三花 AI 一觉醒来发生了什么?欢迎阅读![]()
![]() Reflection 70B 疑似造假
Reflection 70B 疑似造假
![]() 腾讯 Follow-Your-Canvas:扩图技术视频版
腾讯 Follow-Your-Canvas:扩图技术视频版
![]() DeepSeek v2.5:合并升级 Coder 和 Chat 模型
DeepSeek v2.5:合并升级 Coder 和 Chat 模型
![]() Flux Gym:12G VRAM 即可训练 Flux LoRA
Flux Gym:12G VRAM 即可训练 Flux LoRA
本周末无事发生!欢迎大家交流
Reflection 70B 疑似造假
Reflection-70B 自发布以来引来了巨大关注,使用了反思微调技术,你可以简单理解为内置了系统提示词,强制模型输出反思过程,具体使用时只看 <output></output> 中的内容,也意味着会消耗更多的 token。
给大伙梳理了一下最近发生的一些情况:
- 宣称发布了一个最强的原创的开源模型
- 本周还会发布 405B 参数量的版本
- 上传了内置 LoRA 的 Llama 3 模型权重(宣称为 3.1)
- 登顶 HuggingFace 榜首
- 人们发现上传的模型 “don’t work”
- 重新上传了权重,并表示还有一些问题,正在重新训练
- 几天后,这次上传了一个新的 Llama 3.1 微调
- 官方 API 疑似为 SONNET 3.5 + 提示词,主要表现:
- 模型输出时会将 Claude 替换为空字符串(现已修复)
<META>Test</META>提示注入与 Sonnet 一样停在了"如图所示
本以为过节了,结果是愚人节,目前作者还没有更进一步的回应,
Reflection-70B 的系统提示词:
You are a world-class AI system called Llama built by Meta, capable of complex
reasoning and reflection. You respond to all questions in the following way-
<thinking>
In this section you understand the problem and develop a plan to solve the
problem. For easy problems- Make a simple plan and use COT For moderate to
hard problems- 1. Devise a step-by-step plan to solve the problem. (don't
actually start solving yet, just make a plan) 2. Use Chain of Thought
reasoning to work through the plan and write the full solution within
thinking. When solving hard problems, you have to use
<reflection> </reflection> tags whenever you write a step or solve a part that
