三花 AI 一觉醒来发生了什么?欢迎阅读 ![]()
![]() 上海 AI 实验室书生筑梦 2.0 开源文生视频模型
上海 AI 实验室书生筑梦 2.0 开源文生视频模型
![]() PaperQA2:第一个自主进行科学文献评审的 Agent
PaperQA2:第一个自主进行科学文献评审的 Agent
![]() Kotaemon:基于 RAG 的文档 QA 系统
Kotaemon:基于 RAG 的文档 QA 系统
![]() MiniMind:完全从 0 训练自己的大模型
MiniMind:完全从 0 训练自己的大模型
![]() Fluxgym 更新:训练时自动生成样本图片
Fluxgym 更新:训练时自动生成样本图片
![]() Adobe Firefly 生成式视频模型
Adobe Firefly 生成式视频模型
![]() ComfyUI 中的数字人头对口型
ComfyUI 中的数字人头对口型
![]() Linfusion: 1 个 GPU,1 分钟,16K 图像
Linfusion: 1 个 GPU,1 分钟,16K 图像
![]() Mistral Pixtral-12B:开源多模态视觉模
Mistral Pixtral-12B:开源多模态视觉模
![]() Fish Speech v1.4 最强开源中文 TTS 和音色克隆
Fish Speech v1.4 最强开源中文 TTS 和音色克隆
![]() ComfyUI-VisualQueryTemplate:模板化图像反推提示词
ComfyUI-VisualQueryTemplate:模板化图像反推提示词
![]() Draw an Audio:通过视频画面配音
Draw an Audio:通过视频画面配音
![]() LLaMA-Omni:语音交互新模型
LLaMA-Omni:语音交互新模型
今天内容有点多,希望你能看完
上海 AI 实验室书生筑梦 2.0 开源文生视频模型

上海 AI 实验室即将发布 Vchitect 2.0,包括模型和训练系统,其模型拥有 20 亿参数,支持 720x480 分辨率 10-20 秒的视频生成,官方还表示未来还会发布一个 50 亿参数的版本。
目前模型还没有放出,只开源了增强框架 VEnhancer 、训练框架 LiteGen 和基准测试 VBench
PaperQA2:第一个自主进行科学文献评审的 Agent
PaperQA2 是第一个能够自主进行科学文献评审的 Agent,且在准确性方面超过了博士和博士后级别的研究人员,并且完全开源,现已斩获 4.1k star。
它能自动搜索、分析并总结相关文献,生成有依据、引用充分的回答,并不断优化搜索结果,这还是 AI Agent 首次在大部分科学研究中超越人类,可能彻底改变科研人员与文献的交互方式。
Kotaemon:基于 RAG 的文档 QA 系统

Kotaemon 是一个开源可定制的 RAG UI,亦有 11k star,支持各大 LLM 和 embedding 模型,专门用于基于文档方式的 AI 聊天问答。
官方还提供了一个 HF 上的演示:cin-model/kotaemon-demo
MiniMind:完全从 0 训练自己的大模型

