶紧体验了下,把段落拉到最小、每秒请求数拉到爆炸! —— 确实,网页仅一瞬间就腹泻般地变成了全中文。
(\ _ /)
( ・-・)
/っ ![]() 但是当时并未意识到,这一举动大大降低了一些场景的翻译质量。直到昨晚看到了这个
但是当时并未意识到,这一举动大大降低了一些场景的翻译质量。直到昨晚看到了这个 ![]()

翻译得地不地道不是学历决定的、不是权威决定的、更不是什么神级通用 Prompt 能左右的,而是 对故事足够的了解 —— 即 足够的上下文。
所以沉浸式翻译推出了一个仅限 Pro 使用的「启用 AI 智能上下文翻译」。
(╯°□°)╯ 不是哥们,我想说的是你直接把段落数拉满效果是一样的,都是 全部上下文。。
然后这是之前那个 Document AI OCR 的漫画(html) ![]()

这是沉浸式翻译段落设置为 1 的 Grok ![]()

然后我把段落数量拉满,并且先把整集的原文投喂到 Prompt 里 ↓

再次网页翻译的效果:

(\ _ /)
( ・-・)
/っ ![]() 嗯。
嗯。
回到标题 ↓
提高翻译质量的关键就是 调大「每次请求最大段落数」
就这么简单。用速度换质量。
然后沉浸式翻译可以添加多个翻译渠道 ![]()
不同场景切不同的渠道就好,像网页按钮翻译那种仍然可以用极速 Gemini 享受极致的窜稀体验。