经过最近的调研,本篇从四个角度,验证在springboot中计算token的方法。分别从按字符数、langchain4j,jtokkit,以及某网页的计算token结果进行分析。
测试环境:
-
Java 21
-
SpringBoot 3.0.13
-
操作系统:Mac
所用的计算token库
- langchain4j 0.30.0
- jtokkit 0.4.14
- 以及字符计算方法
测试用例:
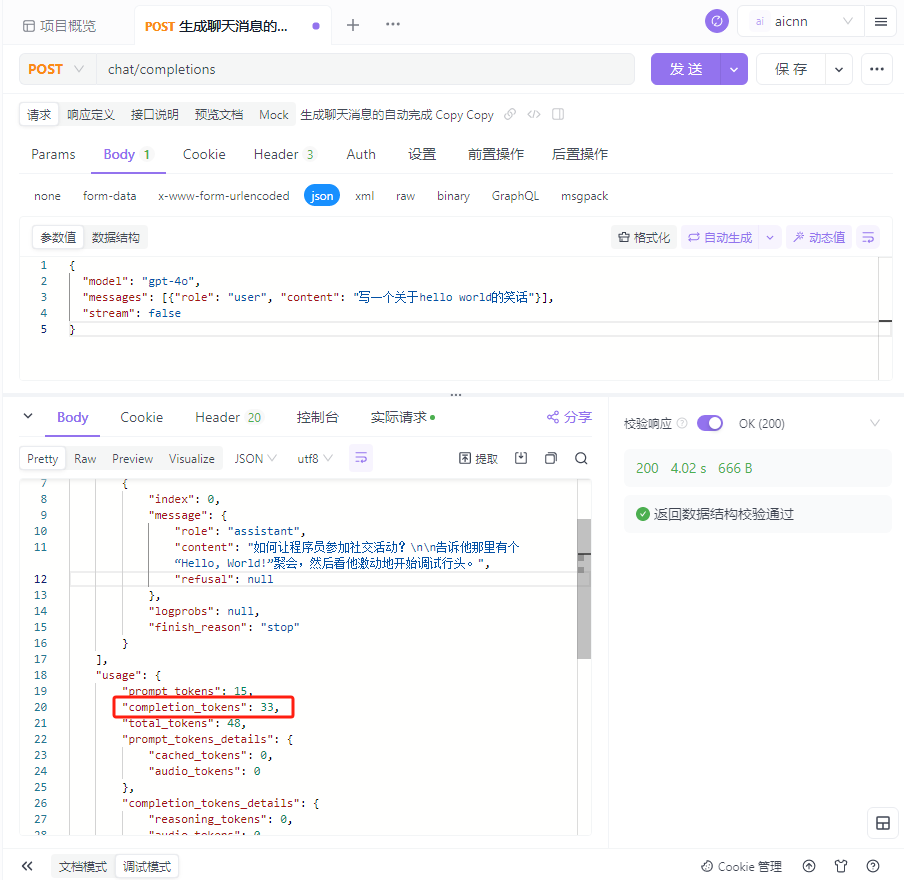
先附上测试结果:
openai官方返回的token数:33
langchain4j计算出来的token数:40 约比官方返回的多出21%
JTokkit计算出来的token数:36 约比官方返回的多出9%
计算字符数得到的token数:67 约比官方返回的多出103%

某在线网站的测试结果( 约比官方返回的多出103%):
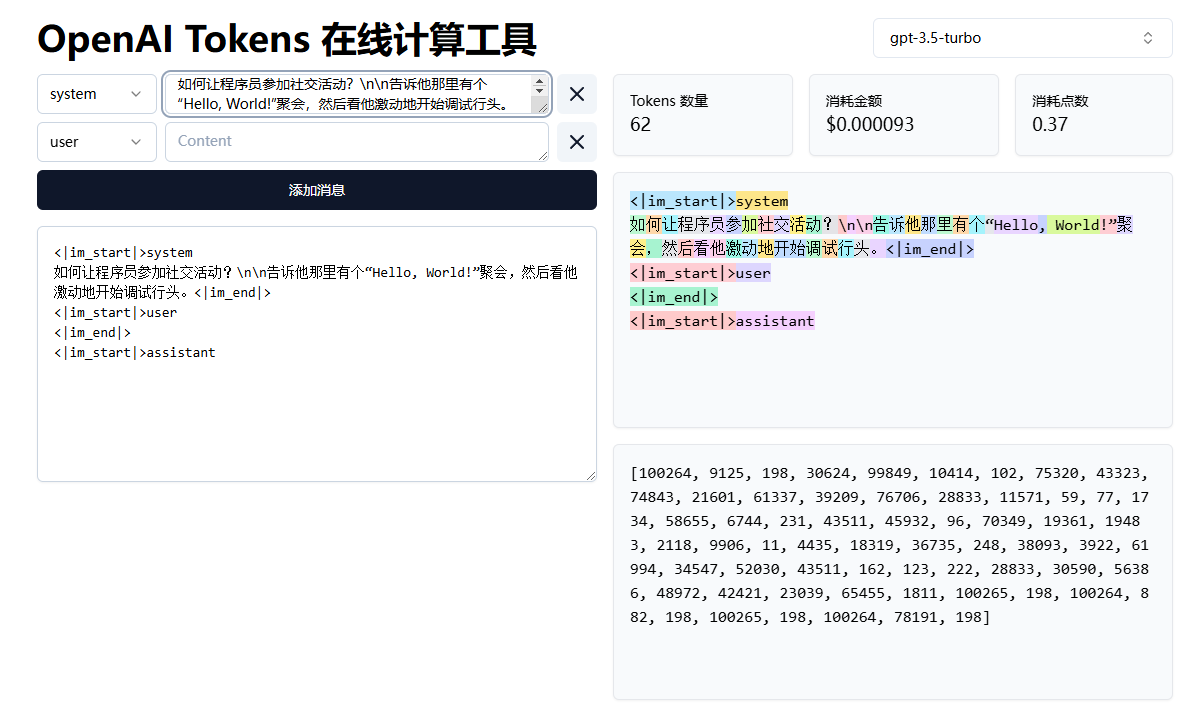
测试代码如下,感兴趣的小伙伴可自行测试:
- pom.xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.30.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pgvector</artifactId>
<version>0.30.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>0.30.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
<version>0.30.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-poi</artifactId>
<version>0.30.0</version>
</dependency>
<dependency>
<groupId>net.coobird</groupId>
<artifactId>thumbnailator</artifactId>
<version>0.4.14</version>
</dependency>
- 计算token代码
- 最早期的版本,也就是GPT-3刚出的时候,那个什么还没什么token计算,用的字符计算方法进行估算,返回的也和当时GPT-3返回的相差不大,如下,这也是本站最早使用的token计算方法
/**
* @Author hashnode
* @Description 计算字符数模拟token数
