fable
1
最近在用lobechat的知识库功能,遇到向量化的问题,一开始用的是GitHub的text-embedding-3-small,但是有限额,免费用户每天只能请求150次。就想着能不能换个平台/模型。就看了一下硅基的模型,有嵌入模型BAAI/bge-m3,还是免费的,不愧是硅基大善人。
然后就看了一下lobechat的文档
(支持的模型提供商:zhipu/github/openai/bedrock/ollama)
嗯,不支持硅基流动。但是想起来硅基流动是兼容openai的api的
那也许可以,就在环境变量里添加了
DEFAULT_FILES_CONFIG=embedding_model=openai/BAAI/bge-m3
OPENAI_API_KEY=sk-XXXXXXXXXXXXXXXXXXXXXX(硅基的key)
OPENAI_PROXY_URL=https://api.siliconflow.com/v1
确实可以成功向量化,速度也比GitHub的text-embedding-3-small快得多。
就是不知道效果哪个更好。
因为我不用openai作为ai提供商,所以不知道这样写环境变量会不会对聊天用的openai造成影响。
佬友们可以参考一下。
21 个赞
差不多的,曾经一度bge登顶词嵌入; 这个你也可以自己用本地ollama做嵌入的
1 个赞
hu06
(小白)
3
我我把硅基的模型转到new-api里,也可以这样用
2 个赞
XHB111
(XHB111)
4
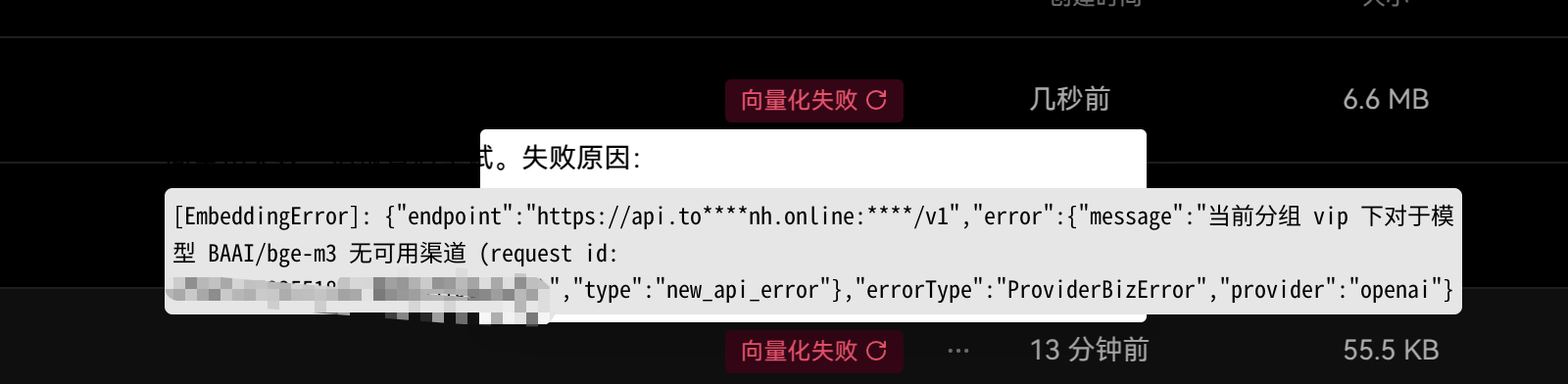
奇了怪了,同样配置向量化就失败,但硅基那边有使用日志
1 个赞
tounh
(Tounh)
7
佬,这是什么错误? @Arvin_Xu
这是我填写的
当我在知识库分块的时候,发现他的endpoint还是我new-api的base url。。。
Arvin_Xu
(Arvin Xu)
8
有点怪…这个得等后面确认下了,环境变量这个功能是社区小伙伴做的
fable
10
我刚刚测了一下,是不是在ai服务商里进行的设定会覆盖环境变量
因为我没用openai,所以没有受到影响。
尝试在openai服务商里随便写了个错误的key,然后运行向量化,失败了,提示"errorType":“InvalidProviderAPIKey”
fable
13
这里有讲不同的版本的限额,免费版有些模型不能用。
