


- 本次先用金主的网站渡过难关,还是希望能找到个合适的
- 小弟自研的一款PDF的翻译网站,会员限时免费送(已更新4.0版本)
5 个赞
蹲一个答案
2 个赞
ocr 覆盖
1 个赞
试试pdfmathtranslate
1 个赞
佬友细说,只知道OCR识别,覆盖第一次听说,刚也没查到
1 个赞
我用过这个挺好用的,上传之后,自动翻译,可以下载双语对照或者纯中文
1 个赞
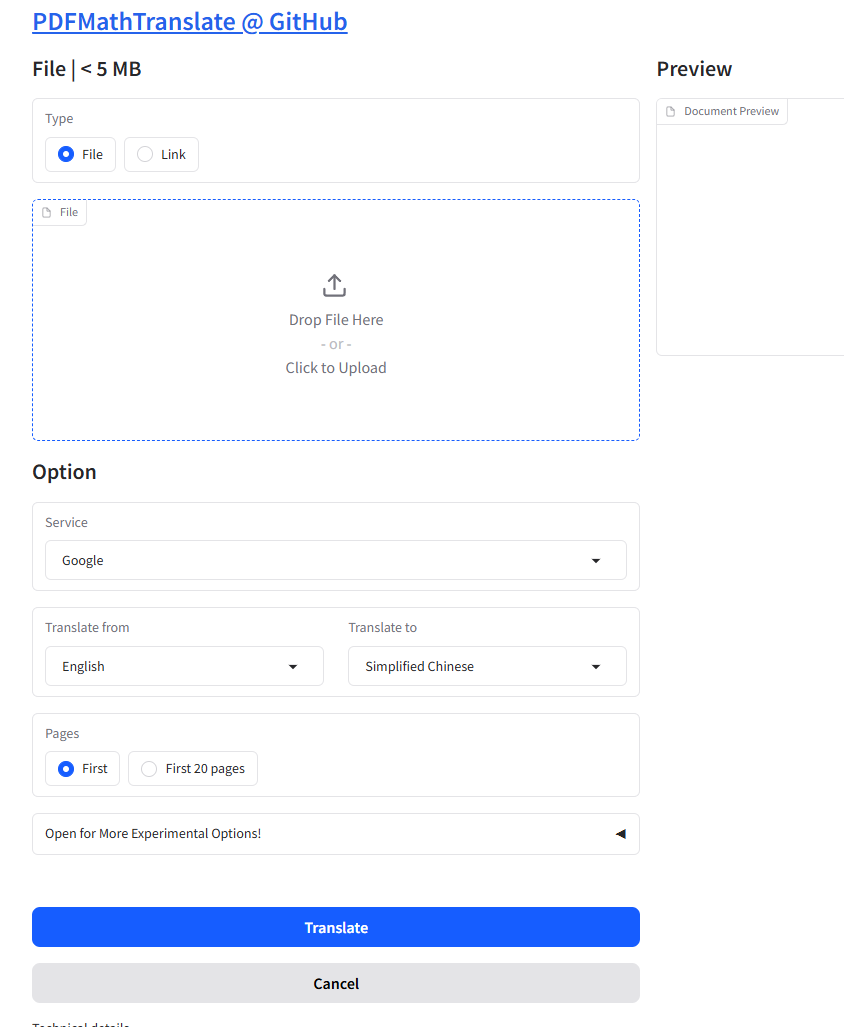