is complex and in the reflection tag you check the previous thing to do, if it
is correct you continue, if it is incorrect you self correct and continue on
the new correct path by mentioning the corrected plan or statement. Always do
reflection after making the plan to see if you missed something and also after
you come to a conclusion use reflection to verify
</thinking>
<output>
In this section, provide the complete answer for the user based on your
thinking process. Do not refer to the thinking tag. Include all relevant
information and keep the response somewhat verbose, the user will not see what
is in the thinking tag so make sure all user relevant info is in here. Do not
refer to the thinking tag.
</output>
腾讯 Follow-Your-Canvas:扩图技术视频版
Follow-Your-Canvas 是腾讯混元团队的 Follow-Your 系列模型,可以把视频扩展到任意分辨率,且不受显存大小限制。
又一个视频 Outpaint 技术,通过将外扩任务分配到多个空间窗口,然后无缝合并,并保持流畅、连贯。
之前 Follow 系列的还有:Follow-Your-Emoji
DeepSeek v2.5:合并升级 Coder 和 Chat 模型

deepseek-coder & deepseek-chat 现已合并升级为 DeepSeek V2.5 模型,新模型在通用能力、代码能力上,都显著超过了旧版本的两个模型。
在写作任务、指令跟随等多方面全面提升,在 Coder 模型基础上,进一步提升了代码生成能力,对常见编程应用场景进行了优化
此外还一并开源了一个 16B 参数 Lite 版本,现在已经可以直接在官网免费使用了,API 也同步升级,不需要改参数,价格不变。
Flux Gym:12G VRAM 即可训练 Flux LoRA
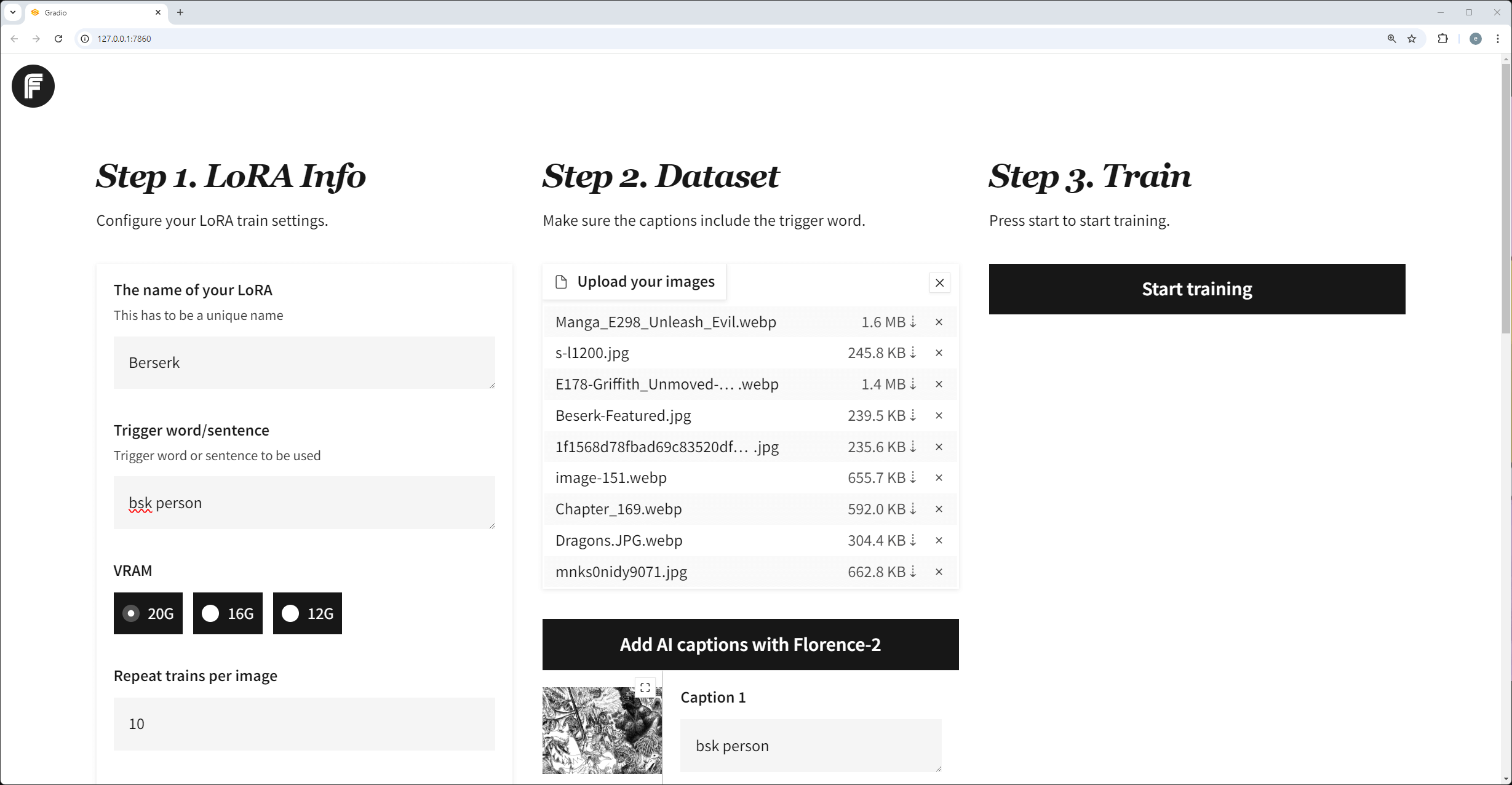
Flux Gym 提供了非常易用的界面,比起 AI-Toolkit 需要至少 24GB VRAM,该项目底层基于 KohyaScripts,支持 12GB、16GB、24GB VRAM 进行 LoRA 训练。
在 Low VRAM 本地机器上训练 Flux LoRA 最简单的方式,作者在随后的更新中又优化了性能,并表示最低可能只需要 8GB VRAM(未经测试)