最近关注到微软开源了一个项目GraphRag,将知识图谱和Rag结合,具体可以看GitHub:microsoft/graphrag: A modular graph-based Retrieval-Augmented Generation (RAG) system (github.com)
首先安装部署,使用最简单的pip install 安装,详细过程参考官方文档,讲的也是比较清楚的。Get Started (microsoft.github.io)注意输入的txt编码需要和配置文件中对应,一般是utf-8,不然会报错。论坛里面也有大佬已经做过分享,这部分就不再赘述。要是想要图谱可视化,需要把配置文件后面三个选项开启:
snapshots:
graphml: true
raw_entities: true
top_level_nodes: true
接下来就是体验,这次用来测试的是耳熟能详的科幻小说《三体》,用的是第一部,总共约20万字。

由于这玩意儿比较费钱,建立索引阶段只用了gpt-4o-mini来抽取实体关系。
chat_model: gpt-4o-mini
embedding_model: text-embedding-3-large
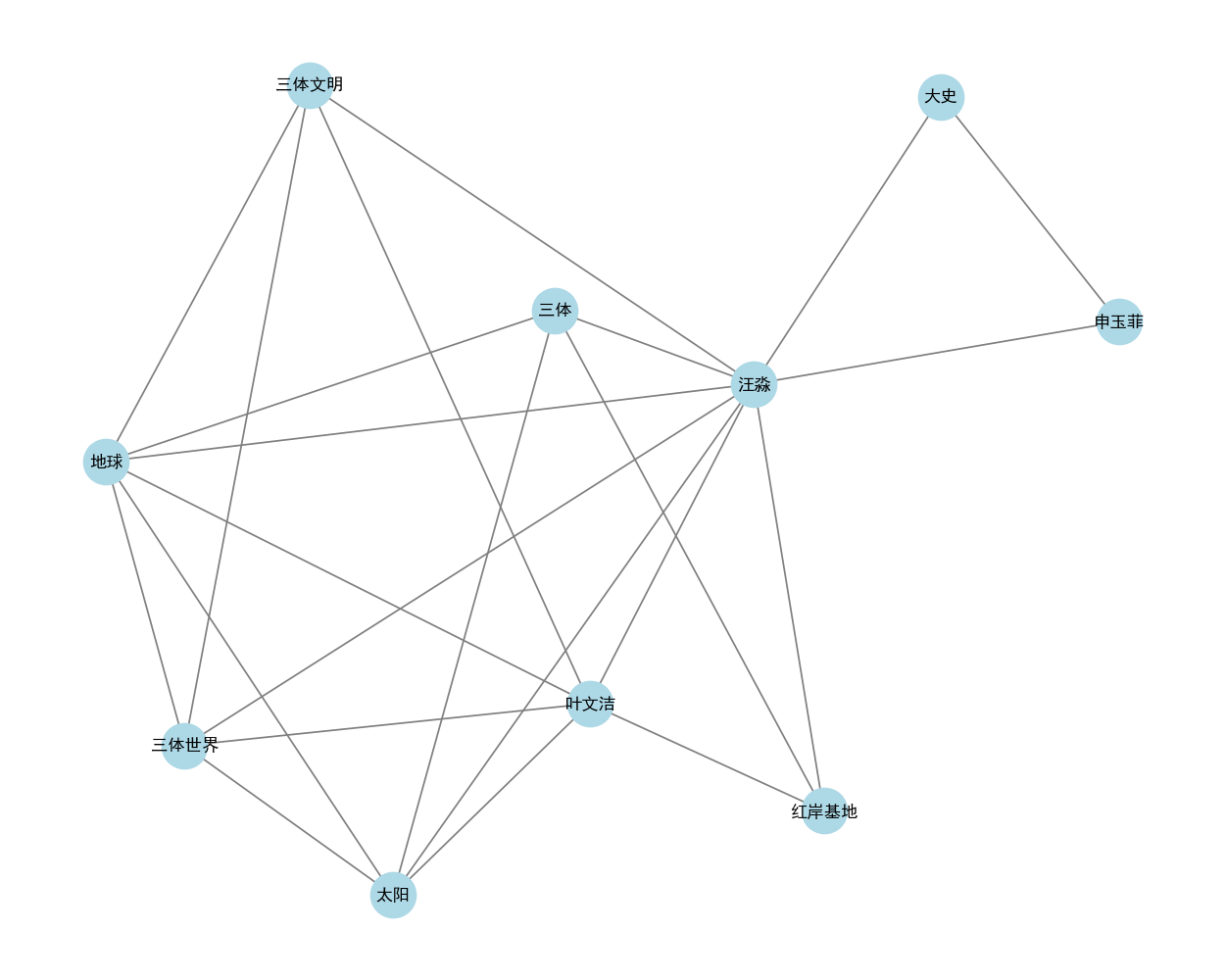
