参数
1m上下文(未来支持2m),64k输出(含推理),与2.0flash-thinking基本一样
支持搜索
多模态,支持识别图片,音频,视频
暂不支持画图,视频生成,音频生成,缓存
训练知识:截止到25年1月
推理过程:自动控制推理长度
如果简单的事实性问题,推理非常短非常快,速度与非推理模型相近
用英文推理,显示全部推理过程
与其他推理模型有个区别,2.5pro有时候可以同时输出搜索或推理过程和结果,而不需要等全部推理完。动态根据推理过程修改结果
暂时只有exp版,免费,没有正式版,所以也没有API价格
API Free Tier每天限50次,2RPM
Chat版普号暂没有2.5pro,可以免费升级Advanced会员一个月试用
Advanced会员貌似不限量
来源:Gemini 2.5: Our newest Gemini model with thinking
为什么2.0-pro正式版不出,就直接2.5-pro了?
我猜现在grok3,claude3.7,gpt5都明确是非推理+推理混合模型了,这已经是大势所趋,非推理的2.0-pro正式版,即便出来了也是落伍,2.0-pro-exp性能现在也没有优势了,用户对他也没有好奇心了,exp了好几个月,最佳上线时机已经错过了,google干脆一步到位,就上混合模型叫2.5-pro了,所以应该也不会再有2.0-pro正式版,2.0-pro-thinking或2.5-pro-thinking了
在Advanced会员中,2.0-pro-exp已经被下架了
渠道
2.5pro几天前就已经在Lmarena上,以Nebula的代号,匿名上线了
当时不能在Direct talk里选,也不显示在排行榜里,但是在AB盲测时,AI回答完,用户选择哪个较好之后,会显示模型名字,就有一定几率碰到Nebula
提问“你是谁”,可以证明是Google的推理模型
之前被认为是Gemini-2.0-pro-thinking,现在看应该是2.5-pro
Gemini Advanced会员里250325开始灰度推送,250326凌晨全部推送

如果普号没有Advanced会员,可以申请试用一个月,或者使用AI Studio
AI Studio里250326凌晨已上线
应该是所有人都有,不用灰度推送
官网API 250326凌晨已上线
