do2
(疯狂驴驴)
1
接前文:🚀部署了一个 Llama3 欢迎大家来玩!【Meta 最新 Llama 3 8B 和 70B模型 】
和前文:🚀内置回复中文规则的Llama3 70B 模型 欢迎大家继续来体验!
及前文:🚀 来自 联通的Llama3 8B 模型,大家可以继续来尝试
在线体验: Llama3 [王慎执] 版
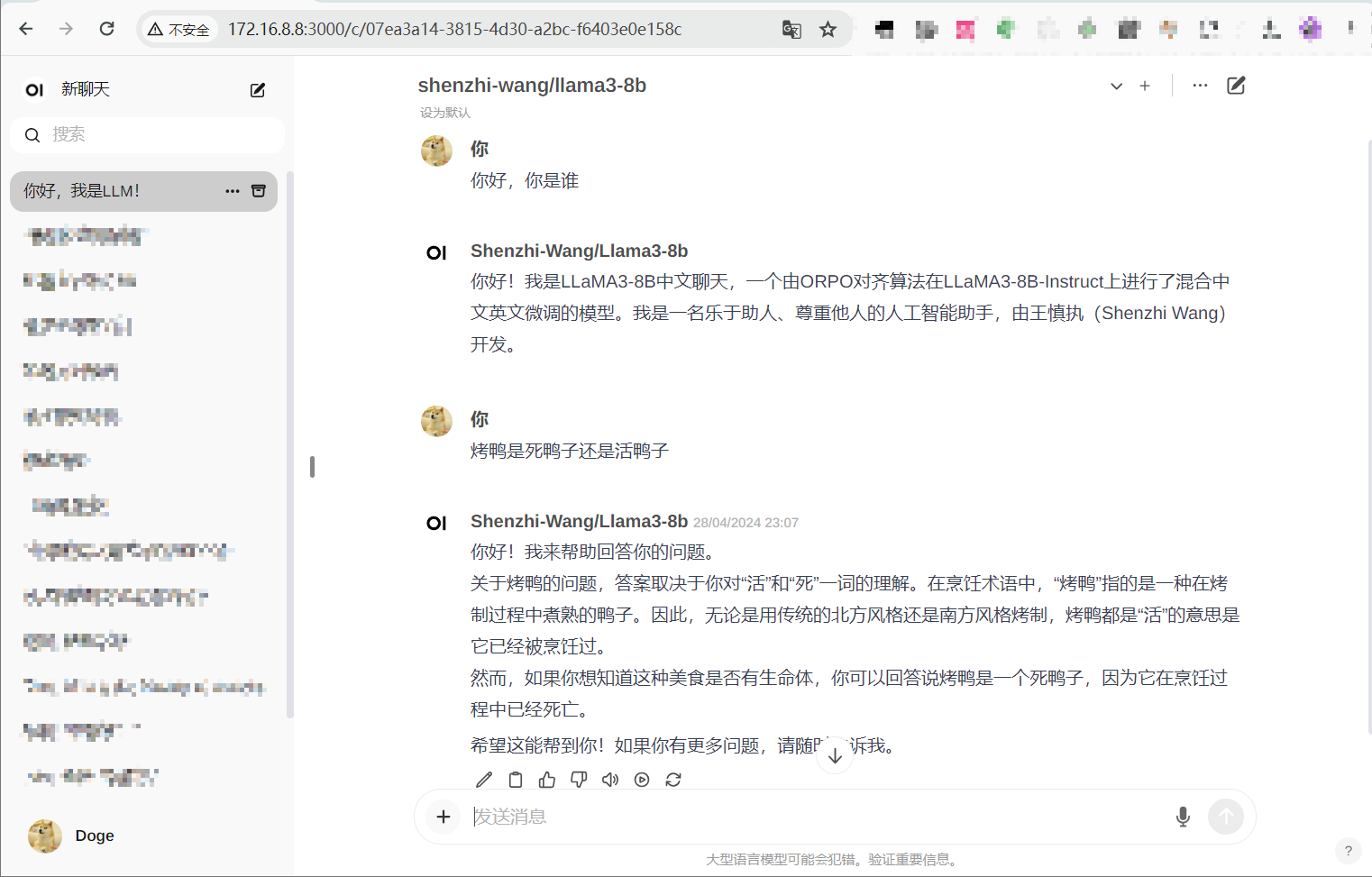
这次 我部署了 来自清华博士王慎执通过 ORPO 微调的Llama3-8B 模型
作者在分发在Ollama社区的版本,在wangshenzhi/llama3-8b-chinese-chat-ollama-fp16模型配置文件内置了他本人相关的信息,所以有标题上的名字