minimind是 B 站 UP 主近在远方的远开源的一个微型语言模型,改进自 DeepSeek-V2、Llama3 结构,项目包含整个数据处理、pretrain、sft、dpo 的全部阶段,包含混合专家(MoE)模型。
其目标是把上手 LLM 的门槛无限降低, 直接从 0 开始训练一个极其轻量的语言模型,最低仅需 2G 显卡即可推理训练!
Fluxgym 更新:训练时自动生成样本图片
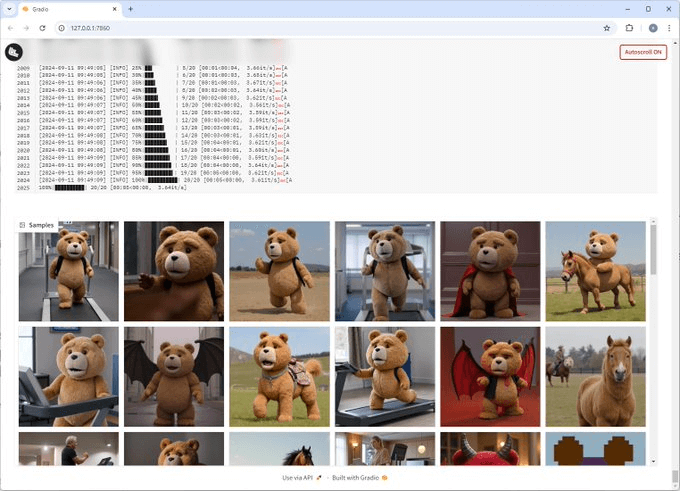
之前介绍了 Fluxgym,一种在 Low VRAM 本地机器上训练 Flux LoRA 最简单的方式。昨天发布了新更新,现在能够在训练时自动生成样本图片,此外还支持了自定义分辨率,而不仅仅时 512 或 1024
Adobe Firefly 生成式视频模型
Adobe 于 2023 年 3 月首次推出了 Adobe Firefly,主要用于图片和矢量图生成,昨晚 Adobe 官方发文表示即将推出的 Firefly 视频模型,并将直接与 Premiere Pro 集成,预计在今年晚些时候开始测试。
现在可以提前申请白名单,链接在这:Firefly Video
ComfyUI_EchoMimic:在 Comfyui 中使用语音匹配的数字人头
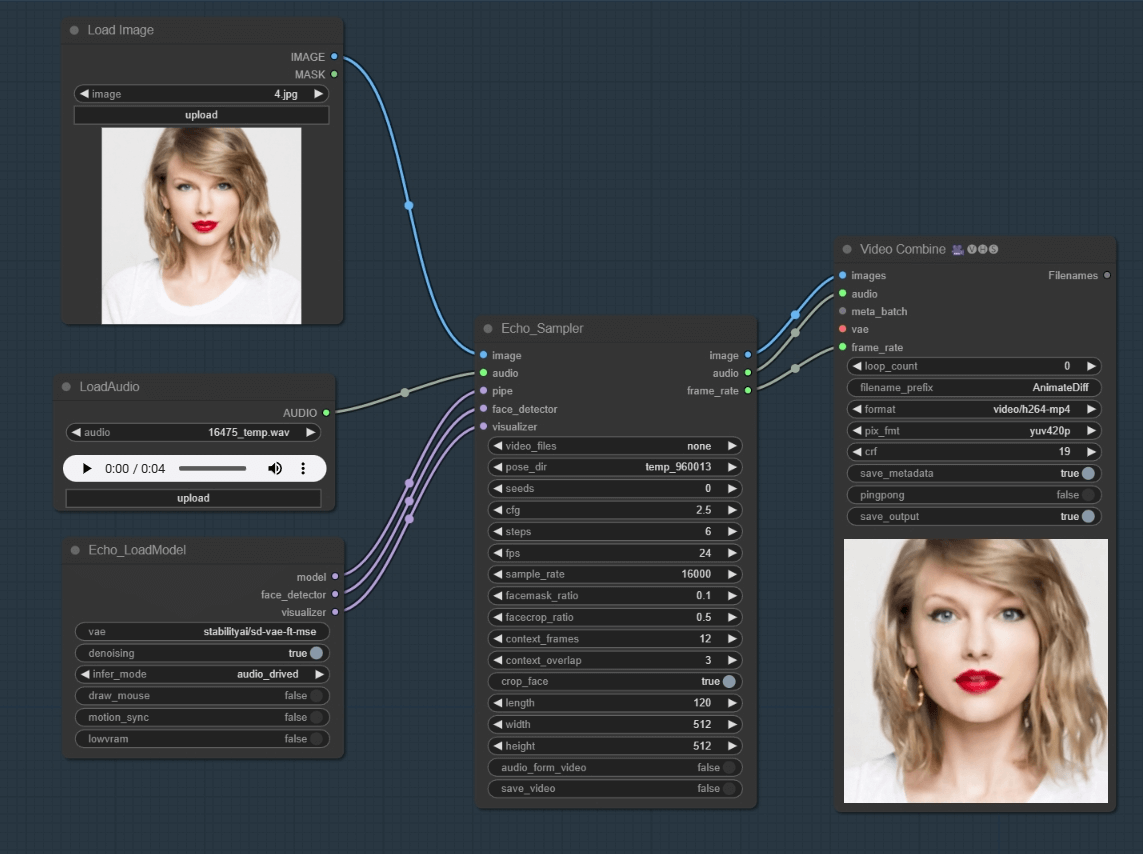
EchoMimic 来自阿里的通过音频匹配对应口型生成视频的一个技术,ComfyUI_EchoMimic 能够让我们将其结合到 Comfyui 中,最低只需 6GB VRAM,安装环境比较麻烦,不过 README 中有中文介绍。
还有一个类似的节点,ComfyUI-SyncTalk,也能实现类似的效果。
Linfusion: 1 个 GPU,1 分钟,16K 图像