Lmarena Direct Chat已上线
OpenRouter250326凌晨2点已上线(免费)
来源:OpenRouter
评分
官方发的评分
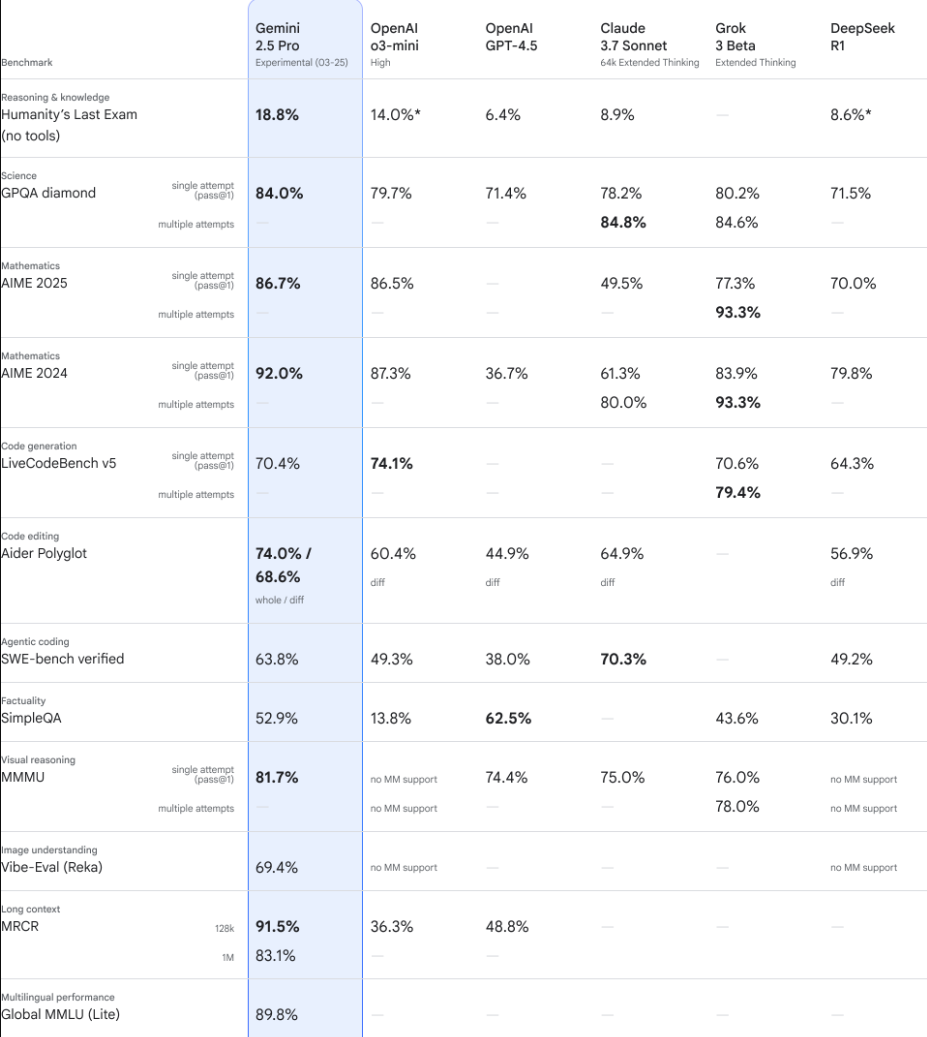
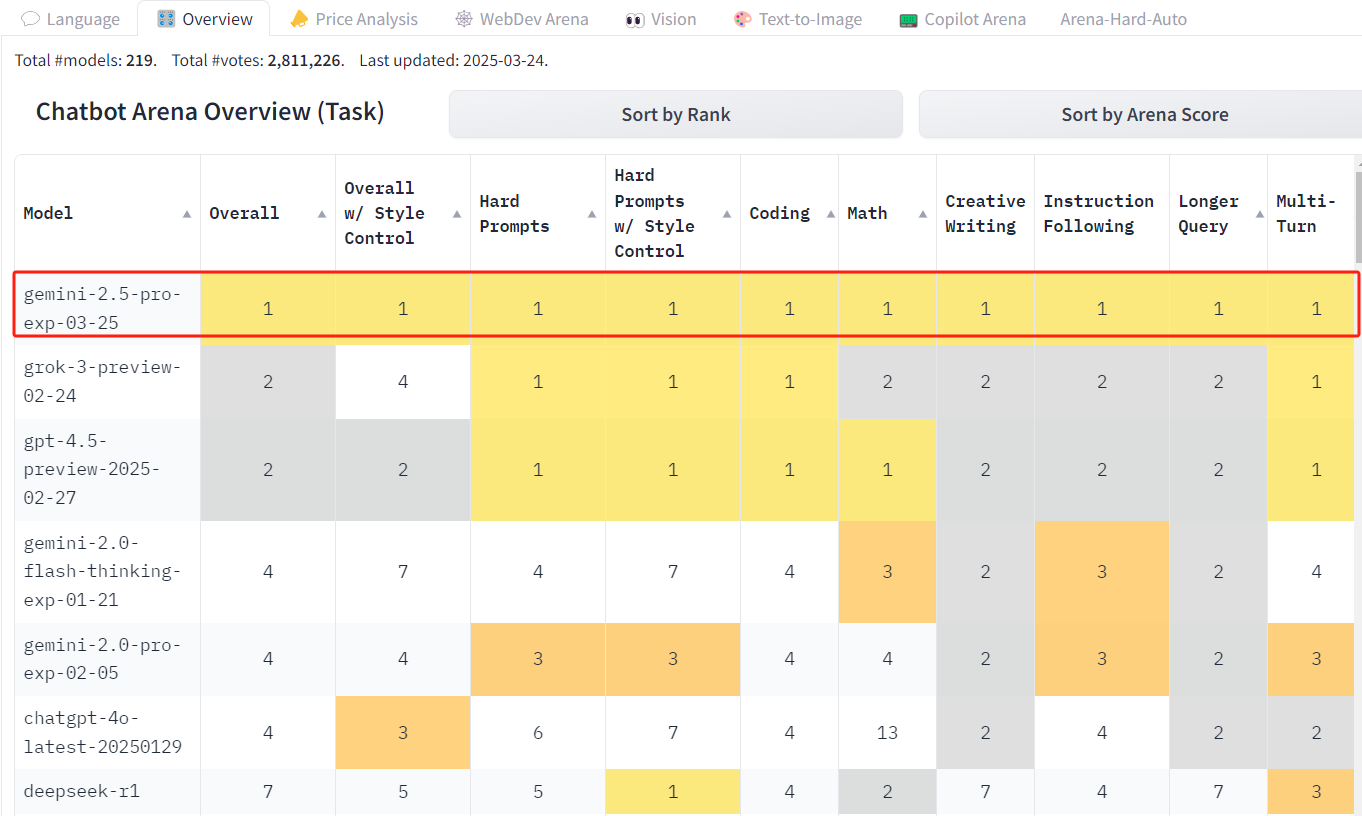
Lmarena评分
总榜第一,断档领先第二名39分
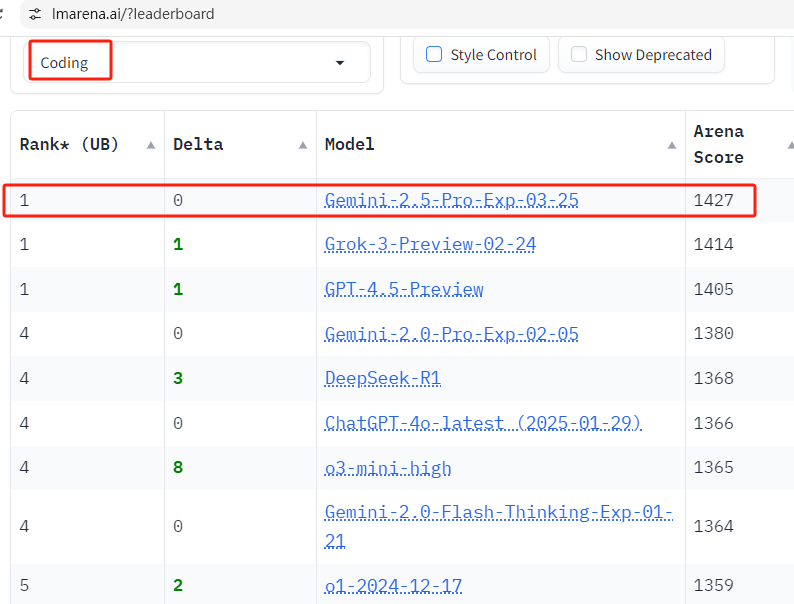
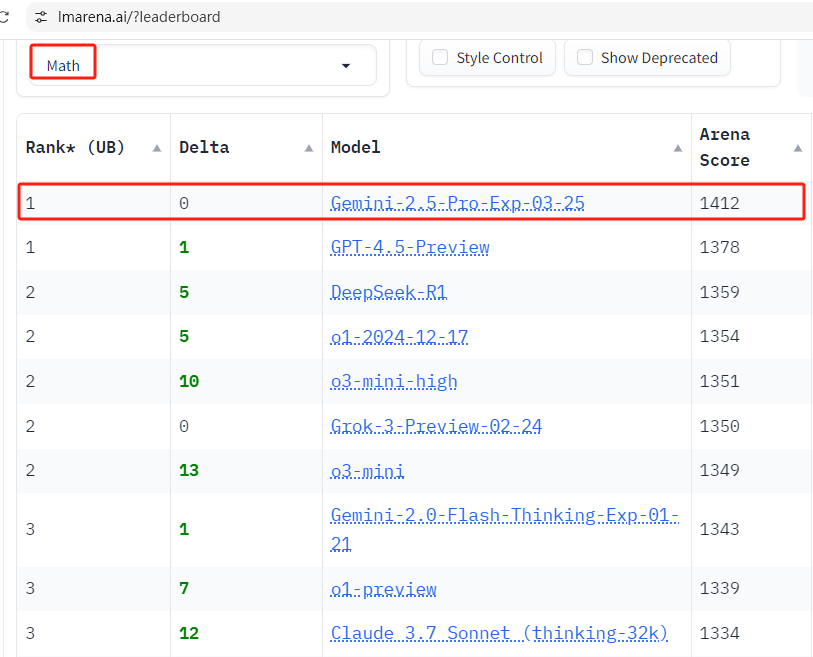
所有单项榜也都是第一,有点猛
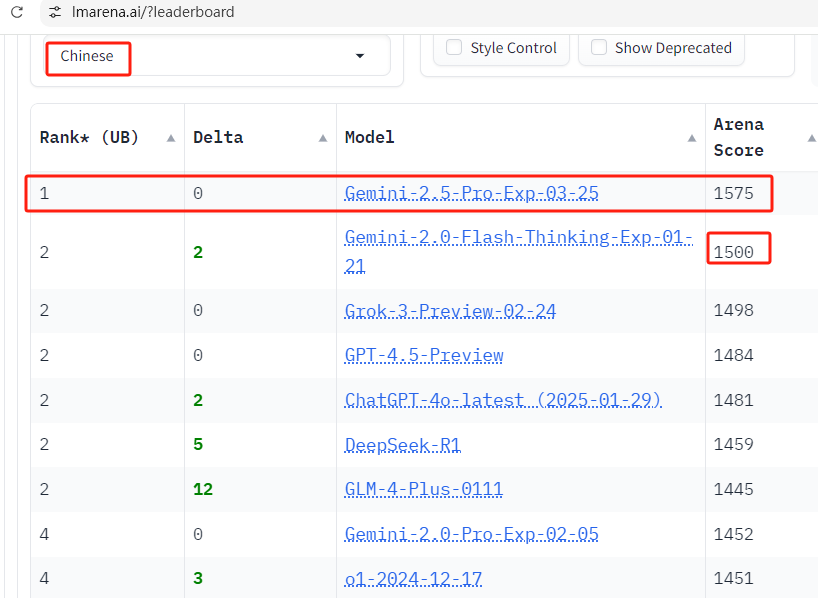
中文比第二名多75分,相当于第2名和第13名之间的分数差值
来源:https://lmarena.ai/?leaderboard

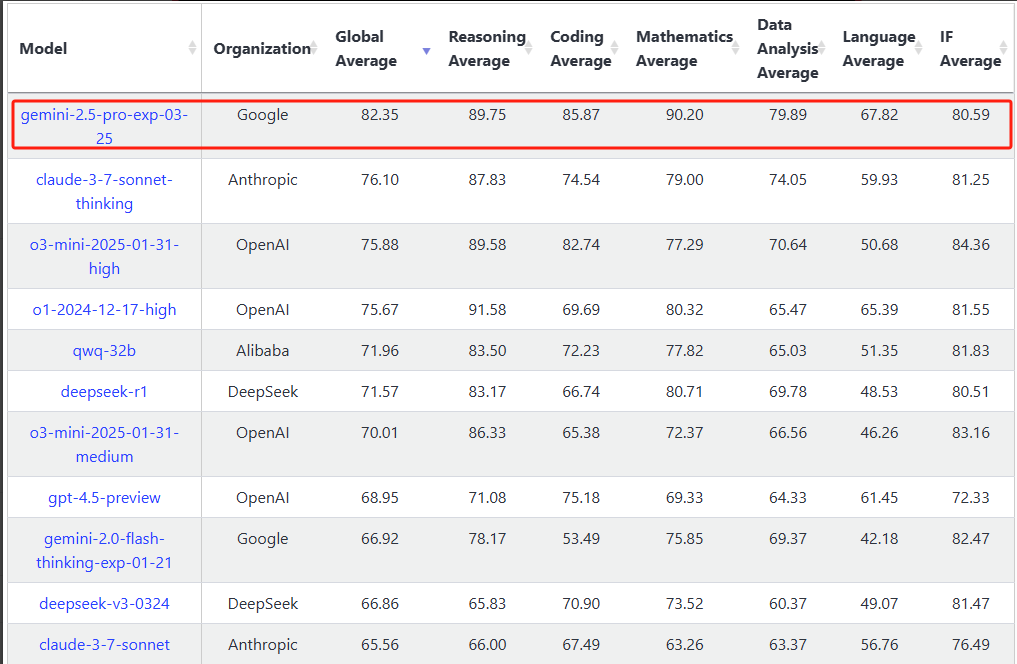
Livebench断崖式第一 250327 0:10更新
佬友Mozi的区分题库,2.5pro全答对
