Carlxlx
(Carlxlx)
1
直接放主流模型的幻觉数据,来源自HHEM(Vectara公司发布的AI幻觉测试,迄今为止最具权威)
- OpenAI
- GPT-4o:1.5%
- o1-mini:1.4%
- o1:2.4%
- o3-mini-high-reasoning:0.8%
- Google
- Gemini-2.0-Flash-Exp:1.3%
- Gemini-2.0-Flash-Thinking-Exp:1.8%
- Gemini-2.0-Pro-Exp:0.8%
- Anthropic
- Deepseek
- DeepSeek-V3:3.9%
- DeepSeek-R1: 14.3%
GitHub - vectara/hallucination-leaderboard: Leaderboard Comparing LLM Performance at Producing Hallucinations when Summarizing Short Documents
14.3% 啊各位,什么概念?都是人家gemini十几倍了,别人都5%以下,超过两位数的就他一个是还没淘汰的,剩下的都已经快进博物馆了
Deepseek-R1的幻觉实在高的离谱,已经到了独一无二的地步了。如此高的幻觉率,必然导致他会胡编乱造,信口开河的给你编东西,眼都不带眨的
我周围已经有人吃过这个亏了,用Deepseek-R1去问论文的细节问题,结果他真的给你现场编,编完流程编数据,就差给你现场创作一篇SCI了
如果你对AI输出的真实性要求非常高,比如论文相关内容,一定要慎重使用它,用的时候要仔细检查,或者同一个问题反反复复多问几遍,总之就是小心他的高幻觉
如果你看到这害怕了,不敢用了,想换成Deepseek-V3也是可以的。我实际测试下来,V3相当于GPT-4o的升级版,如果对模型性能要求不高的话,V3已经足够日常使用了
事实上Deepseek-R1已经在很多地方造成不良影响了,比如这篇知乎文章就提到了相关问题
