import requests
import asyncio
import json
from typing import Callable, Any, Optional
EmitterType = Optional[Callable[[dict], Any]]
SendCitationType = Callable[[str, str, str], None]
SendStatusType = Callable[[str, bool], None]
def get_send_citation(__event_emitter__: EmitterType) -> SendCitationType:
async def send_citation(url: str, title: str, content: str):
if __event_emitter__ is None:
return
await __event_emitter__(
{
"type": "citation",
"data": {
"document": [content],
"metadata": [{"source": url, "html": False}],
"source": {"name": title},
},
}
)
return send_citation
def get_send_status(__event_emitter__: EmitterType) -> SendStatusType:
async def send_status(status_message: str, done: bool):
if __event_emitter__ is None:
return
await __event_emitter__(
{
"type": "status",
"data": {"description": status_message, "done": done},
}
)
return send_status
class Tools:
def __init__(self):
pass
async def web_scrape(self, url: str, __event_emitter__: EmitterType = None) -> str:
"""
Scrape and process a web page using gpts.webpilot.ai API
:param url: The URL of the web page to scrape.
:param __event_emitter__: Optional event emitter for status updates.
:return: The scraped and processed content, or an error message.
"""
api_url = "https://gpts.webpilot.ai/api/read"
headers = {"Content-Type": "application/json", "WebPilot-Friend-UID": "0"}
payload = {
"link": url,
"ur": "summary of the page",
"lp": True,
"rt": False,
"l": "en",
}
send_status = get_send_status(__event_emitter__)
send_citation = get_send_citation(__event_emitter__)
try:
await send_status(f"正在读取 {url} 的内容", False)
# 添加一个小延迟,确保初始状态能被显示
await asyncio.sleep(0.1)
response = requests.post(api_url, headers=headers, json=payload)
response.raise_for_status()
# Parse the JSON response
result = response.json()
# Remove the 'rules' field from the result
if "rules" in result:
del result["rules"]
# Convert the modified result back to a JSON string
content = json.dumps(result, ensure_ascii=False)