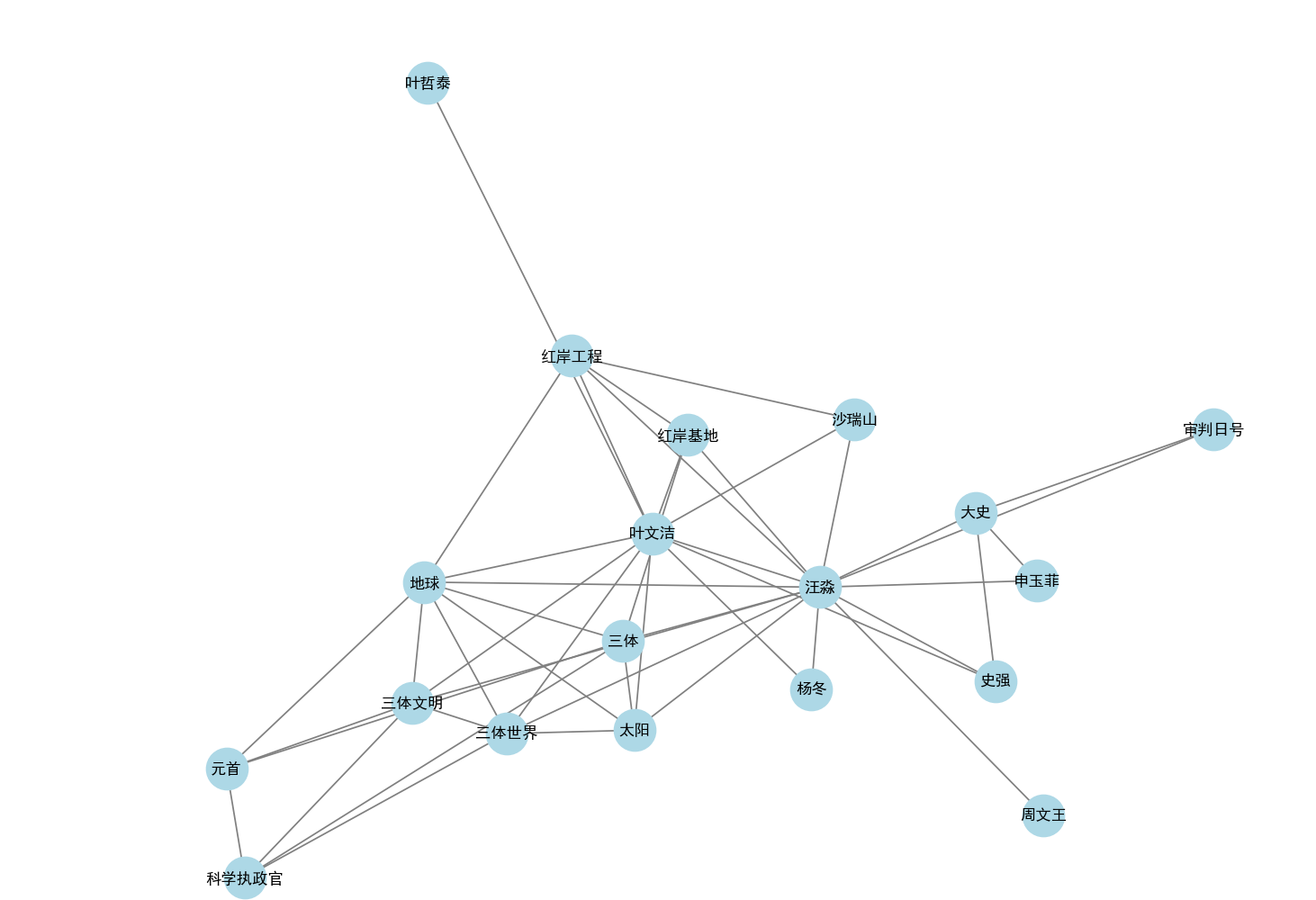
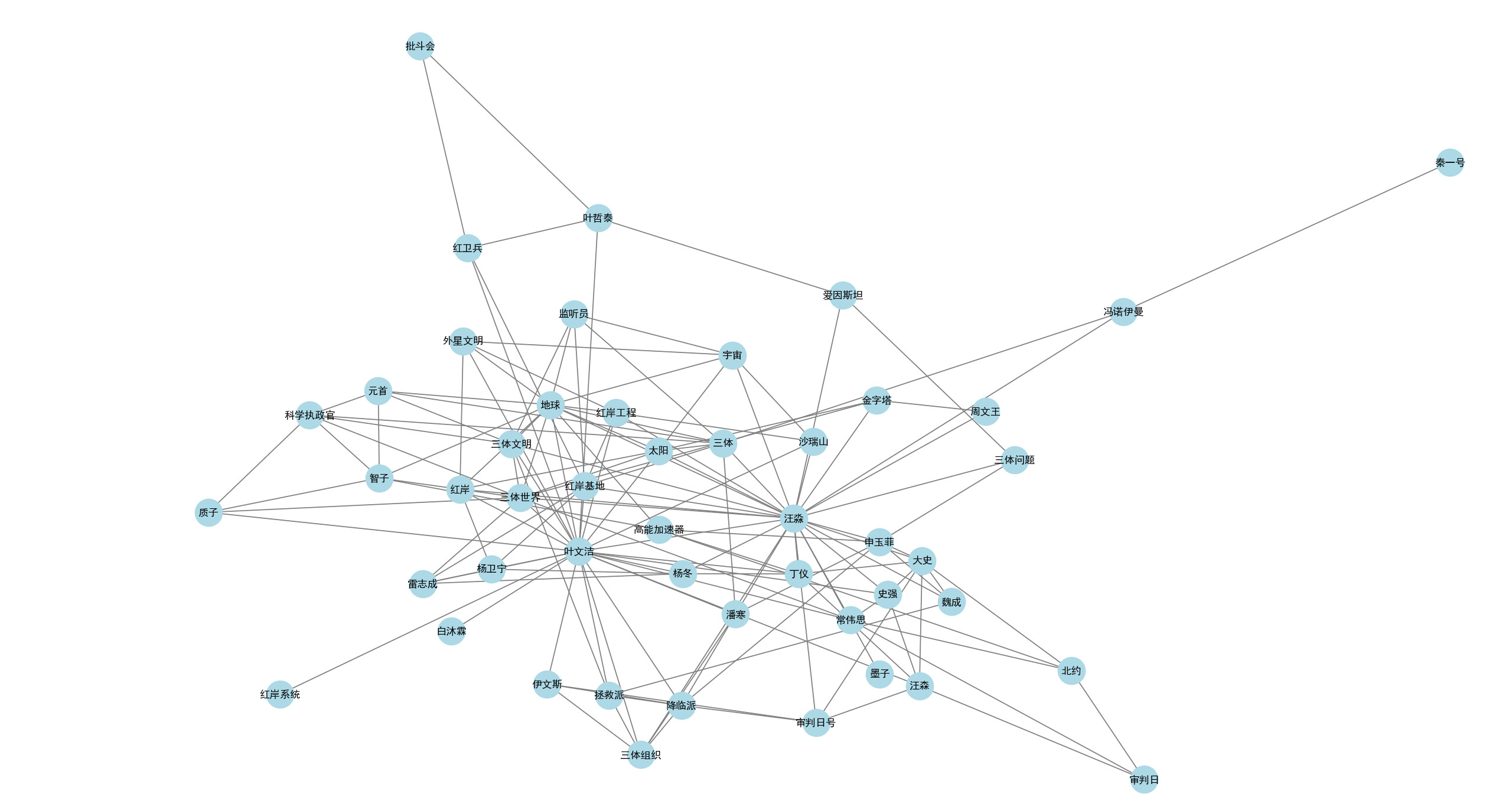
经过几分钟的等待,索引建立完成了。可以先看看实体抽取的情况,专业一点可以neo4j去进行展示分析。我这里偷个懒,直接用Python绘图。
top10的实体:
top20的实体:
top50的实体