感觉还错,在我喜欢的弱智吧类似问题烤鸭是死鸭子还是活鸭子问题上回答的还挺好
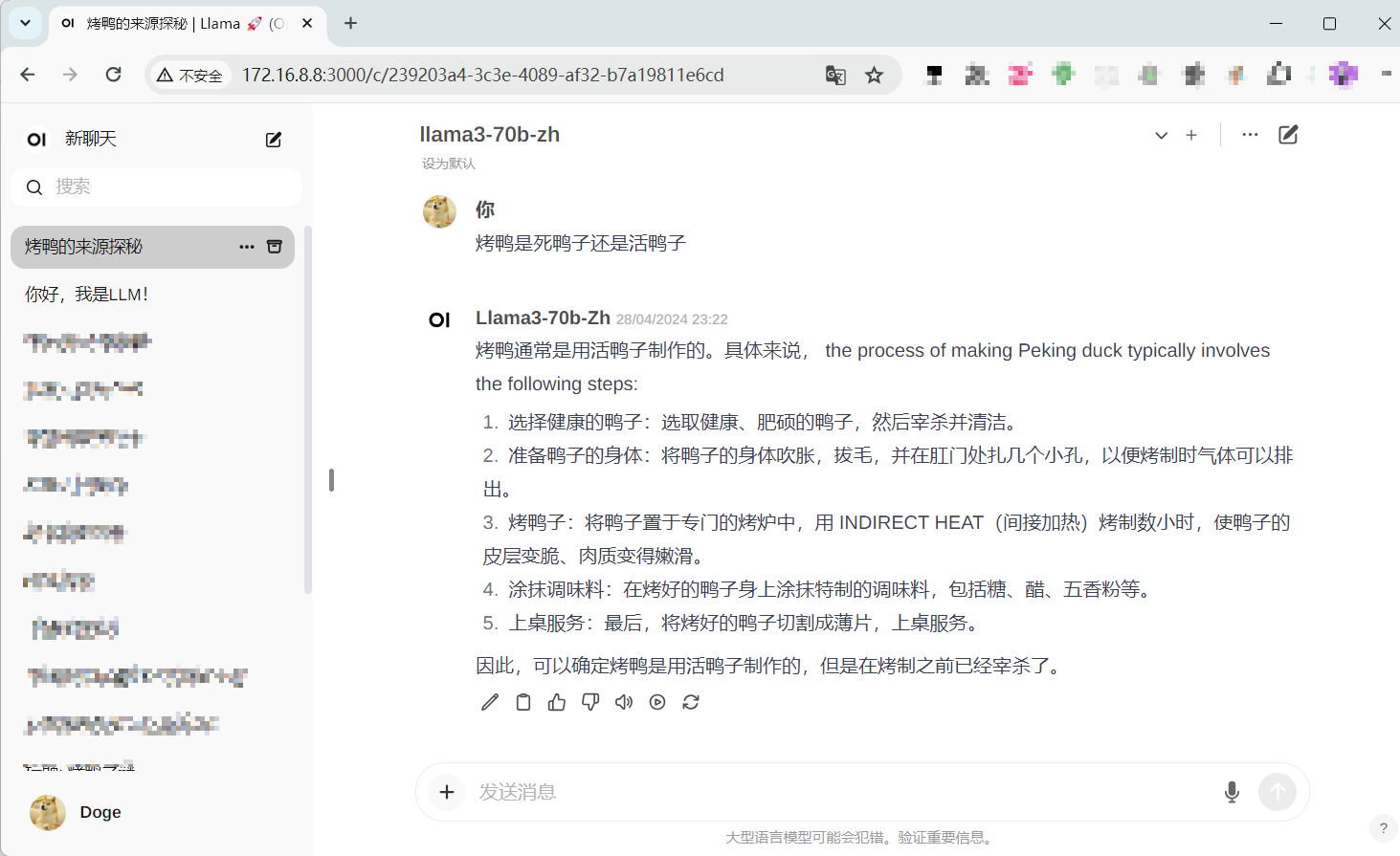
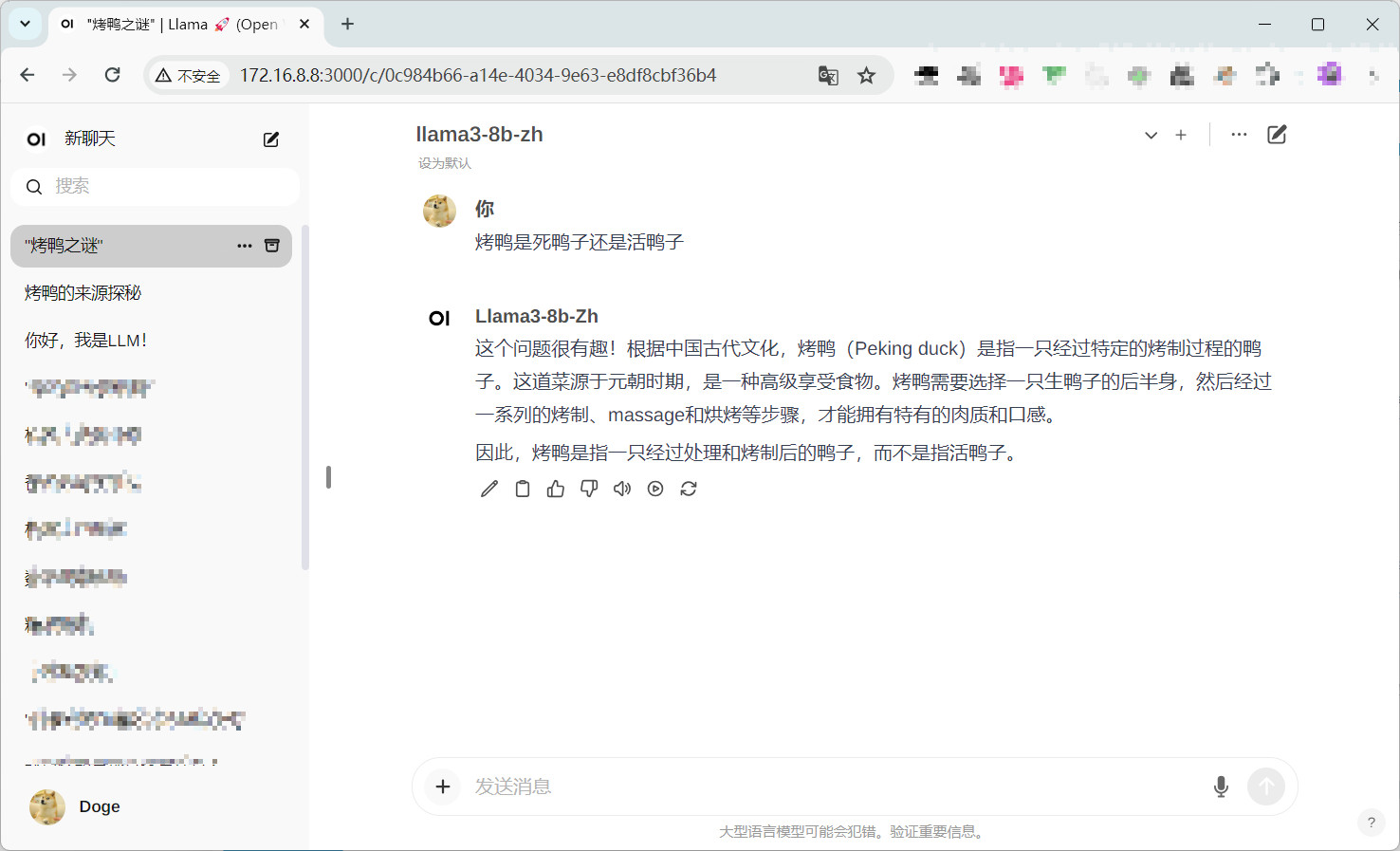
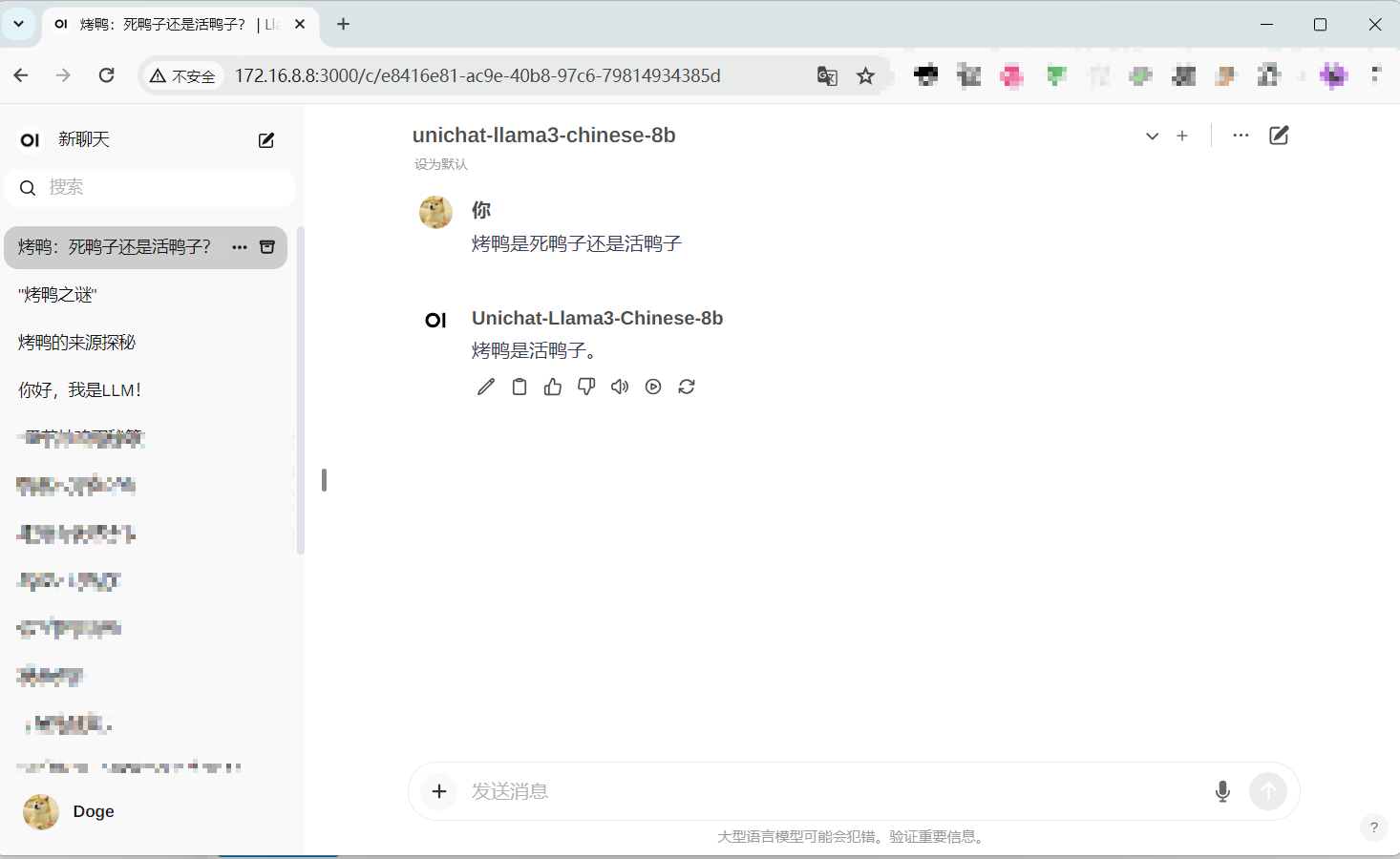
下面是其他模型的回答:
LLama3 70B
LLama3 8B
联通版 8B
另外在 HuggingFace 上还看到了Llama3 视觉相关相关的模型BAAI/Bunny-Llama-3-8B-V 、xtuner/llava-llama-3-8b-v1,但是比较遗憾的是,似乎当下流行的 llama-cpp-python、llama.cpp 