# Send citation before marking status as complete
await send_citation(url, "Web Scrape Result", content)
# Mark status as complete after sending citation
await send_status("网页内容已获取", True)
return content
except requests.RequestException as e:
error_message = f"Error scraping web page: {str(e)}"
await send_status(error_message, True)
return error_message
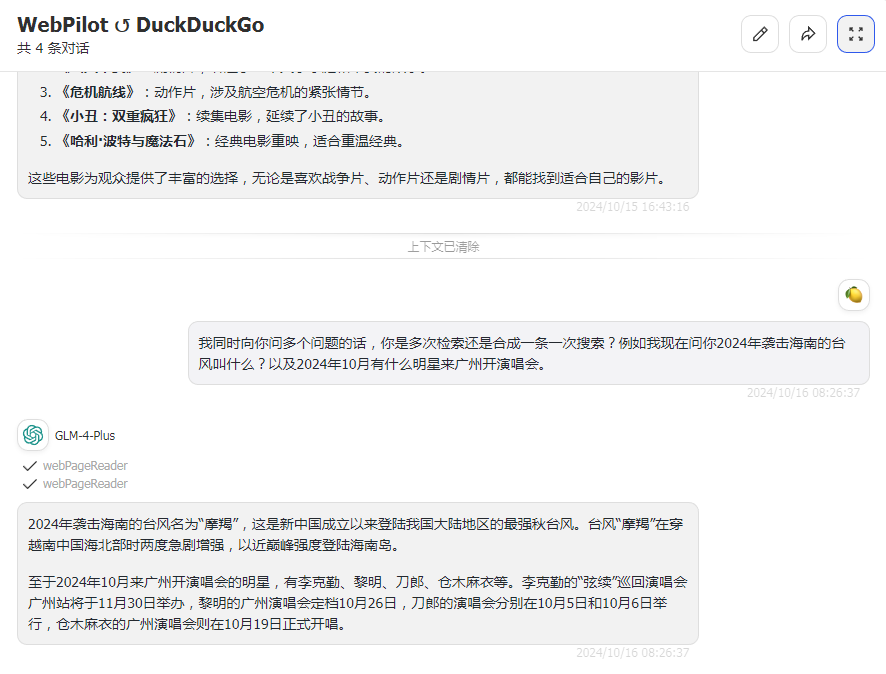
不需要function calling也能调用,代码粘贴到oi工作区的tool
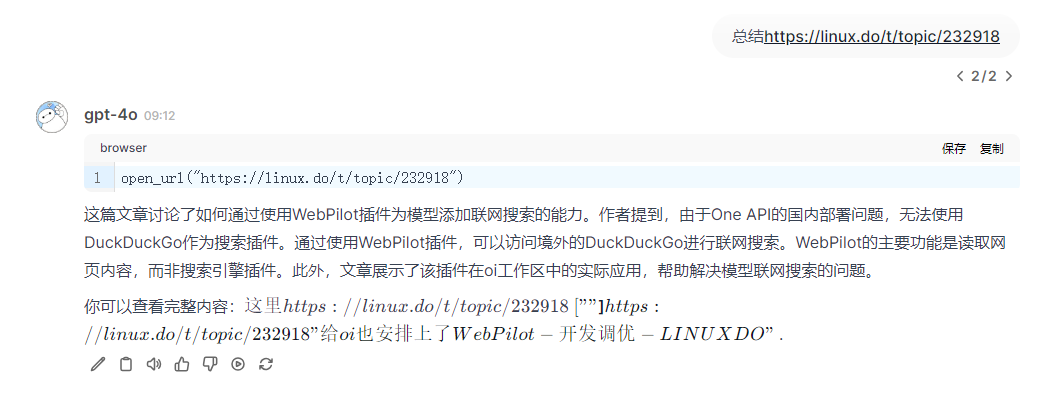
第二版本,支持搜索结果的显示和引文,支持多URL读取
import requests
import asyncio
import json
import aiohttp
from typing import Callable, Any, Optional, List
EmitterType = Optional[Callable[[dict], Any]]
SendCitationType = Callable[[str, str, str], None]
SendStatusType = Callable[[str, bool, str, List[str], Optional[str]], None]
def get_send_citation(__event_emitter__: EmitterType) -> SendCitationType:
async def send_citation(title: str, url: str, content: str):
if __event_emitter__:
await __event_emitter__(
{
"type": "citation",
"data": {
"document": [content],
"metadata": [{"name": title, "source": url, "html": False}],
},
}
)
return send_citation
def get_send_status(__event_emitter__: EmitterType) -> SendStatusType:
async def send_status(
status_message: str,
done: bool,
action: str,
urls: List[str],
query: Optional[str] = None,
):
if __event_emitter__:
status_data = {
"done": done,
"action": action,
"description": status_message,
}
if query:
status_data["query"] = query
if urls:
status_data["urls"] = urls
await __event_emitter__({"type": "status", "data": status_data})
return send_status
class Tools:
def __init__(self):
pass
async def web_scrape(
self, urls: List[str], __event_emitter__: EmitterType = None
) -> str:
"""
Scrape and process multiple web pages using gpts.webpilot.ai API
:param urls: List of URLs of the web pages to scrape.
:param __event_emitter__: Optional event emitter for status updates.
:return: Combined scraped and processed contents, or error messages.