来源:区分题库已经完成对Gemini 2.5 Pro的测试,结果为全对,2.5Pro在未来Livebench的成绩应该会很亮眼
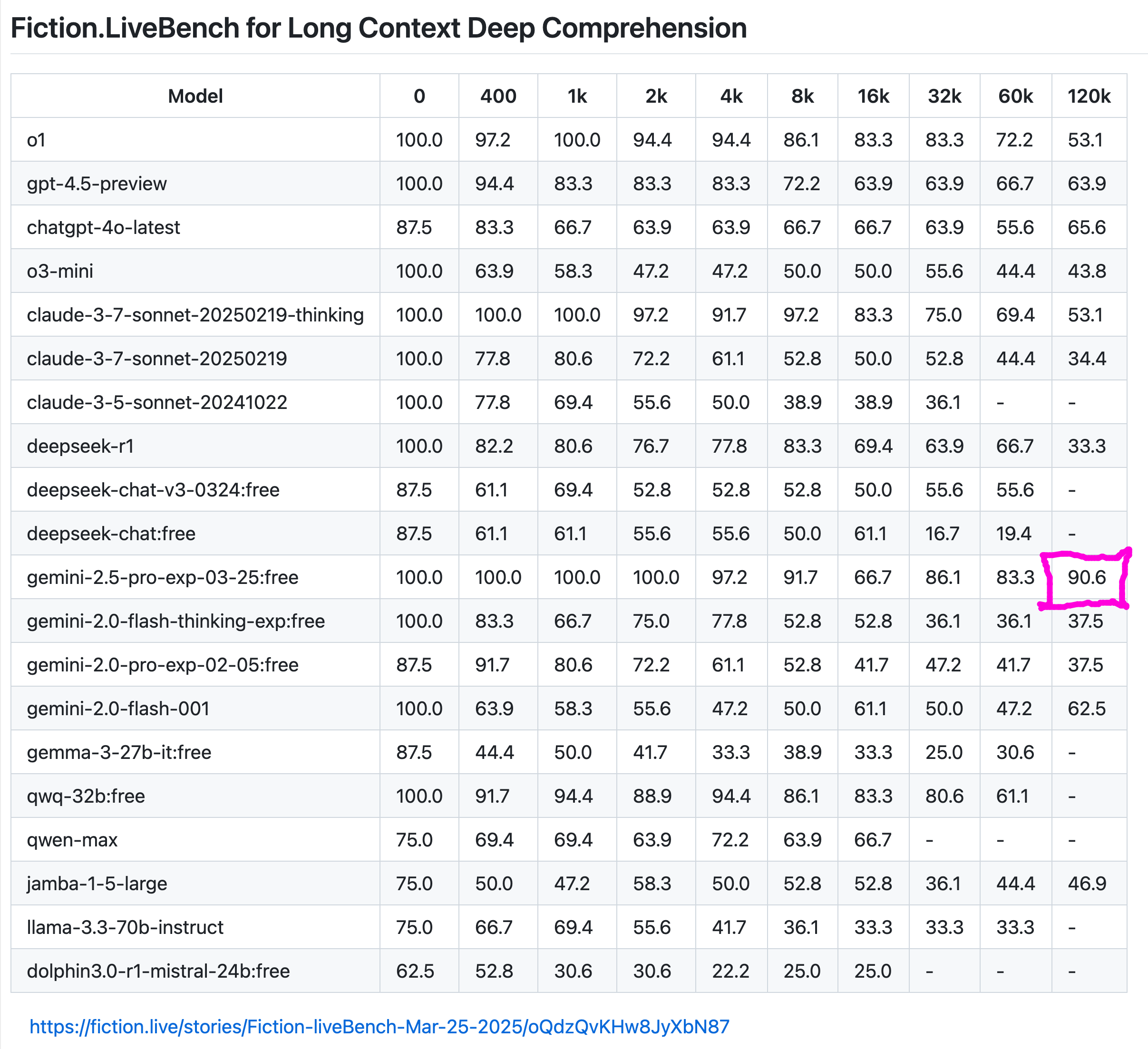
fiction.live长上下文性能抗衰减能力评分,250326 11:00更新
所有大模型的性能都会随上下文增加而衰减,但衰减速度不同
2.5pro在120k(约12万字)上下文时性能保持率,也是断崖式第一
来源:Fiction.live
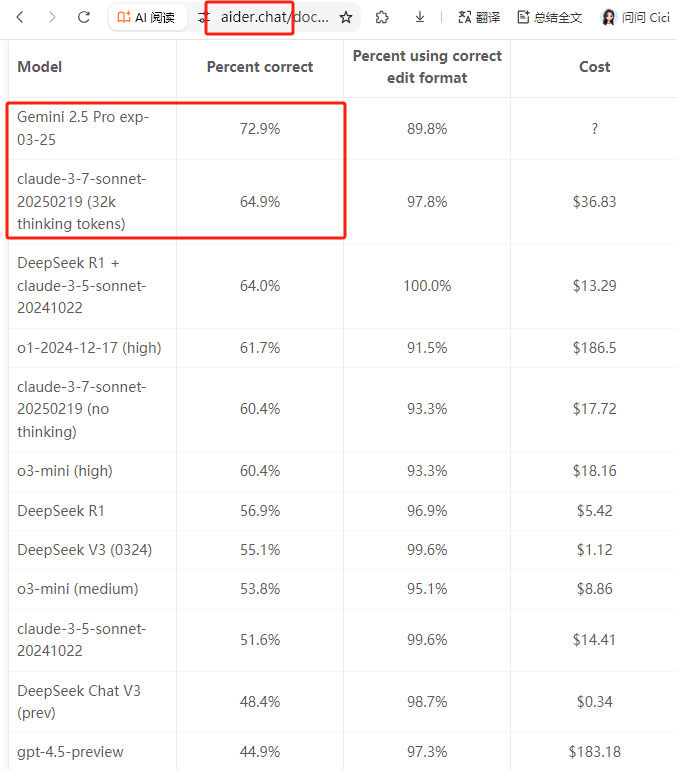
aider编程评分,250326 11:15更新
来源:Aider LLM Leaderboards | aider
佬友PSP的AI天梯图,加入2.5pro
来源:大模型综合性能天梯定位表,个人主观看法(已更新Gemini-2.5-Pro-Exp-0325,GPT-4o-0328)
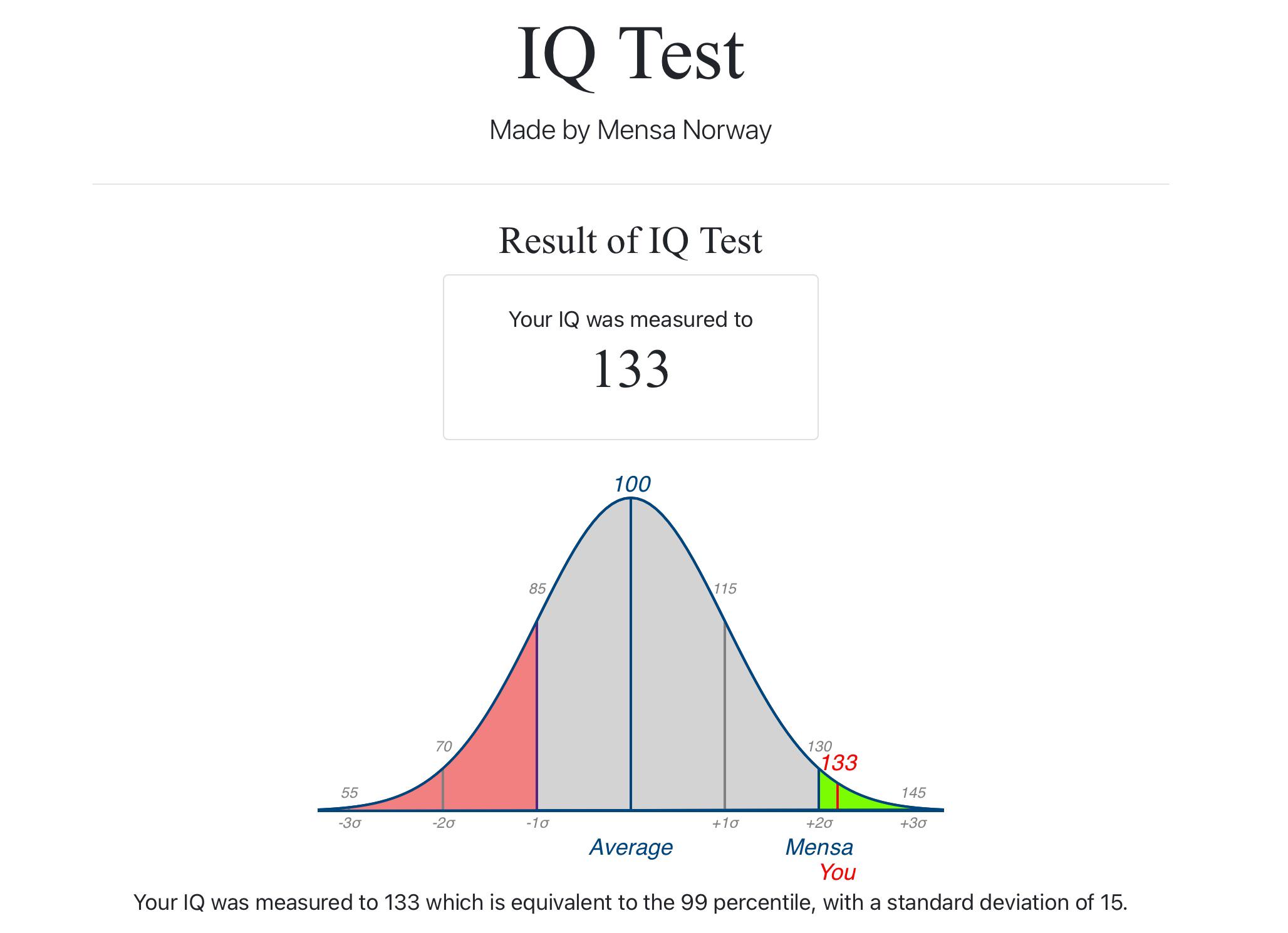
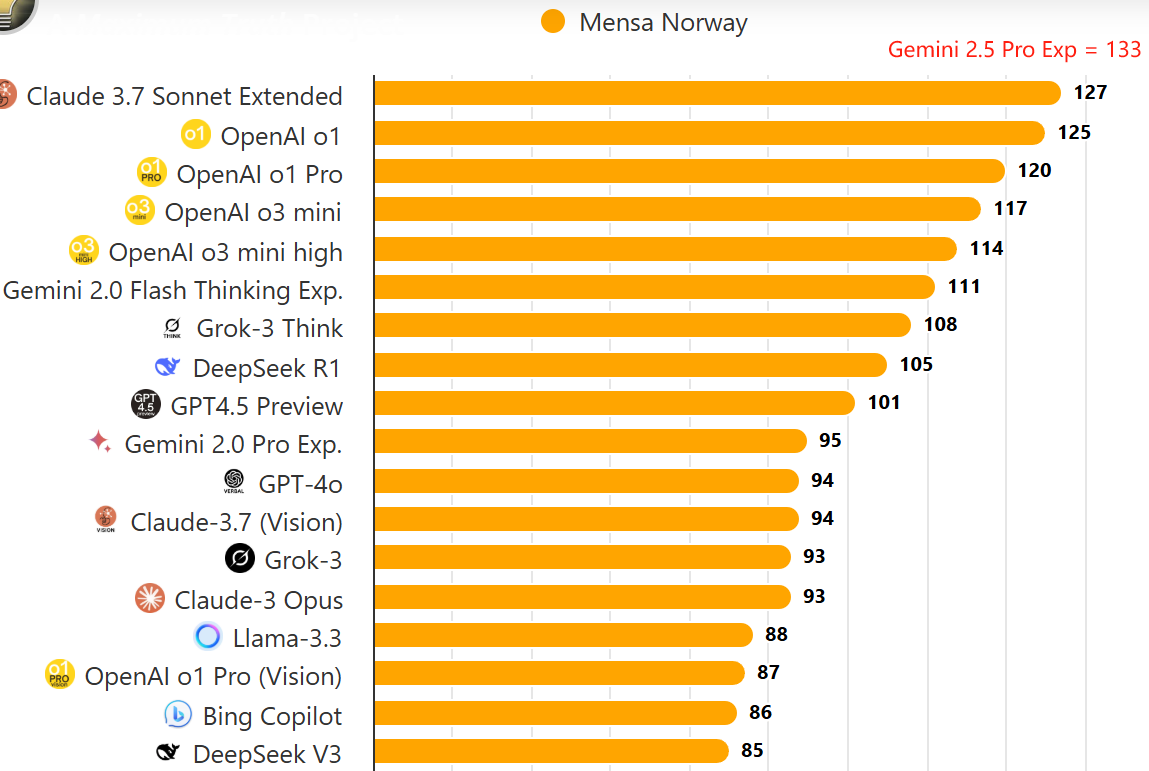