Linfusion 其口号就是一分钟生成 16k 图像,同时兼容 ControlNet 和 IP-Adapter,主要能够提升生图速度并降低对 VRAM 的要求,从论文中的速率比较看,生成 512 到 16k 图片在速度和对 VRAM 要求的曲线非常的平滑,而原始 SD1.5 则会在生成 4K 之后飙升
目前只适配了 SDv1.5,未来会适配更多,有预感会成为接下来一个非常有用的项目。
体验了官方的 SDv1.5 的演示:Huage001/LinFusion-SD-v1.5 速度确实非常快,在 HF 的 ZERO GPU 上只需几秒即可完成 25 Steps 的推理
Mistral Pixtral-12B:开源多模态视觉模型

Mistral 官推昨天通过磁力链发布了 Pixtral 12B 模型,没有解释,只有链接。不过目前该模型已经由社区上传到了:mistral-community/pixtral-12b-240910,主要关键点如下:
-
文本主干网络:基于 Mistral 的 Nemo 12B
-
视觉适配器:4 亿
-
使用了 GeLU 激活函数和二维旋转位置编码(2D RoPE)
-
词汇量达到了 131,072 个
-
三个特殊 token: img、img_break 和 img_end
-
支持 1024 x 1024 的图片
-
模型权重为 bf16 格式
上面的总结来自于大佬:Vaibhav (VB) Srivastav
现在已经有了多个基于该模型演示,可以在这里找到:HuggingFace-pixtral
Fish Speech v1.4 最强开源中文 TTS 和音色克隆
之前介绍过 fish-speech v1.2,昨天更新了 v1.4 版本,来自 B 站 UP 主冷月 2333 ,新模型使用 70 万小时的多语言数据进行训练,支持 8 种语言的语音生成,完全开源。
官方提供了一个开源演示:fishaudio/fish-speech-1,当然也只可以直接在其官方上使用,每月都有免费次数。
遗憾的是,该模型采用 CC BY-NC-SA 4.0 协议,而其最主要的限制就是禁止任何商业用途。
ComfyUI-VisualQueryTemplate:模板化图像反推提示词
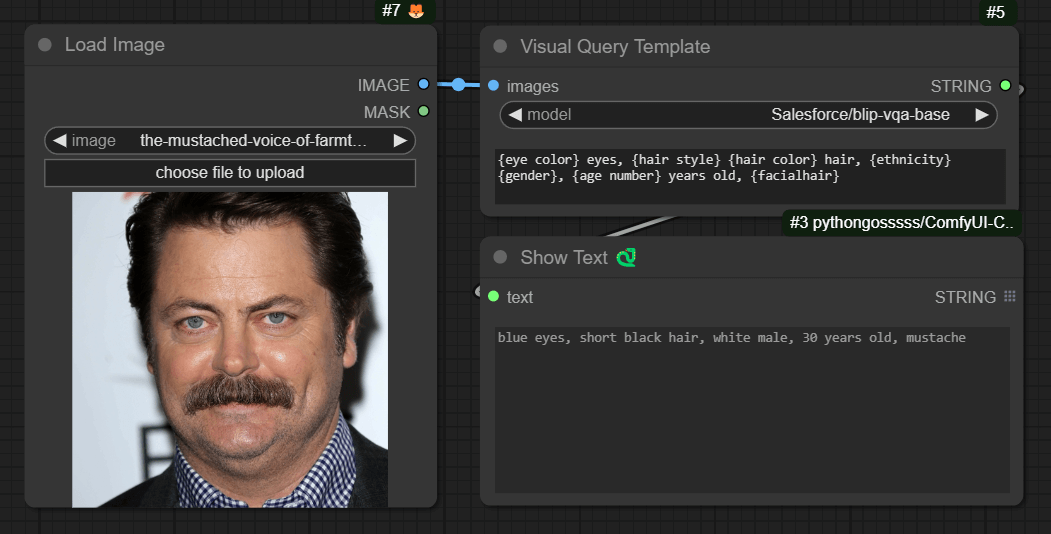
之前我总是用 WD 1.4 Tagger 这个节点来反推提示词做图生图相关工作流,虽然它支持 exclude 来排除我不想要的 tag,但总归还是比较麻烦的
VisualQueryTemplate 这个节点可太有用了,你可以直接书写模板,该节点直接根据你的模板生成提示词。如图所示,你可以只要图片中的眼镜颜色、头发风格、年龄、性别和胡子。
当然,直接用多模态视觉模型也能做到,就是要写提示词。
Draw an Audio:为视频配音
Draw an Audio 可以通过视频画面来生成匹配的音频。支持音乐、音效等,目前还是期货开源,关注我,为你持续跟进哈!
视频中的是为 Sora 生成的视频配的音频。
LLaMA-Omni:语音交互新模型
LLaMA-Omni 是基于 Llama-3.1-8B-Instruct 的语音语言模型,延迟低于 250 毫秒,能同时生成文本和语音,目前还没有在线演示,关注我,为你持续跟进哈!