方便发文件的话我试试,本地部署过pdfmathtranslate了。或者你看看这个行不行 BabelDOC - 无损排版,海量额度
1 个赞


- 上传到100%就出错
- 奶牛 [https://cowtransfer.com/s/d49ae8f9cd6245][an8697]
沉浸式翻译长文,效果不好。

pdfmathtranslate刚才下载了,不会部署
2 个赞
漫画那种汉化的方式
1 个赞
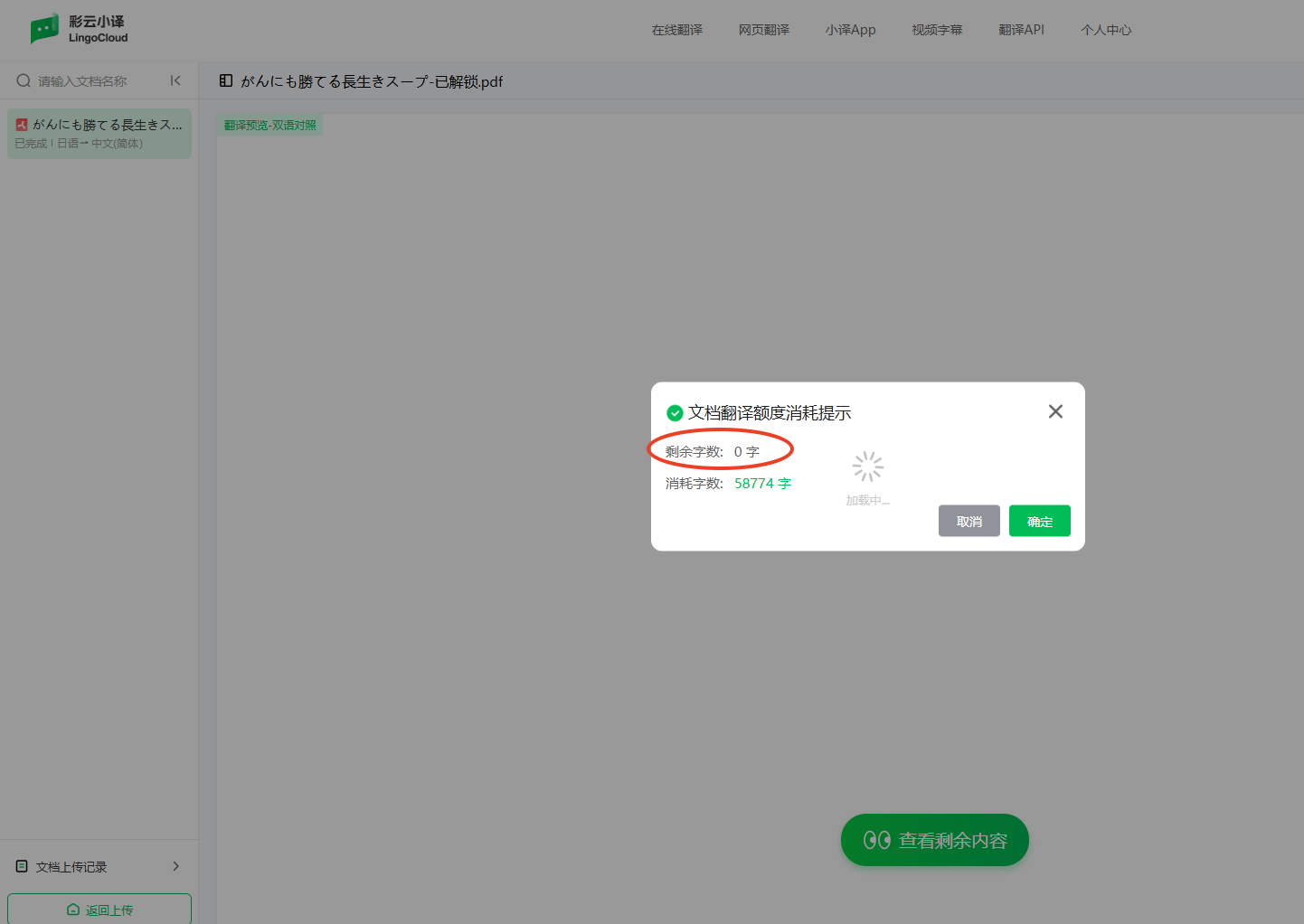
