- RAG 是什么
RAG 是 Retrieval Augmented Generation 的缩写,即检索增强生成。
使用 RAG 的目的是为模型提供更多的上下文,减少模型的幻觉,提高模型的注意力。
- RAG 常见原理
RAG 的核心思想是为模型补充上下文,上下文的来源可以是文档,网页,图片…。最终所有的信息都会被喂给聊天模型(ChatGPT,Claude,Gemini…)。
现在常用的 RAG 工作流都依赖嵌入向量模型,流程大概是:
- 索引构建
收集整理要用的上下文文件(数据源),提交给嵌入向量模型(embedding),嵌入模型会返回数据的向量表示,客户端将向量数据保存到向量数据库中。
- 查询构建
客户端将用户提问也转换为向量数据,然后使用向量查询算法从向量数据库中检索相关的信息,提取相关度最高的信息块(可能有多块)。
- 模型问答
将以上提取到的信息块与用户的提问合并,调整提示词,喂回给聊天模型,实现上下文补充。
注意,向量检索过程中,用户提问和上下文都是向量数据。但是聊天模型不能直接使用向量数据,所以最终还是会从数据源中提取对应的内容(一般是文字)。
- RAG 质量关键
- 嵌入向量模型:决定上下文向量化的质量。
- 聊天模型:最终所有的信息还是靠聊天模型来分析思考。
- 客户端:上下文整理(文件切割,预处理),以及使用的向量查询算法,内容提取算法。
- Open WebUI 集成 RAG
open webui 使用 RAG 的主要场景有两个:文档对话和网页搜索。其实在使用网页搜索时,open webui 也会将搜索到的网页数据进行向量化处理。
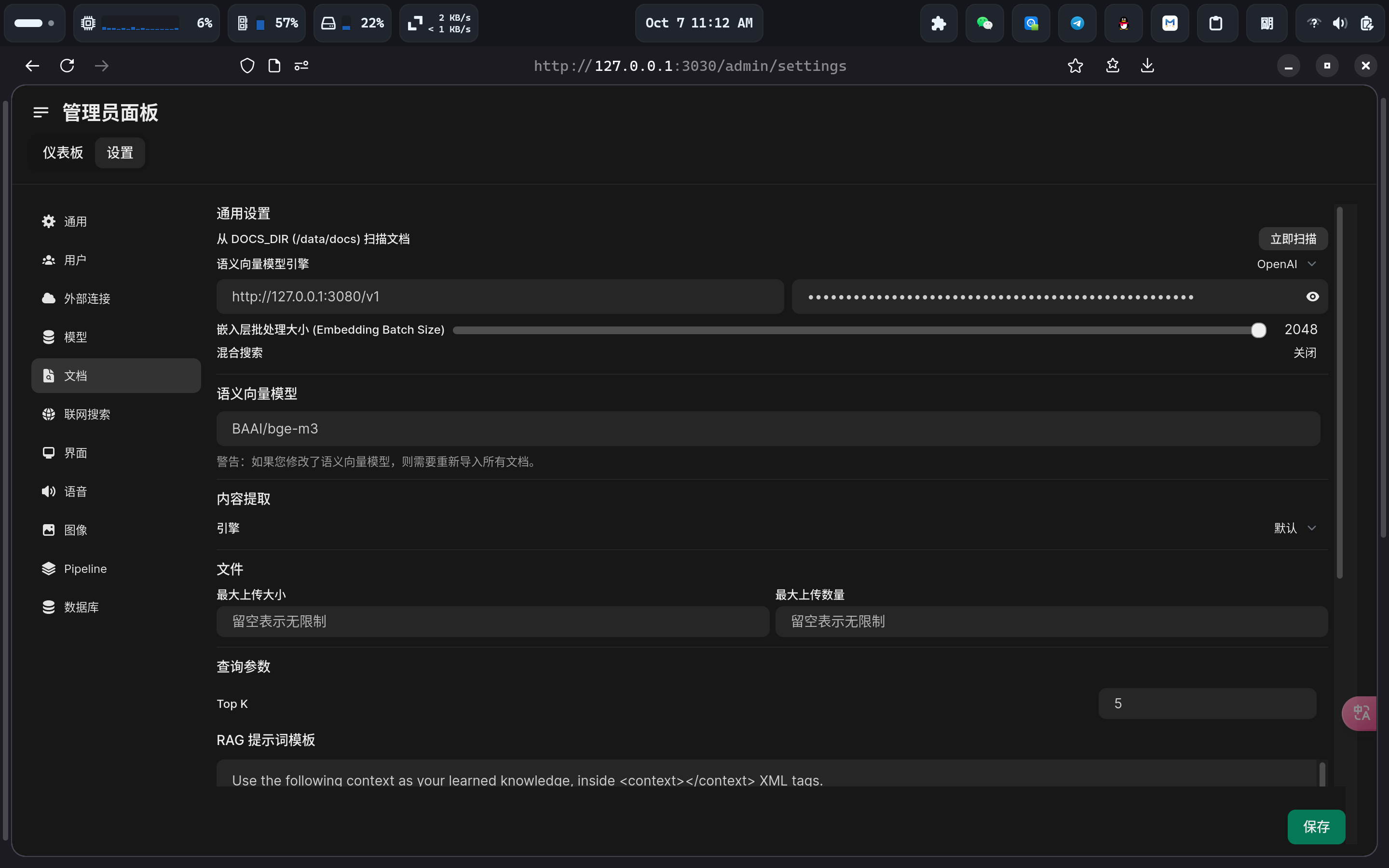
配置核心是文档设置:向量模型可以使用自带的本地模型,也可以使用 openai 格式可用的在线模型。内容提取模型一般选择默认就好,tika 那个不一定可用。Batch Size 需要根据向量模型的文档设置(openai 的两个模型都支持 2048 大小),一般是越大越快。
- 一些建议
现在很多中转都只关心聊天模型,其实向量模型根本不可用…,这个需要自己鉴别。
在线向量模型一次请求能接受的数据是有限的,完成一次文档向量可能需要几十次甚至上百次请求,所以要注意网络和使用的中转质量。
彩蛋:我使用的BAAI/bge-m3模型是硅基流动的,这个模型官方没有限速,而且用的人很少,所以比较稳定。