门萨智商测试(Mensa Norway)分数 250326 12:00更新
智商测试网站嘛,看个乐子,不要太较真,与AGI什么的没太大关系
人与人可以比智商,AI与AI可以比智商,人和AI智力不是一种类型,不好直接比较
这个网站有两种测试结果,一种Mensa Norway在线测试,一种Offline测试
Offline的IQ比Mensa Norway的分数普遍低很多,原因不明
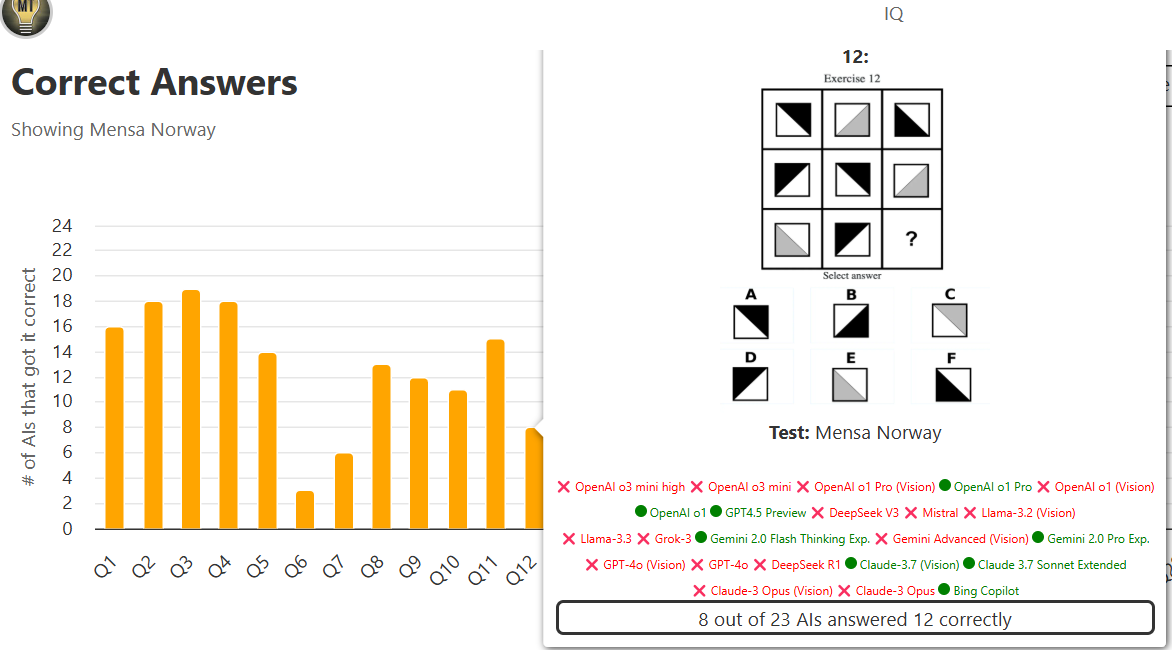
一共36题,每道题都会统计各个模型能否作对
一般测试几次取平均值,结果可能有一定的随机性
音视频识别能力测试 250326 13:00更新
试了下中文没有软字幕(即作者没有上传字幕文件)的视频,应该是语音识别,识别8分钟需要1分钟,识别准确率挺高的
2.5pro实际最大输出问题,250326 15:00更新
以下是个人测试,官方并没有明确说明,如有不符,感谢指正
一般思考模型的输出是硬性划分推理token数和最终输出token数的
比如r1总输出上限是24ktokens,是硬性预留16k推理token的,最终输出上限实际只能达到8k,哪怕思考只有1k,也不会增加最终输出token上限
