Simple Interview Audio Processing
这个项目后续又更新了一些功能
做这个的原因就是,半夜突然刷到一个同类产品,价格100+/h.然后还在评论区说自己用到的技术复杂,API成本昂贵. 更好的阅读体验在github, gif可以看. 链接: github链接.希望兄弟们点点star.求求![]()
免责声明: 本项目仅为技术练习,严禁用于面试作弊或任何商业用途。若因使用本项目导致任何法律问题,作者概不负责。如本项目对您造成困扰,请联系作者进行删除。
这是一个基于音频流的简单示例项目,旨在展示音频处理的基本功能。灵感源于网络上的高价付费项目,本项目通过简单实现来证明这类功能并不需要复杂的技术堆叠。
下图讲解, 通过播放 b 站视频, 模仿系统内声音输出 Interview 监听到 Redis 相关内容
Rookie 用户麦克风回答 我不知道
ChatGPT(大模型助手) 流式输出相关问题的答案.
https://cdn.professoryin.online/aower-gpt/2024/08/94f9dd892fc22c82242591fded6cb739.gif
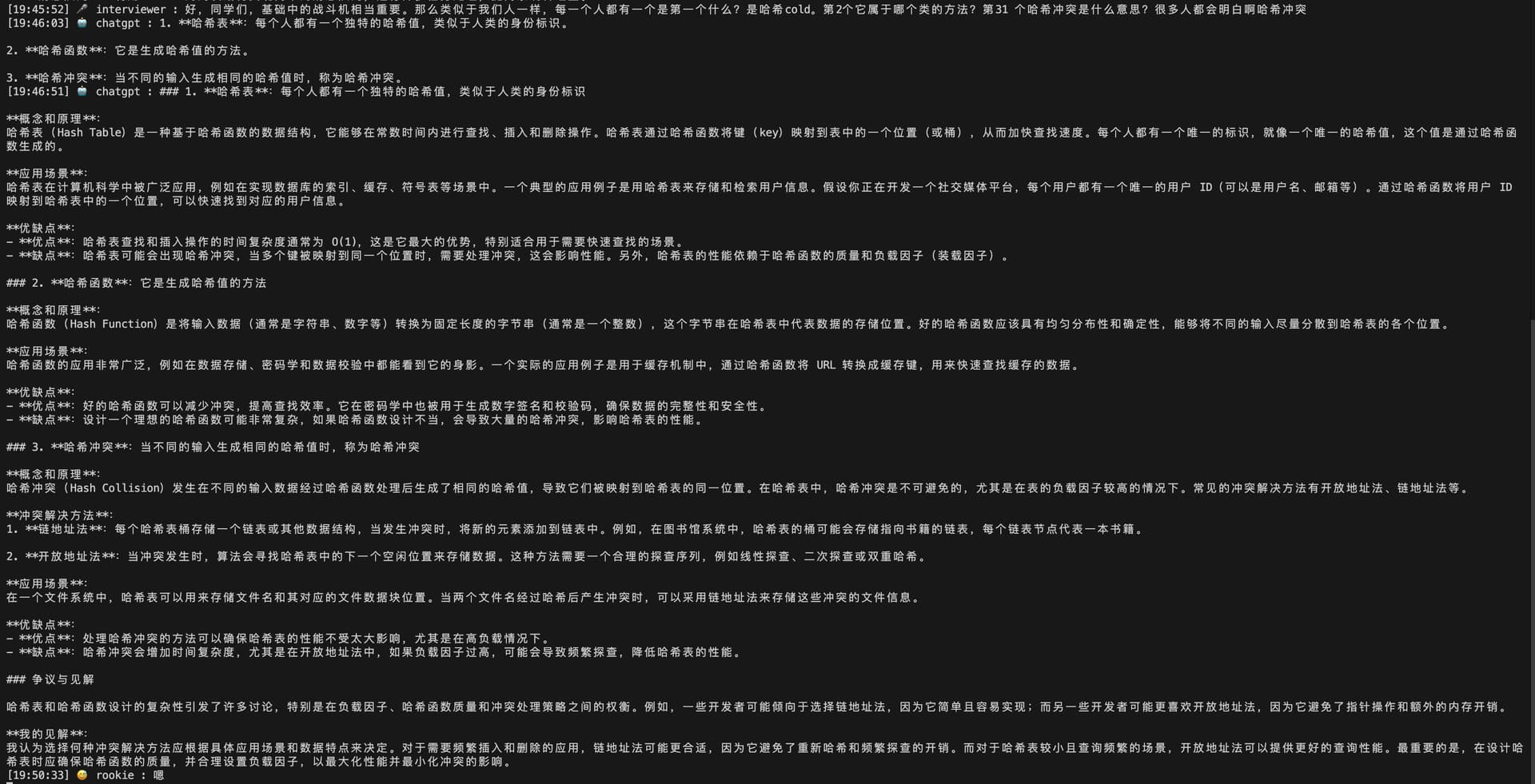
下图讲解,interview(系统内声音) 询问 哈希 相关问题
ChatGPT(大模型助手) 首先回答了简要答案,哈希表、哈希函数、哈希冲突
然后针对这三个点,进行详细性针对性回答.