除非开到商业版或者企业版,不然免费和pro就只有模型能不能用的区别了
话说学生包带的copilot是pro版的吗
tounh
(Tounh)
16
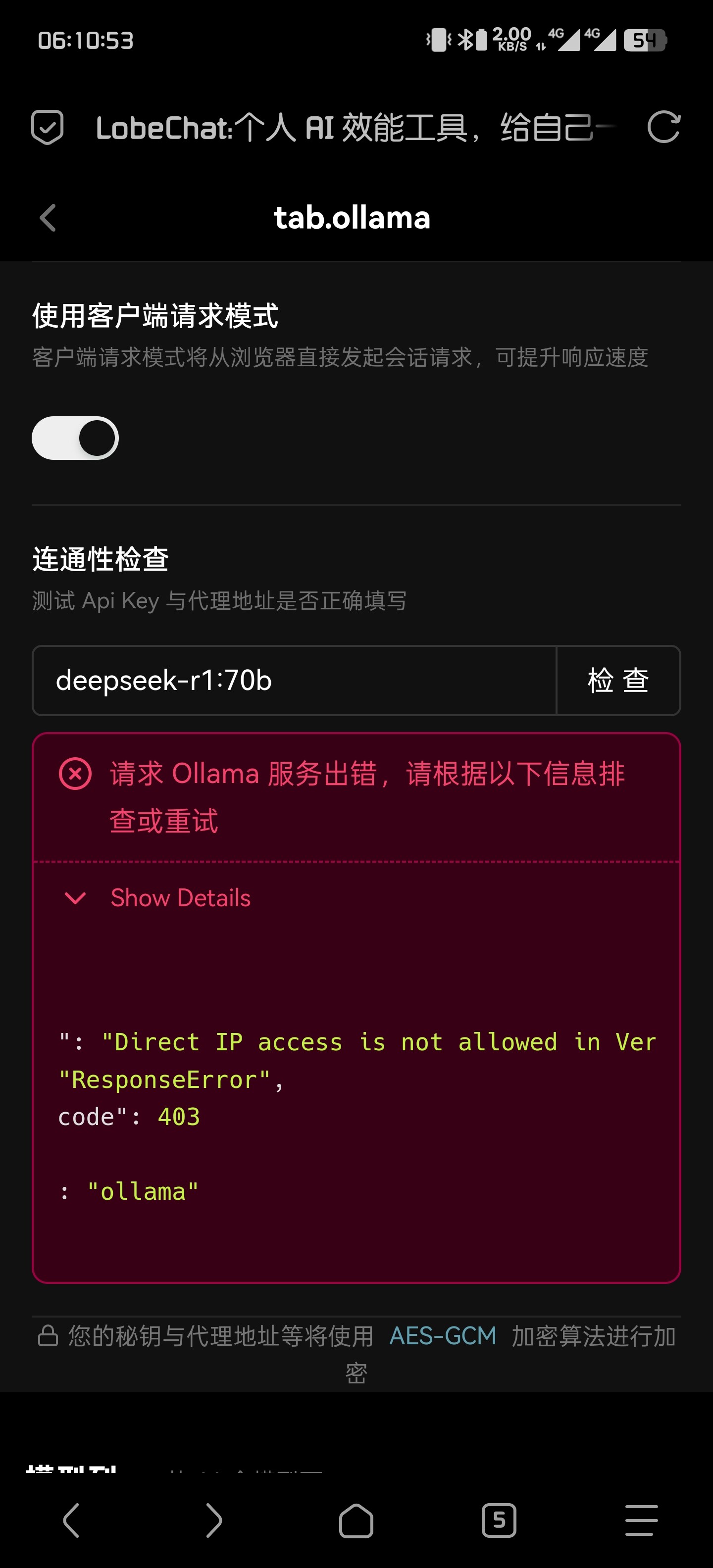
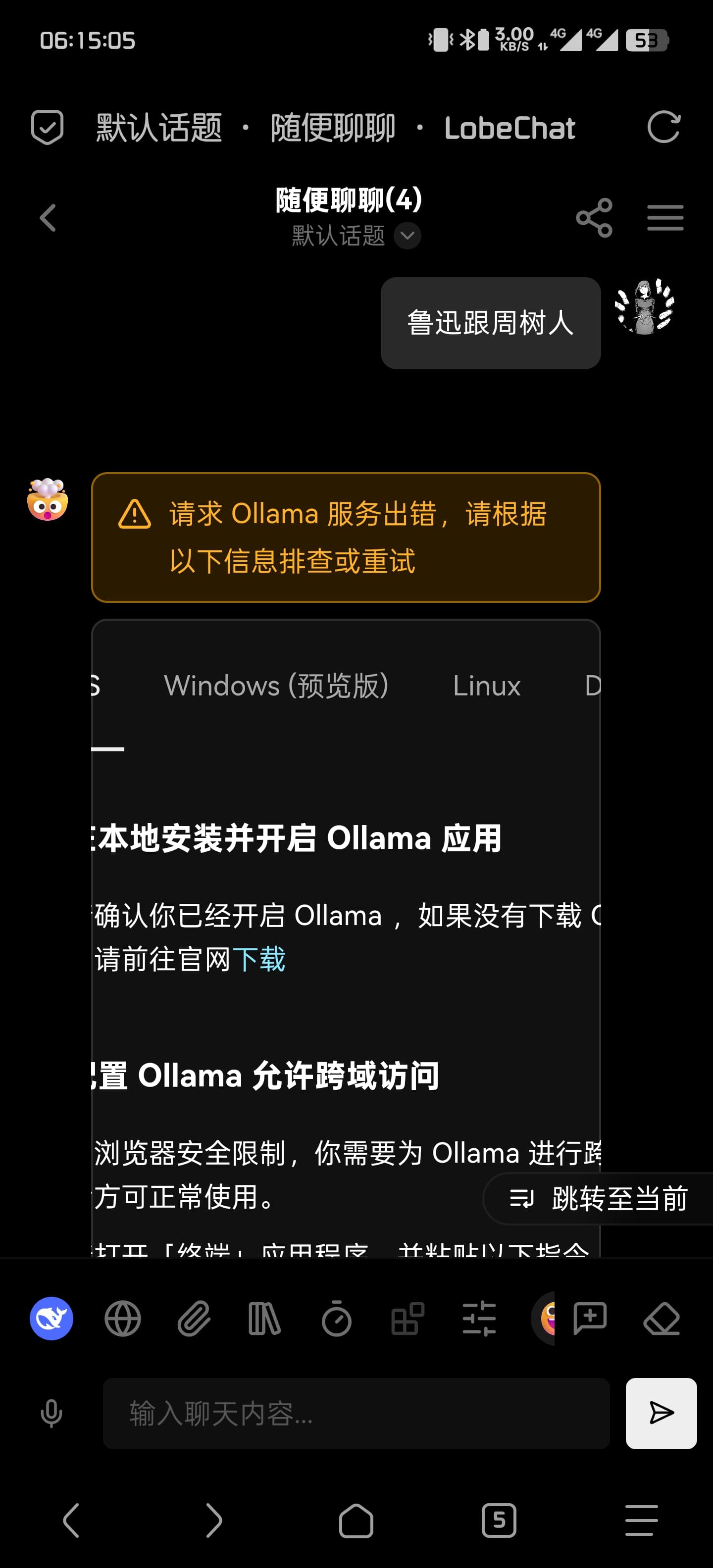
我测了ollama,openai确实都是一样的情况,只有把前端界面对应的供应商关闭,在环境变量中的embedding模型才能生效。
hutu
(糊涂)
17
佬,请教一下,你的帖子帮我解决了向量化问题已经用上了。在此之前我的open api跟key都是用的论坛佬的aicnn的,貌似它的没有默认的嵌入模型,所以一直向量化失败。通过老哥提示我把open api跟key换成硅基的之后向量化成功,但是我有没有办法调用acinn的api呢,因为楼下有佬友提到问题(前端自定义定的open api会跟环境变量的冲突,也就是说还是只能用硅基里的模型(如果想用向量化)),所以想问下佬友有没有解决方案,这边我在找下acinn有没有支持的其他嵌入模型
hutu
(糊涂)
18
或者我部署ollama的嵌入模型,然后open api继续用acinn的?