同理o3-mini和o1总输出100k,最终输出上限硬性16k
2.0flash-thinking总输出64k,最终输出上限硬性24k
但是3.7和2.5pro貌似是弹性划分思考和最终输出token数的,就是只要token总数不超标,推理token和最终输出token没有硬性预留
3.7输出是弹线划分64k(貌似参数换beta版模型后,可以128k)
2.5pro输出貌似是弹线划分64k
刚才AIStudio做了个测试,输入一整本书(11万字),要求一字不差复述,这种完全没有推理token,只有最终输出,输出到64kt处截断
大输出的用途
翻译:一本十万字的书,2.5pro或3.7一次输出5万字,两次就翻译完了,其他模型只有比如8k输出,10万字要一直"继续"13次,每两次"继续"之间还要等他输出几分钟,一共可能要"继续"个半小时到一小时
如果用api的话,继续13次等于上传13次原文,token消耗就是13倍,浪费严重(除非你做原文切割可以减少token浪费)
超长代码输出
超长写作:比如写小说
深度研究
比如以前1.5pro和2.0flash-thinking的深度研究一般只有几千字,o3 Deep research是1.5~2万字,先不说质量,就字数都差了好几倍
等到Gemini Deep research换了2.5pro之后,理论上输出字数和质量都可以大幅提升
实际上佬友PSP直接用2.5pro模拟深度研究,输入用深度研究提示词,输出也能有一万多字,而且质量比2.0flash-thinking的Deep research还要高,毕竟底模差距摆在那
来源:https://linux.do/t/topic/514059
哪个版本是满血版测试 250326 18:00更新
结论:AIStudio能稳定输出64kt
API加参数后,最多能输出60kt但有时会截断,不如AIStudio输出稳定
方法:输入一本书,11万字中文(80ktokens),要求翻译英文,提示词相同
Gemini网页版
第一次思考5k单词,最终输出19k单词截断,总输出24k单词(约32kt)
第二次思考2k单词,最终输出23k单词截断,总输出25k单词(约32kt)
截断没有任何提示,按钮一直是方块状态