流式输出,保证输出速度
Features
-
音频源处理: 读取系统声音作为
interviewer声音源,读取麦克风声音作为Rookie声音源,准确区分输入和输出。 -
流式输出: 支持
interviewer、Rookie和ChatGPT的流式对话输出。 -
自定义设置: 可以自定义对话深度和打印内容,控制
interviewer、Rookie和ChatGPT的最大对话记录数。 -
Prompt 工作流: 根据预设工作流顺序处理
prompt文件夹中的所有文件。目前的工作流支持快速回复总结,然后针对各项针对性细节性回答 -
保存对话记录: 通过运行
python interview/SaveFile.py将对话记录保存为 Markdown 文件。 -
支持 openai 式 api:
ChatGPT,Oaipro,Deepseek,通义千问, 以及通过newApi和OneApi转换的openai格式的 API
Installation
1. 启动服务
使用 docker-compose 启动服务:
docker-compose up -d
FunASR Interview 服务
进入 Docker 容器内部:
docker-compose exec funasr_interview bash
在 Docker 容器内运行以下命令启动服务:
cd FunASR/runtime
nohup bash run_server_2pass.sh \
--model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-onnx \
--online-model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-online-onnx \
--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \
--punc-dir damo/punc_ct-transformer_zh-cn-common-vad_realtime-vocab272727-onnx \
--lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst \
--itn-dir thuduj12/fst_itn_zh \
--certfile 0 \
--hotword ../../hotwords.txt > log.txt 2>&1 &
FunASR Rookie 服务
进入 Docker 容器内部:
docker-compose exec funasr_rookie bash
在 Docker 容器内运行以下命令启动服务:
cd FunASR/runtime
nohup bash run_server_2pass.sh \
--model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-onnx \
--online-model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-online-onnx \
--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx \
--punc-dir damo/punc_ct-transformer_zh-cn-common-vad_realtime-vocab272727-onnx \
--lm-dir damo/speech_ngram_lm_zh-cn-ai-wesp-fst \
--itn-dir thuduj12/fst_itn_zh \
--certfile 0 \
--hotword ../../hotwords.txt > log.txt 2>&1 &
2. 安装环境依赖
使用 Poetry 安装依赖:
poetry install
进入虚拟环境:
poetry shell
3. 配置 .env 文件
复制模板文件并根据需要进行修改:
cp .env.template .env
重点修改 AGGREGATE_DEVICE_INDEX、MIC_DEVICE_INDEX 以及 GPT 的 baseurl 和 API 配置。
4. 运行项目
运行主程序:
python interview/main.py
Audio Configuration on macOS and Windows
使用 BlackHole 进行音频捕获(macOS)
在 macOS 中,BlackHole 是一个虚拟音频驱动程序,允许在应用程序之间无缝传输音频。以下是配置步骤:
-
配置 Aggregate Device(合并设备):
- 打开 Audio MIDI Setup 应用程序。
- 创建一个 Aggregate Device,选择 BlackHole 2ch 和你的蓝牙耳机设备。
- 确保 BlackHole 2ch 作为输出设备,蓝牙耳机作为输入设备。
-
配置 Multi-Output Device(多输出设备):
- 创建一个 Multi-Output Device,选择 BlackHole 2ch 和蓝牙耳机作为输出设备。
- 将 Multi-Output Device 设置为系统默认输出设备。
-
运行音频测试:
- 使用
python interview/audioTest.py来获取所有音频输入输出设备,并确保选择输出频率为 16K。
- 使用
在 Windows 中实现音频捕获
在 Windows 系统中,可以使用类似的虚拟音频设备,如 VB-CABLE Virtual Audio Device 或 VoiceMeeter,来实现与 macOS 上 BlackHole 类似的音频捕获功能。以下是使用 VB-CABLE 实现音频捕获的步骤:
-
安装 VB-CABLE Virtual Audio Device:
- 访问 VB-Audio 官方网站 并下载 VB-CABLE 安装程序。
- 安装 VB-CABLE Virtual Audio Device。安装完成后,它将作为一个虚拟音频设备出现在你的系统中。
-
配置音频设备:
- 打开 声音控制面板,进入 播放 和 录制 选项卡。
- 在 播放 选项卡中,将
VB-CABLE Input设置为默认播放设备,这将捕获系统音频。 - 在 录制 选项卡中,选择
VB-CABLE Output作为默认录音设备,这将允许应用程序获取系统音频输入。 - 如果你需要同时捕获麦克风音频,可以将麦克风设置为
VB-CABLE Output的输入,或者在使用 VoiceMeeter 时进行更多高级配置。
-
运行音频测试:
- 使用
python interview/audioTest.py来获取所有音频输入输出设备,并确保在 Windows 上选择合适的音频设备进行录音和播放。 - 确保所选设备的采样率为 16K,以便与 ASR 模型兼容。
- 使用
通过这些步骤,无论在 macOS 还是 Windows 上,你都可以轻松实现音频捕获并应用于项目中。
感谢您的使用!如有任何问题或建议,请随时联系。