所有的实体:
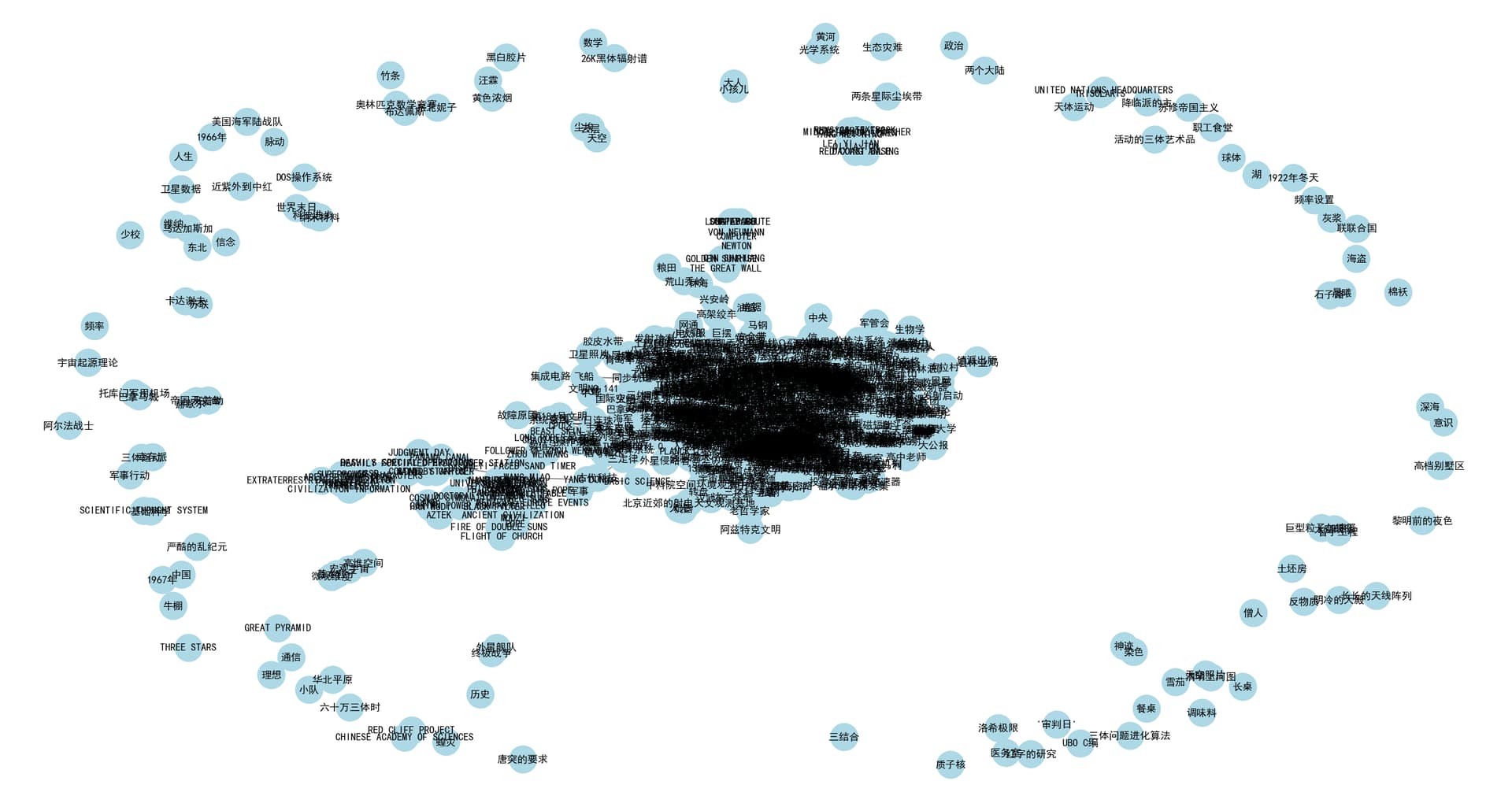
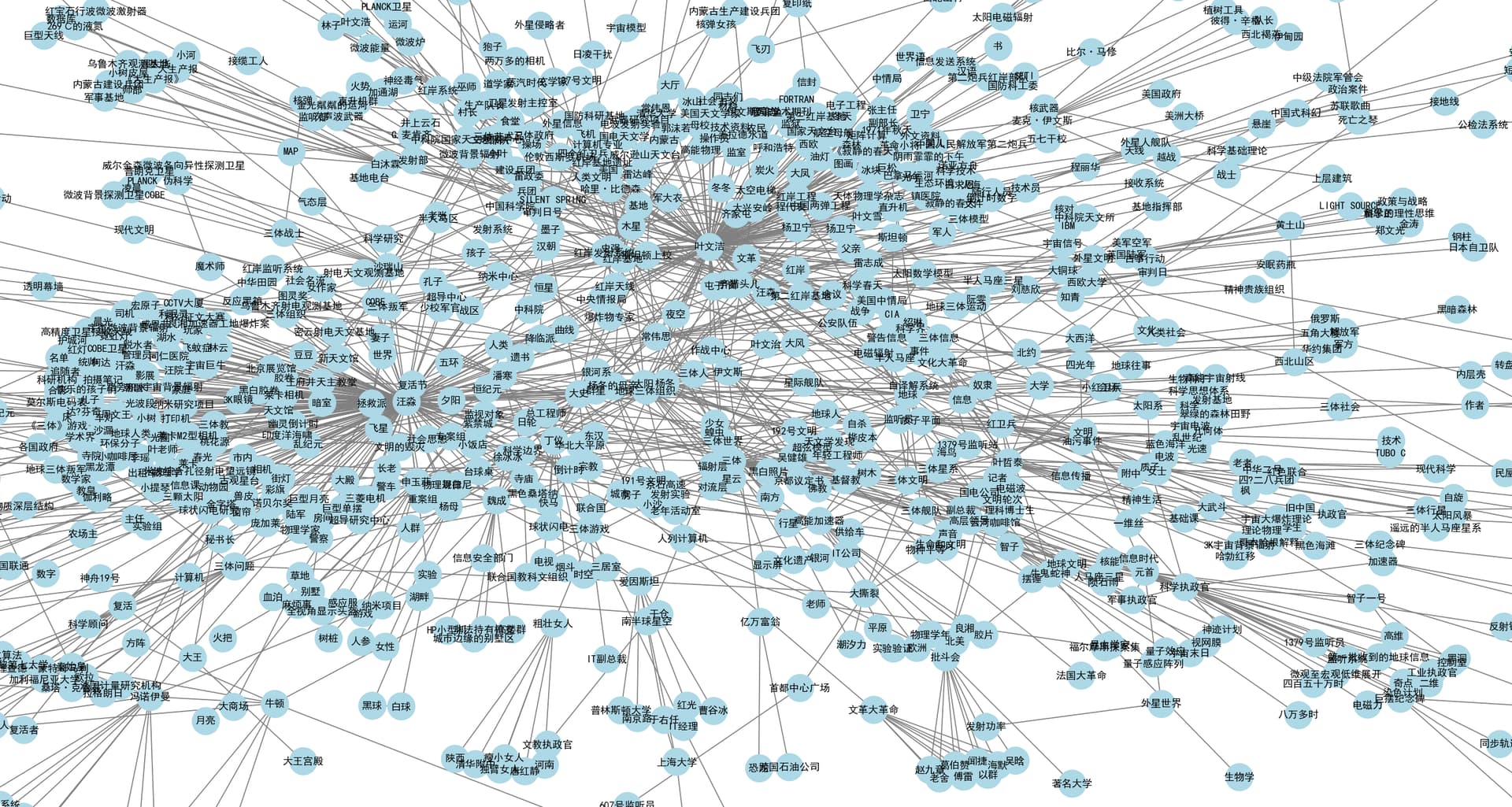
可以看出其中很多实体的关系过于冗余,一般情况下要有一些实体对齐过程。比如史强和大史应该是同一个实体。
想具体看里面关系还是用neo4j进行可视化比较好。
提问测试:
回归主题:为什么物理学不存在了?