各大模型,通常Chat版的上下文和最大输出,都少于API,2.5pro的Chat版能输出这么多,已经很好了。其他模型chat版一般最终输出最大也就4~8k左右
AIStudio
使用默认设置
第一次输出思考10k单词,最终输出40k单词截断,合计50k单词(约64kt),600s
第一次输出思考5k单词,最终输出46k单词截断,合计51k单词(约64kt),566s
截断有时显示internal error或exceed quota,有时不显示
官网API+Cherry
Ⓐ默认设置:8k截断
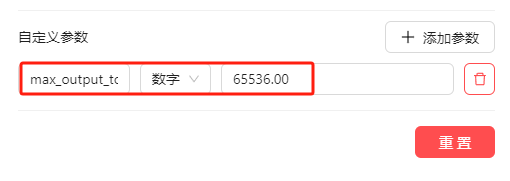
Ⓑ加max_output_tokens=65536参数:可以输出61ktokens,但有时503错误
OpenRouter API+Cherry
Ⓐ默认设置:Cherry不显示思考过程,总输出16ktokens
Ⓑ加max_output_tokens=65536参数:可以输出61ktokens,
但OpenRouter输出不太稳定,有时4k也会截断
另外不能连续提问,提问一次之后要等几分钟。容易显示429或524错误