* @param input: 需要计算的输入
* @return: int
* @Date 2023/2/12 21:57
**/
public static int countTokens1(String input) {
if (StrUtil.isBlank(input)){
return 0;
}
int tokenCount = 0;
for (int i = 0; i < input.length(); i++) {
char c = input.charAt(i);
// 基于 ASCII
if (c <= 0x7F) {
tokenCount++;
}
// 基于常见的多字节 UTF-8 字符
else if (c <= 0x7FF) {
tokenCount += 2;
} else if (c <= 0xFFFF) {
tokenCount += 3;
} else if (c <= 0x10FFFF) {
tokenCount += 4;
}
}
// 除以2,以避免中文被算成两个字
return tokenCount / 2 ;
}
- 后来有了langchain4j,遂用langchain4j计算token,代码如下
public static void main(String[] args) {
String input = "如何让程序员参加社交活动?\\n\\n告诉他那里有个“Hello, World!”聚会,然后看他激动地开始调试行头。";
ChatMessage chatMessage = new AiMessage(input);
Tokenizer langChainTokenizer = new OpenAiTokenizer("gpt-4o");
int tokenCount1 = langChainTokenizer.estimateTokenCountInMessage(chatMessage);
System.out.println("langchain4j计算出来的token数:"+tokenCount1);
EncodingRegistry registry = Encodings.newDefaultEncodingRegistry();
// Get encoding for a specific model via type-safe enum
Encoding encoding = registry.getEncodingForModel(ModelType.GPT_4O);
int tokenCount2 = encoding.countTokens(input);
