xiniah
2024 年11 月 21 日 09:55
1
任务模型是指openwebui中进行标题标签生成的模型。在设置的界面中的外部模型中设置
去看 newapi 后台首字也才零点几秒,也没有出现渠道重试。然后又去渠道提供商那里看,也是首字时间很低。
接下来就是漫漫的 DEBUG 之旅…
1. 网络
首先看浏览器的开发者工具发现 **/completions** 的请求等待时间极长
然后用 curl 测试了以下几个内容
本地 -> 服务器 0.5s
服务器 -> 供应商 0.5s
本地 - > 供应商 0.5s
都没出现问题… 说明不是网络出现的问题
2. 日志
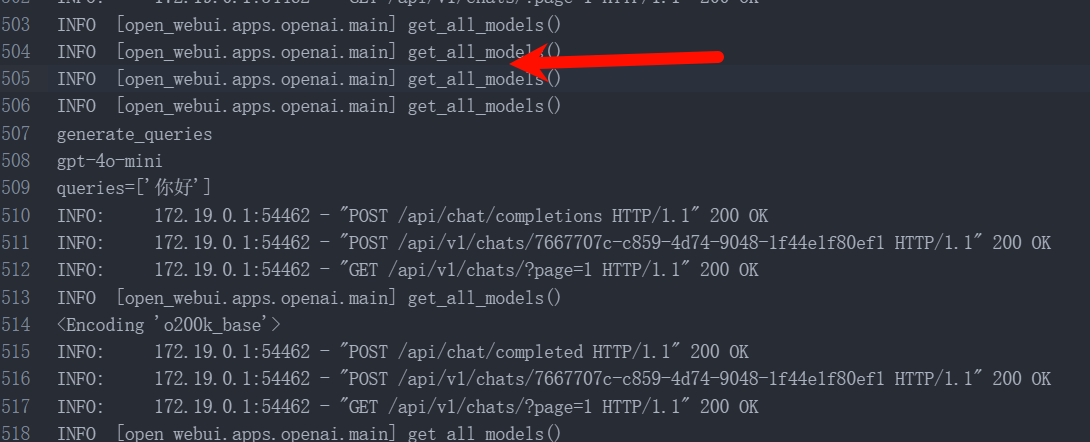
通过 1panel 的容器日志查看,我观察了生成对话时日志的反应,发现在发送对话请求后,日志会在这里卡一会(下图的红色箭头)
难道是获取模型时比较慢?
3. 搜索
在翻遍了论坛,GitHub 的 issues 以及各种搜索引擎后,都没有关于此的明显的答案
决心还是要靠自己解决。
4. 于回顾中发现
在回看这段折腾过程中,newapi 的日志又引起了我的注意
任务模型调用 gpt-4o-mini 在正常情况下是会被忽视的,但这一次,他的响应时间却引起了我的兴趣10s ,这与 ow 的响应时间是巧合吗?
我在 newapi 中重新调整了 gpt-4o-mini 模型所对应的第一响应渠道,将其重新调回正常的 1s 水平。
** 再次测试 OpenWebUI 时,就已经回归正常 **
5. 反思
可见,OpenWebUI 的响应速度与任务模型也有关 (在界面的设置中,我设置的是 gpt-4o-mini)
由于之前使用过 lobechat 等其他的 webui,也就自然的以为这些关于生成标题与标签的任务是异步的请求
建议佬友们在使用 openwebui 的时候保证外部模型的稳定性,追求速度可以换成更快速的模型.
果然还是应了那句话
时间就是金钱,稳定压倒一切
如果稳定的话,也没了这次折腾了… 是吧
解决方案:
153 个赞
nob
2024 年11 月 21 日 10:21
3
openwebui怎么看响应时间跟token?哪里设置?
1 个赞
ageg
2024 年11 月 21 日 11:07
6
oi的定义,内部模型是指本地跑的模型,调openai api的是外部模型。chatgpt-4o-latest 是外部模型。你说chatgpt的速度和外部模型有关,我看不太懂了。看了三遍才看懂原来外部模型指的是4omini。你直接说生成标题的模型就好了,或者叫任务模型
已打开 10:33AM - 21 Nov 24 UTC
已关闭 03:42PM - 21 Nov 24 UTC
I noticed that OPENWEBUI takes 2-4 seconds longer to load chats.