"""
api_url = "https://gpts.webpilot.ai/api/read"
headers = {"Content-Type": "application/json", "WebPilot-Friend-UID": "0"}
send_status = get_send_status(__event_emitter__)
send_citation = get_send_citation(__event_emitter__)
combined_results = []
await send_status(f"准备读取 {len(urls)} 个网页", False, "web_scrape", urls)
async def process_url(url):
try:
payload = {
"link": url,
"ur": "summary of the page",
"lp": True,
"rt": False,
"l": "en",
}
async with aiohttp.ClientSession() as session:
async with session.post(
api_url, headers=headers, json=payload
) as response:
response.raise_for_status()
result = await response.json()
result.pop("rules", None)
content = json.dumps(result, ensure_ascii=False)
title = result.get("title", f"来自 {url} 的结果")
await send_citation(title, url, content)
return f"URL: {url}\n标题: {title}\n内容: {content}\n"
except aiohttp.ClientError as e:
error_message = f"读取网页 {url} 时出错: {str(e)}"
await send_status(error_message, False, "web_scrape", urls)
return f"URL: {url}\n错误: {error_message}\n"
tasks = [process_url(url) for url in urls]
results = await asyncio.gather(*tasks)
combined_results.extend(results)
await send_status(f"已完成 {len(urls)} 个网页的读取", True, "web_search", urls)
# 将所有结果合并为一个字符串
final_result = "\n".join(combined_results)
return final_result
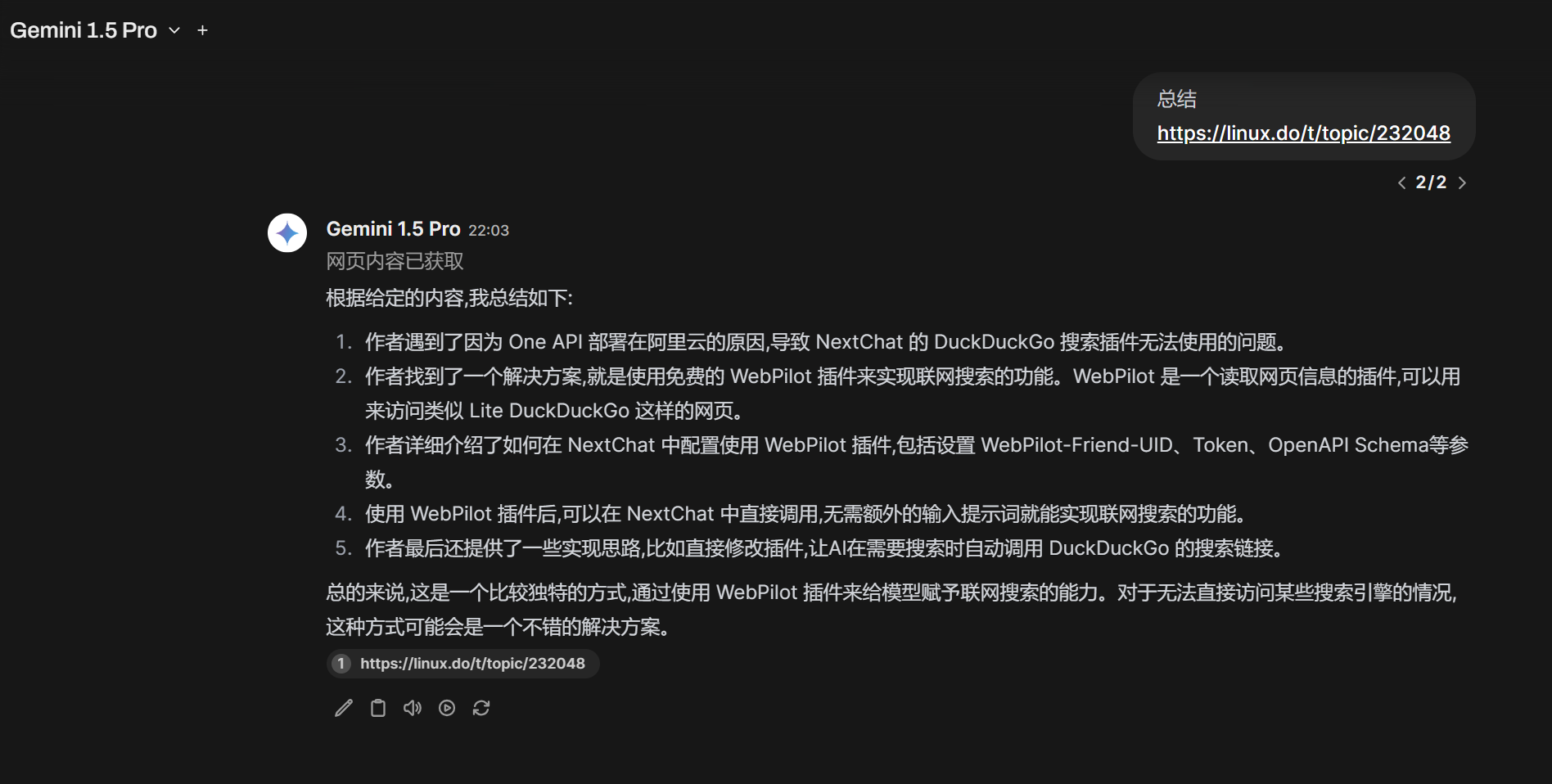
社区直接导入最新版
https://openwebui.com/t/2171/webpilot
jina版
https://openwebui.com/t/2171/jina