System.out.println("JTokkit计算出来的token数:"+tokenCount2);
System.out.println("计算字符数得到的token数:"+ countTokens1(input));
}
本站token数经历了两个阶段,第一个是计算字符数,后面升级到langchain4j,后面出了新的JTokkit,由于openai也没有开源token计算的方法,所以本站准备继续以langchain4j计算tokens,并将结果除以2,计算的token数只会比官方返回的要少,不会暗箱操作占大家便宜,可放心食用。
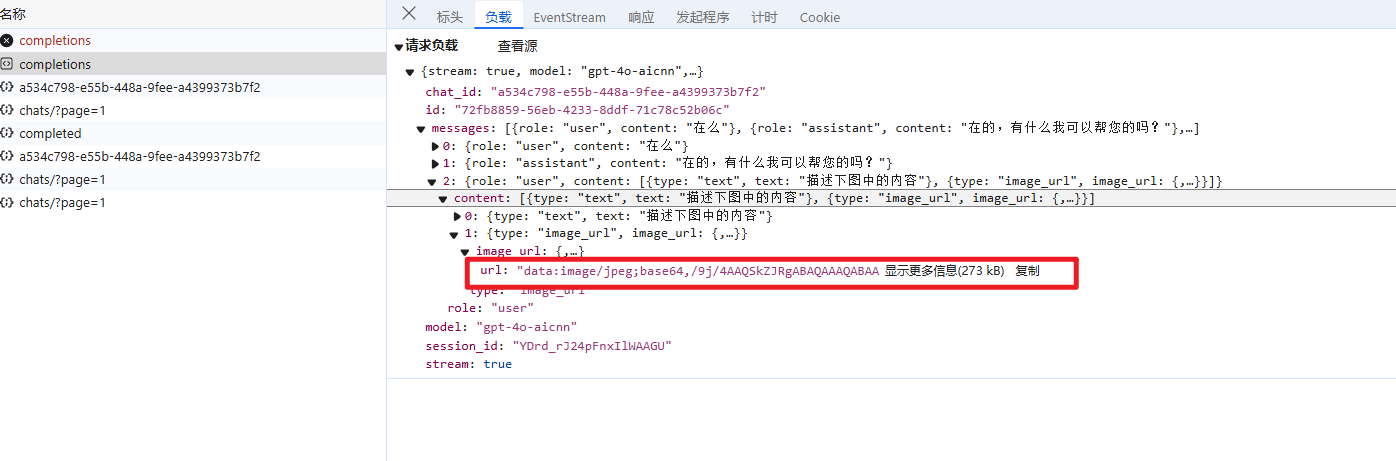
另外解释一下为什么会出现一下消耗15w的问题,本站api开发的较早,GPT-3刚出的时候,后面一直没有迭代升级,并且openai的格式也在逐渐增加新的参数(上个版本已修复),所以有些第三方客户端传递的时候将type类型为image_url的图片解析以base64放content传过来,而程序直接解析content将base64的图片解析成tokens了,导致特别多,而每个模型我们都有最大消耗,15w,也就出现了扣十五万的情况(上个版本已修复),这里如果有因为识图被误扣15w的,可以邮件联系我们加倍补偿。
最后送上3万个52000永久积分,供大家测试,现已改成langchain的方式除以2,绝对会比官方计算的tokens数要少,可放心使用。
HOPEYOUHAPPYERERYDAY
还有一个非常重要的一点,我们页面上复制的结果是markdown渲染后的结果,实际markdown字符是也是算token的,回复中有很多换行\n 加粗**,所以大家在测试的时候还是尽量用非流的api进行测试,而不是直接从页面上复制回复进行测试,在这里谢谢大家的理解和支持!
以deepseek的r1为例,计算性价比
120块,站内最多 589w积分
在deepseek中,输入4元/百万,输出16元/百万,这里以平均 (4+16)/2=10元/百万进行计算,120块,120/10 = 12 也就是说在deepseek中大概可以使用12百万的token
而在aicnn, 120块对应 589w积分,0.2积分每字
589w/0.2/0.8 = 3681.25w 也就是 36.8125百万,相当于便宜了2/3,为什么除以0.8,因为套餐内是8折
网络上重拳出击,现实中,我们可能是无话不谈的好朋友!道友,山高路远,未来可期,人生值得,我们各自努力,顶峰相见,就算世界荒芜总有一个人是你的信徒,山高路远,看世界,找自己,等苦尽甘来的那一天,山河星月都做贺礼。