By looking a… t the logs, the problem is clear, before every chat OPENWEBUI calls
`get_all_models()`
I have fixed this issue by adding the environment variables:
**backend/open_webui/config.py**
Line 533:
```
ALL_MODELS_CACHE_TTL = "1800"
OPENAI_MODELS_CACHE_TTL = "1800"
OLLAMA_MODELS_CACHE_TTL = "1800"
```
These are imported into the following files:
**backend/open_webui/apps/main.py**
Line 1007:
```
@cached(ttl=MODELS_CACHE_TTL) # Cache variable to control get_all_models()
async def get_all_models():
```
**backend/open_webui/apps/ollama/main.py**
Line 260:
```
@cached(ttl=OLLAMA_MODELS_CACHE_TTL)
async def get_all_models():
```
**backend/open_webui/apps/openai/main.py**
Line 372:
```
@cached(ttl=OPENAI_MODELS_CACHE_TTL)
async def get_all_models() -> dict[str, list]:
```
Obviously importing **from aiocache import cached** to each file, and adding the corresponding environment variable to **from open_webui.config import (**
31 个赞
xiniah
2024 年11 月 21 日 11:25
7
好的,我改一下标题。原谅我不怎么理解外部模型与内部模型的区别。感谢佬的回答
1 个赞
The.one
2024 年11 月 21 日 11:40
9
mini 响应慢的很可能是逆向,或者中转了n次的供应商
xiniah
2024 年11 月 21 日 11:51
10
我用的是中转,现在我把gpt-4o-mini切到正价渠道了,稳多了…
obrook
2024 年11 月 21 日 12:35
12
4.0版本后之后就每次回复就迟钝几秒,没有3.5顺畅
除了issue,Discussions中搜response,也有人提出了这个问题,也是改ttl
默认是1,我改成10,也并没有改善。改成1800没试过
ageg
2024 年11 月 21 日 12:38
13
我改成1800了,也不行,还是等官方修复吧。这个bug真蛋疼
obrook
2024 年11 月 21 日 12:40
14
对,GitHub有个open webui 的maintainer 回复了那个问题。感觉官方也是知道和承认这个问题的,只是还没找到原因
1 个赞
obrook
2024 年11 月 21 日 12:43
15
我还发现了个环境变量的问题,之前我用0.35没有这个问题。也可能是我网络配置的问题,我是部署在本地
fl0w1nd
2024 年11 月 21 日 16:34
16
似乎已经在v0.4.4修复,不用关了
终于有人问到这个问题了,我来解答吧
前往管理员设置->界面设置部分,将其中的“启用检索查询生成”给关掉就可以
原因:这是新版本(0.4.0开始)增加的一个新的任务模型的任务,它会在每次聊天请求之前先执行这个任务,等这个任务完成了之后才开始发送你的聊天请求。
个人认为这就是潜在的BUG,在聊天请求之前预先执行任务模型本就不可靠,会严重影响体验,建议大家关了。
另外,这个功能具体干什么的我也不太清楚,但是我给下大家oui源码里的这个任务模型功能提示词,有大佬知道的可以说说:
### Task:
Based on the chat history, determine whether a search is necessary, and if so, generate a 1-3 broad search queries to retrieve comprehensive and updated information. If no search is required, return an empty list.
### Guidelines:
- Respond exclusively with a JSON object.
- If a search query is needed, return an object like: { "queries": ["query1", "query2"] } where each query is distinct and concise.
- If no search query is necessary, output should be: { "queries": [] }
- Default to suggesting a search query to ensure accurate and updated information, unless it is definitively clear no search is required.
- Be concise, focusing strictly on composing search queries with no additional commentary or text.
- When in doubt, prefer to suggest a search for comprehensiveness.
- Today's date is: {{CURRENT_DATE}}
### Output:
JSON format: {
"queries": ["query1", "query2"]
}
### Chat History:
<chat_history>
{{MESSAGES:END:6}}
</chat_history>
9 个赞
bbb
2024 年11 月 21 日 18:40
18
之前的版本也会有这个问题吗?还是说0.4新出现的问题?
1 个赞
感谢,一会去设置看看,之前也是觉得更新完毕后慢了一些
ageg
2024 年11 月 22 日 03:12
20
可以的。果然正常了