佬友友相关平台或网站吗,google搜ocr 覆盖,出来的都是ocr 识别
1 个赞
刚试了一下pdfmathtranslate,竖版排版也有问题,建议找找漫画翻译的工具。
1 个赞

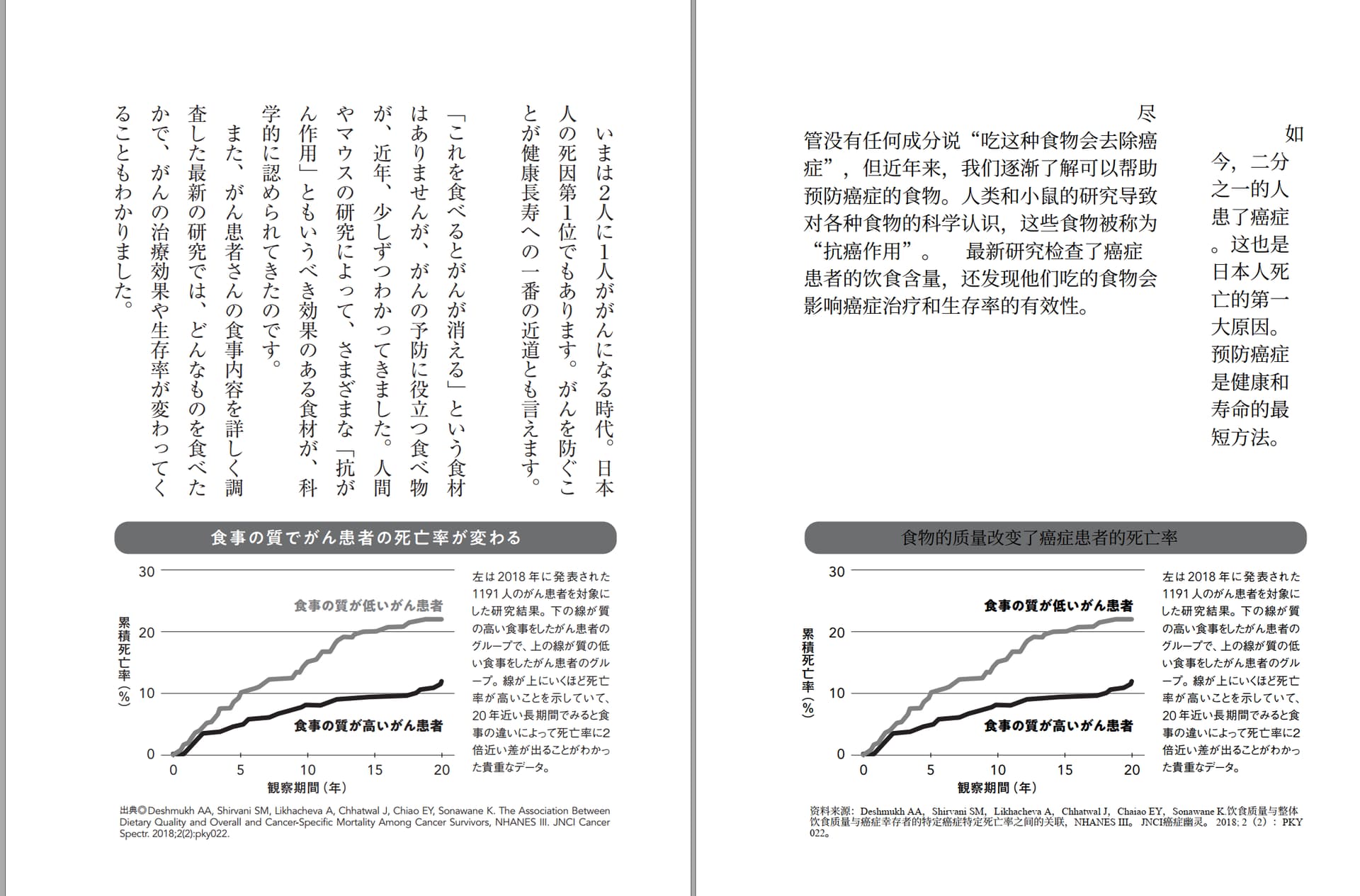
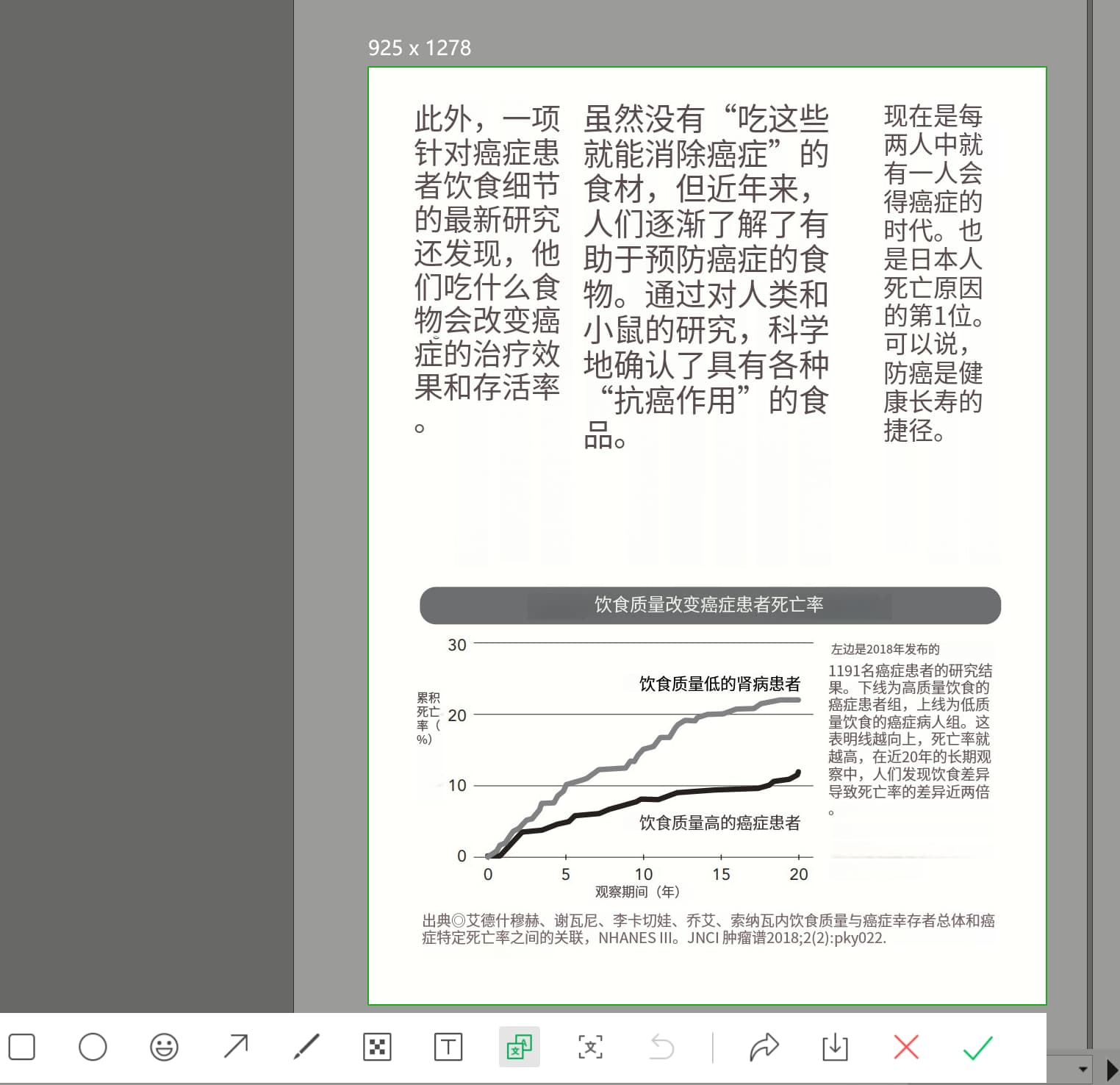

自己部署就没有这个限制了,可以直接用 Windows exe
直接点pdf2zh.exe就行
记得在Experimental里选上Use BabelDOC,可能效果会更好
不过要求必须是能复制文字的单层pdf,并且日语我不太确定可不可以
微信截图,确实很好,但不晓得怎么自动化翻译
沉浸式翻译在保留版面上是最好的了。pdf 记录的是点位信息,没有任何排版信息。道理是这样的,就算你不翻译,只是在原来的基础上多加了几个字,换行了,段落超出了文本框,那文本框也要跟着变大,牵一发动全身,所以又想翻译,又想保留原来的板式是完全办不到的,除非拿到源文件再生成 pdf。