hutu
(糊涂)
19
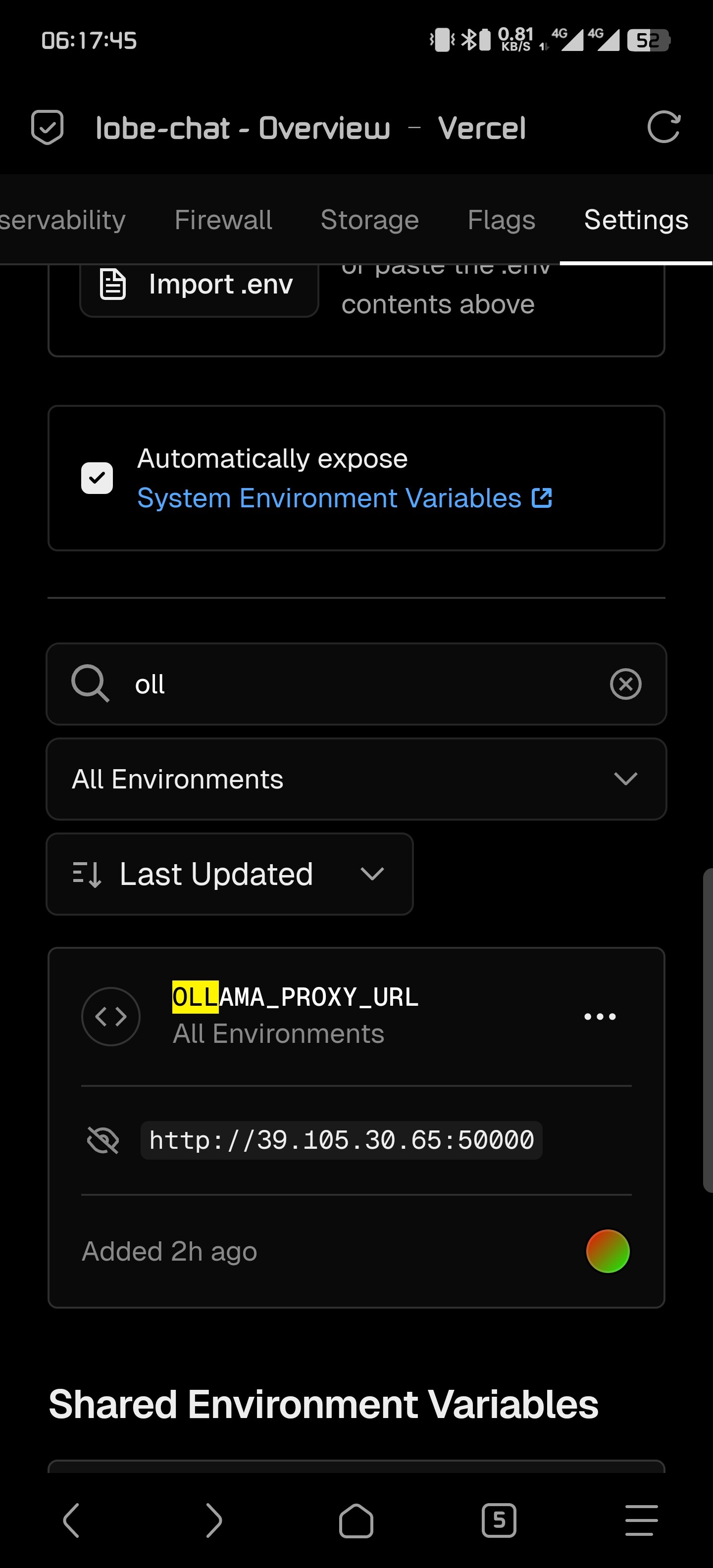
佬,发现一个问题,在环境变量中设置了ollma的url不生效,不能通过检查也不能回答问题,是不是因为只识别默认端口?前端手动输入url可以通过检测,但是模型还是不能选择接口里面的。
大佬,就是文本类的分块特别慢,向量化倒还行,这是为啥呢? 使用Vercel部署的, 是机器性能问题还是网络慢? 图片文件啥的用cf的R2都挺快