首先使用局部搜索:

进行全局检索:

可以发现这时候全局检索会比局部检索效果好那么一些。
再问一问主角经历:


还有其他一些问题,就不一一展示了。
感觉还行,但是差点意思。PS:在提问阶段,我把模型换成gpt-4o了。
对于这种长文本理解,我们用kimi的官网试试:
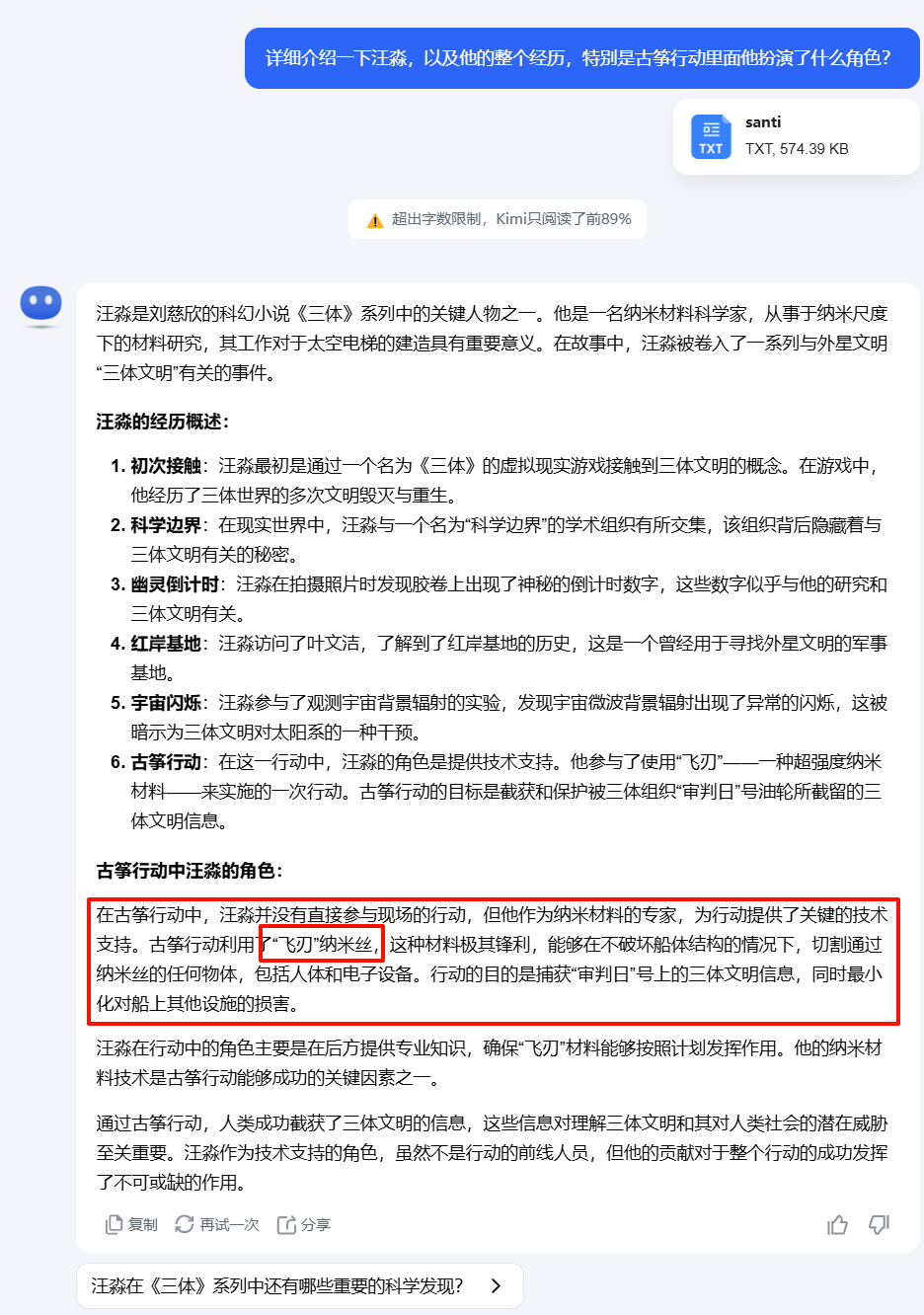
不得不说,kimi的长文本理解确实更丝滑一下。
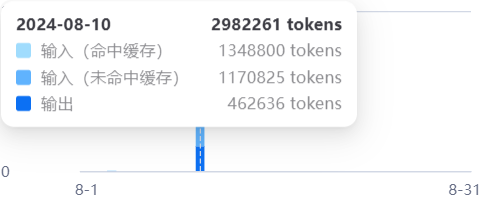
Tokens消耗方面,一路用下来,
索引阶段,花了大概3M-4M tokens
提问阶段基本上是一次提问输入10k-15k的Tokens
还是挺费的,并且抽取实体关系阶段对模型的要求也挺高,不然就瞎抽,当然我是用的提示词是官方默认的。如果可以根据应用领域进行提示词微调,效果可能会好一些。