从智谱深度推理模型 GLM-Zero 预览版上线【性能较强】继续讨论:
卡神测评:
咱也不跟贵的比 毕竟咱完全免费![]()
不信 ![]()
3b怎么一直在闪?
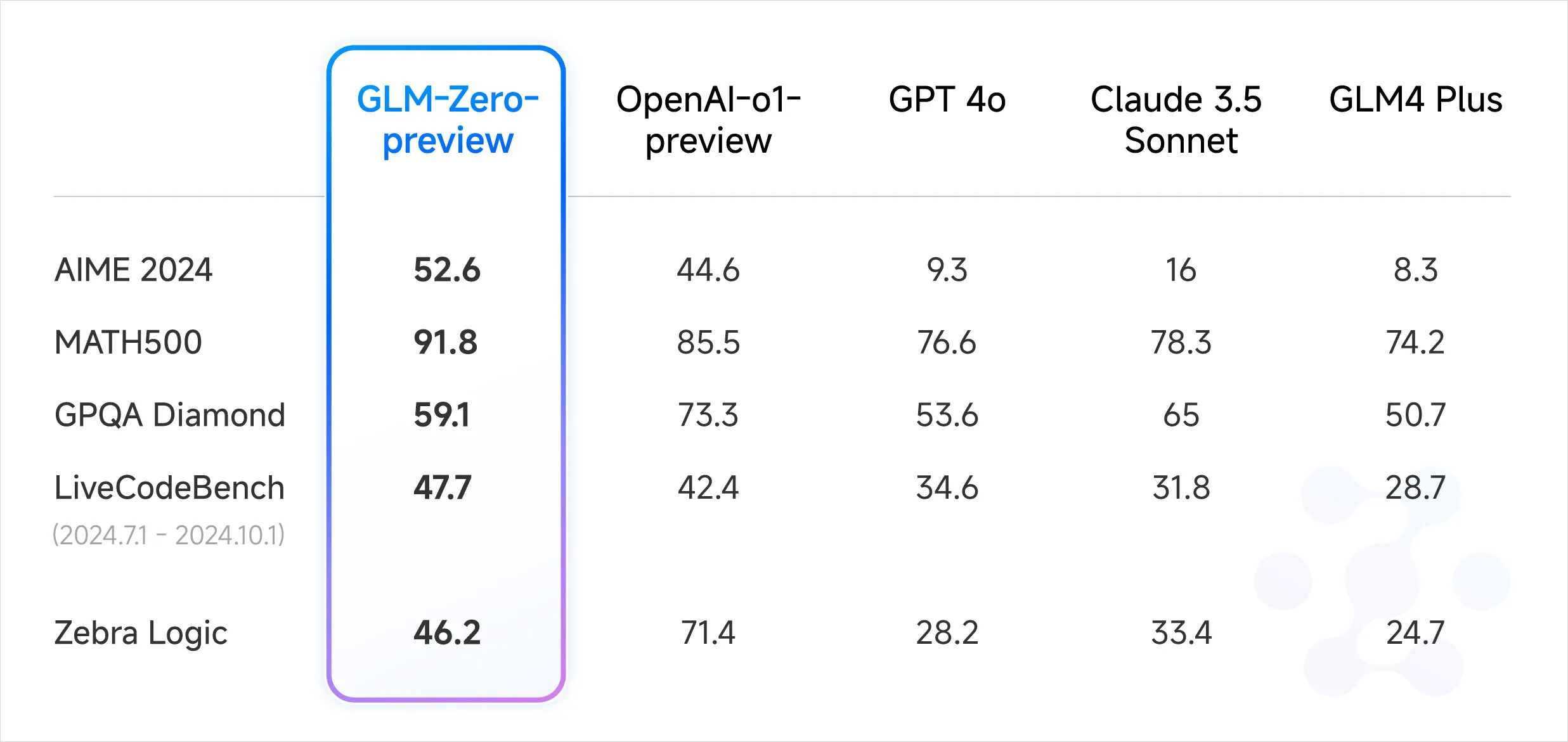
话说大家好像不太在意后面几个数据,其他大模型数据竟然连20都不到![]()
遥遥领先
![]()
奥特曼的内涵已经在路上
能力还是进步了的:
超过O1P 是不可能的,那些已经有答案的考试尽量忽略,用私人测试即可,另外有一点,Zebra Logic 低分,通常真实智力,即可泛化的解题能力都非常弱,因为那个题目考最基本的逻辑.
no way!
只能说又赢麻了![]()
与自己比有进步就是好事
基于测试集训练的模型
我不太敢相信,上一个这样说的是Kimi,结果比不过doubao
这么看来,确实差点火候啊。
不只是差点火候,这个差距简直就是诈骗。居然还宣传超过o1 p
今天我实测了一波,对比了o1. Deepseek r1 lite. QwQ 32B. K0-math. GLM-zero,总的来看,和o1差距非常大,在国产推理模型中,deepseek是最稳定的,大概追赶o1-preview的水平。另外我发现国产推理模型在推理时表现的很奇怪,不自信,经常自我怀疑自我否定,无用功很多,容易过度思考陷入死循环
同意,国内思考模型的思考特别长,而且反复纠结一个点
拿了广告费
智谱从开始就没怎么厉害过,文本生成方面。始终是二三线水准。。根本不值得期待