https://zhuanlan.zhihu.com/p/28284660804
总之,我就提醒到这。希望能对各位有所帮助。如果有类似情况也可以发发评论,让大家伙见识见识
92 个赞
tounh
(Tounh)
4
我们老板吃过R1的亏,就是被硬编,其实其他模型使用下来也有同样的情况,如果什么都不懂,不如百度。。。
5 个赞
非常同意。
r1 胡编乱造的的问题我是在使用中发现的,有些数据我了然于胸,它尽然搞出好几个不知来源的。当然,也要承认 r1 的思考方向还是很不错的。
至于为什么会幻觉,估计是与训练 CoT 的机制有关吧。
7 个赞
23375
(QQbot)
8
deepseek在某些方面省的钱确实会在另外的方面还回去了,OpenAI虽然坏,但是基底模型还是有认真做对齐的
7 个赞
是不是因为官网把温度调太高了,用API的话把温度调成0会这样吗
1 个赞
Creasys
(阳光彩虹小白马)
10
如果ai是你的同事,那么他就是一个任劳任怨,不知疲倦,善于收集整理资料,同时又特别自信爱吹牛的实习生,你既需要引导他,也需要检查他的工作,他犯的错需要你来背锅。
15 个赞
前段时间写论文发现了  他给我扩写了一堆原文里没有的
他给我扩写了一堆原文里没有的
4 个赞
GaoYu
(无问西东)
14
生成内容方面还是GPT强点,起码让他干什么他就干什么
2 个赞
Fii
(NeoFii)
17
同感 指令遵循貌似还需要调教 我让他给我把一段内容转成md 不要在聊天页面渲染 最后一半给渲染了
2 个赞
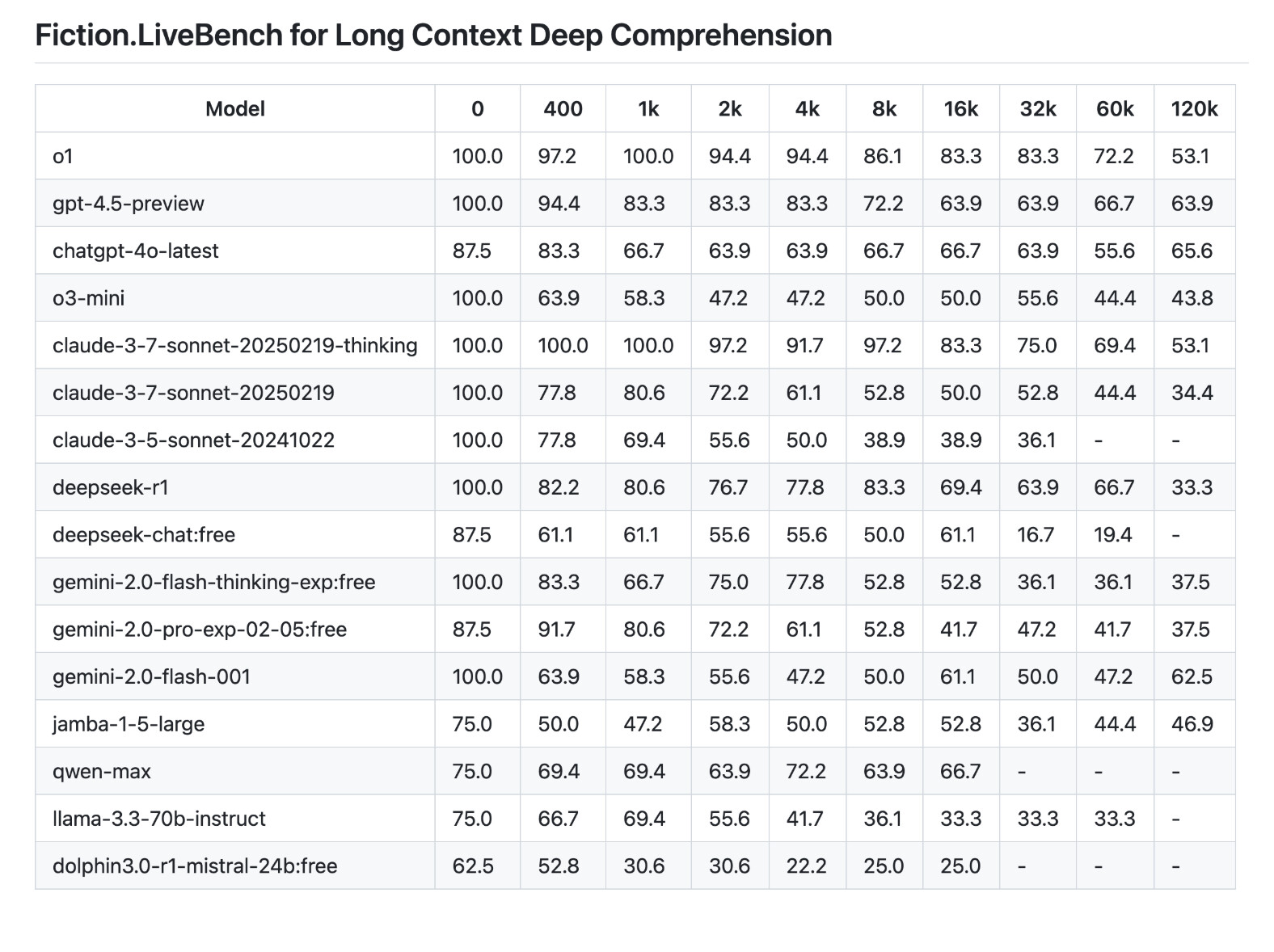
其实你还漏了一组数据:deepseek在长context下的表现出乎意料的差,在极限长度下表现甚至不如gpt4o
10 个赞
没用,我用火山的API,在cherrystudio里把温度调整成0,让他帮我翻译文献,给我整一堆不存在的数据和内容,我真是要被气死了
2 个赞