RT,我平时会用GPT、Claude、notebook做一些长文档整理、文献和书籍阅读之类的工作,比如根据需求说明文档整理功能点清单,从一本书或长文档中提取我需要的内容(不是简单的一个QA)。
使用过程中,经常发现GPT在总结、梳理内容过程中会出现信息损失,一些人肉整理时不会合并或省略的功能点,会被AI简化、合并甚至忽略;有时会导致一些重要的细节丢失,人工回顾和检查又很花时间。
上述三大模型都用的是4o/o1,sonnet,gemini 2.0和1206这些高级模型,但是仍然不同程度地会出现这个通病。
即使我使用了一些提示词优化后减少了这种情况,但是仍然有一定概率出现。
想问问佬们是如何避免这个问题的?
8 个赞
能用 Python 解决的就让 Claude 写 Python,这种一般要么全对要么全错。
顶,我也想知道
长文档海里捞针建议要么 RAG,要么写程序 ![]()
模型通病,可以先让gpt提取目录提纲,分目录一段一段整理。
要么本地RAG知识库,但RAG对分布在多处的知识点之间的关联能力也不强
之前不是好多家都吹99%的召回率
直接提交文本应该会好一些,提交pdf文件我也感觉到基本90%有数据丢失,尤其是让他提取文献数据时
提示词的优化可以放出来参考吗
个人拙见,感觉 RAG 这种投机取巧的办法就不适合长文本全局性的理解,仅仅召回几个最相关的文本片段,其他文本统统扔掉了,能不抓瞎吗 ![]() 。模型再怎么强,提示词再怎么优化,只能看到零星几个片段,巧妇难为无米之炊呀。
。模型再怎么强,提示词再怎么优化,只能看到零星几个片段,巧妇难为无米之炊呀。
通义千问网页端,号称 1000 万长文档处理能力,处理一本不到百万字总共 60 多章的小说应该很轻松吧。让它找出所有章节的标题(小说没有目录,防止作弊),现实是只能找到 4-6 个标题,感觉召回的片段数量不超过 10 个。
如果使用 Open WebUI 或者 Dify,可以直接查看召回了哪些片段,很容易明白为什么会出现信息损失,过度简化、合并甚至忽略,重要细节丢失的原因了。直接用 GPT、Claude 的网页端,看不到这层信息。
如果可能,我更倾向于直接把文档的完整内容交给模型,充分利用其上下文窗口的长度。但也会面临 token 爆炸,上下文长度达到一定程度时模型性能下降的问题。
据说 GraphRAG 对全局性的问题效果更好,但也是 token 消耗大户
1 个赞
在有限上下文窗口情况下(4o|128k、sonnet|200k、gemini|2000k),超长文本处理必然有信息损失,无论是RAG还是prompt,都只能缓解,不能根除。
目前我感知上,这方面做得比较好的 Windsurf,可以很智能的感知定位到要修改的代码块,即便我没有指定。
最好的办法就是用一个真正长上下文窗口的模型。没想到吧,这些个独角兽/巨头都在窗口大小上唬人呢。这也是为什么明明不到128k的长文本输入,居然就开始忘东忘西。
Nvidia 的 RULER 长上下文性能测试基准:
Paper: [2404.06654] RULER: What's the Real Context Size of Your Long-Context Language Models?
Github: GitHub - NVIDIA/RULER: This repo contains the source code for RULER: What’s the Real Context Size of Your Long-Context Language Models? )
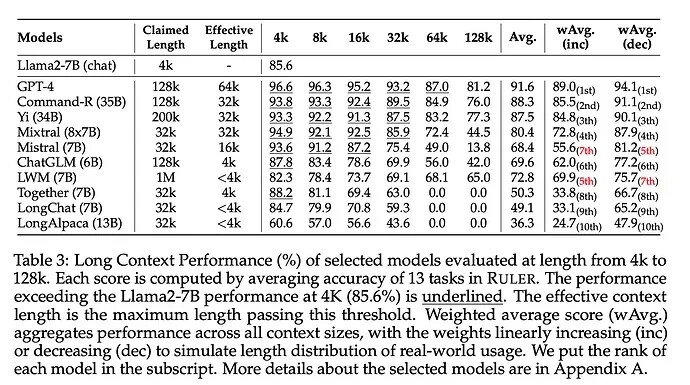
2 个赞
不知道咋测出来的召回率,如果我一个个问题问,它确实都知道,但是让他帮忙整理一个清单,就会漏东西
确实。我尝试过只丢8000个字的纯文本进那几个头部模型去整理,一样会丢失,感觉百思不解…原来是这样
我PDF、纯文本都试过,效果改善不显著。
转成markdown试试
我试过全文直接丢给模型,已经token爆炸了,一个Claude pro账号不到2小时就额度上限 ![]() 然后就不敢继续了。。。短暂使用的感受是网页端的project功能,效果没有特别明显的改善。
然后就不敢继续了。。。短暂使用的感受是网页端的project功能,效果没有特别明显的改善。
1 个赞
这几天试了一下Monica 感觉文章整体结构阅读比较完整?
graphrag构建的知识图谱就是用来解决这个问题的,它可以解决佬的问题。
可以先用gemini-2.0-flash-exp跑,跑完后换成gemini-exp-1206模型问问题。
chunk默认1200,纯文本每增加1MB,调用3600次模型 供参考
有一个LightRAG,比graphrag节省token,没有使用过
1 个赞
感谢佬的指点!研究一下子
1 个赞
我的提示词效果还不够好,等调试稳定了再发帖分享下