并不支持它(也可能是我配置不对),ollama 暂时不支持 OpenAI API兼容的视觉接口。 而对于vllm 很遗憾,他对CUDA 版本要求11.8+ 暂时用不上了。
目前所有的模型都是使用ollama 部署的,并且用 PM2 和 pm2-webui管理, 相比较supervisor发现PM2感觉很好用 很是推荐
33 个赞
xneo
8
换了这个可以了,这个前端 UI也是开源的吗,挺好看的
5 个赞
do2
(疯狂驴驴)
9
ollama 4-bit量化版 大概40G权重占40G 显存,但是 如 llama.cpp \ ollama 应该是可以用 CPU 推理,vllm 据说也能减少显存占用
5 个赞
do2
(疯狂驴驴)
10
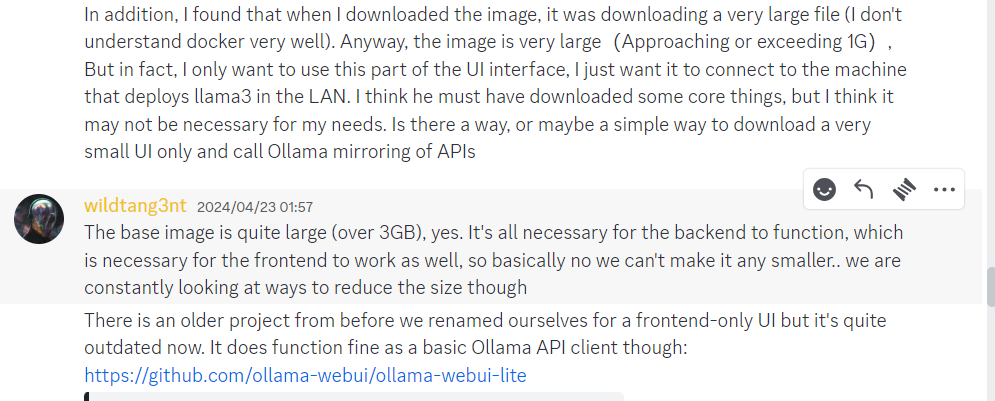
open-webui/open-webui 但是我不建议用这个,原因如下:
简而言之,镜像很大,很难下
6 个赞
反应速度是很快,部分功能实测确实和GPT3.5差不多。。。。。。
5 个赞
cursor
(cursor)
15
佬,简单理解,是通过开源ui展示,ollama一键部署就可以吗
4 个赞
用了十年的老电脑8g内存,装了3个模型试了一下,llama3卡,另外两个没问题。
herald/phi3-128k:latest
wizardlm2:7b
wangshenzhi/llama3-8b-chinese-chat-ollama-q8:latest
6 个赞
do2
(疯狂驴驴)
18
可以这么理解,但是具体没那么简单
最底层网络连接部分我用了wireguard 把部署模型的机器(A)和机器(B)进行了组网
机器B安装了docker,部署了UI,OneAPI,cf tunnel,OneAPI是因为多个单一的模型API不太好管理用这样的网关比较方便,cftunnel绑定域名比较方便(不过比较慢)
机器A,就是部署ollama的机器了,因为ollama默认的接口是没有任何认证的,所以组网还是有必要的。可以通过开启多个ollama服务的形式运行多个模型,同时把所有的模型都加载到显存里。多个ollama服务我都是写的shell脚本用pm2管理
在oneapi那每一个olama服务接口只提供一个模型的服务,这样避免ollama不停加载模型。
8 个赞