我在开发一款健身类 app
涉及很多力量训练的知识,我现在全网搜罗干货整理完了后,怎么提存把知识库投喂给 ai,我想要用 api 的方式。
后续更新维护方便一点的有什么?或者说价格便宜一点的。因为我想着基础的 ai 是要免费给用户的。
现在我想的是整体靠火山大模型。因为便宜…海外的我还没考虑好用撒…
15 个赞
一般用 RAG 实现
- 先用 embedding 嵌入模型将知识库文本向量化
- 每次请求时,通过语义搜索得到相关的知识片段
- 将这些片段作为上下文提供给 AI
具体的代码实现你可以看看 langchain 这个项目
10 个赞
- 针对不同的文档做不同解析,做文本提取
- 提取到的文本做分块
- 分块,对每个文本块做向量嵌入
补充:别用推理模型来做rag,又贵又不好用
1 个赞
求方案,这方面我妥妥的小白
不得不说看得懂但不多,明天实践一下。
看得懂,但是落到应用我直接两眼一蒙黑。有撒好的科普教的好的,我学学
参考ragflow fastgpt
大佬有没有推荐的嵌入模型
最近一直用的cherry studio自带的知识库功能 刚刚去设置发现已有的知识库不支持更换嵌入模型 之前一直用的硅基流动的免费的bge-m3
1 个赞
太棒了,有互联网大善人,可惜像我这种商用后期肯定我要换 api 付费吧,还是我搞很多个免费的 api 搞负载均衡?
首先这是个实验性模型,官方是不建议用于生产环境,但是按照你的需求,你在发布应用的时候应该已经把知识库做好了,或者说嵌入的过程是在你这边(比如服务器)完成而非在客户端完成,那么用这个没问题
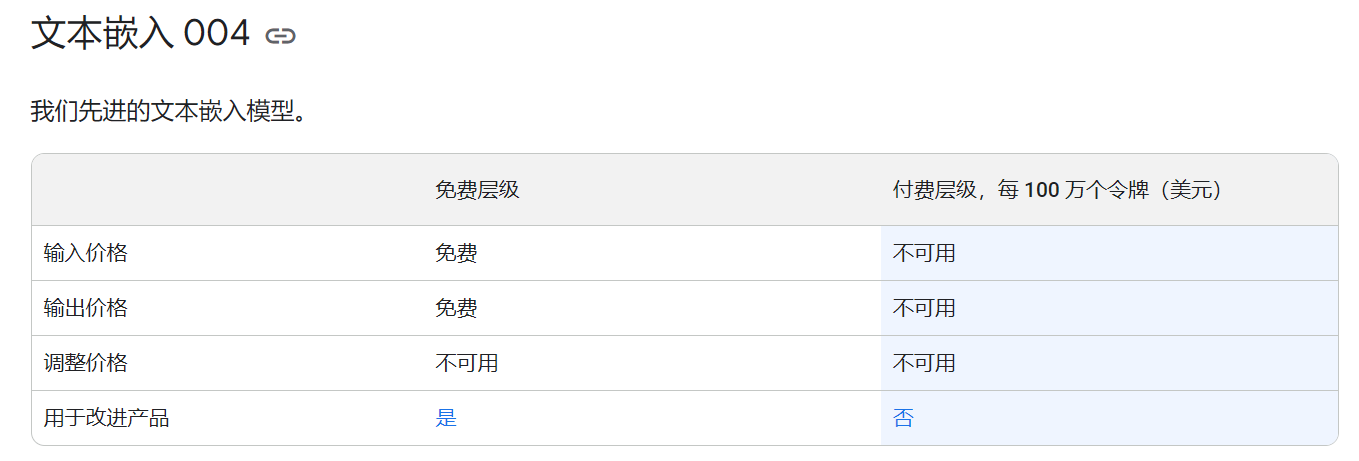
然后按照 Google 的调性,嵌入模型好像真不会收你钱,有速率限制就是了,但也不是很严,比如这是另一个 text-embedding-004 模型(不如 OpenAI 的 text-embedding-3-large)
祝佬成功!话说可以替代私教给科学安排训练项目吗? ![]()
1 个赞
那没事,我的数据库顶天500mb 应该问题不大后续扩展可能到1g。那我还能支撑免费给用户用一哈最便宜的 DeepSeekv3
每个知识库不要太复杂 ![]() 就算请求DS-V3的api接口便宜,那积少成多也都是
就算请求DS-V3的api接口便宜,那积少成多也都是![]() ~
~
1 个赞
那看来还得是我自己人工给他们分类好,再细分知识库这样才能省钱吧。可是知识库少感觉没什么意思吧?
lobechat能用gemini这个模型做向量化吗?
1 个赞
我的 app 目的就在于吃教练这口饭啊…
1 个赞
没错。假如你有100个运动、健身类的文章,不可能每次用户交互的时候都带着所有的知识库检索结果去问大模型api吧。
这中间是有很多技巧的,比如说注册用户选个性别、年龄,比如说是有氧、无氧,还可以是长期、短期,等等吧。
甚至于可以自己先把所有的知识库分个类,然后每次都先问个本地小模型,用户这个问题应该属于哪个知识库分类啊?
然后根据这个结果再去检索相应的知识库,最终去调大模型api生成一个让人满意的结果。
总之现在的模型还没做到AGI,作为一个APP的开发者佬你得有自己的思路,不可能每次用户输入什么,就直接转给大模型什么,这样是无法满足产品需求的。
2 个赞